声明 本文代码均保存在https://github.com/super-213/business_data_analysis
查看数据 1 2 df = pd.read_excel('产品定价模型.xlsx' )df.head()
页数
类别
彩印
纸张
价格
207
技术类
0
双胶纸
60
210
技术类
0
双胶纸
62
206
技术类
0
双胶纸
62
218
技术类
0
双胶纸
64
209
技术类
0
双胶纸
60
缺失值处理
字段
缺失值数量
页数
0
类别
0
彩印
0
纸张
0
价格
0
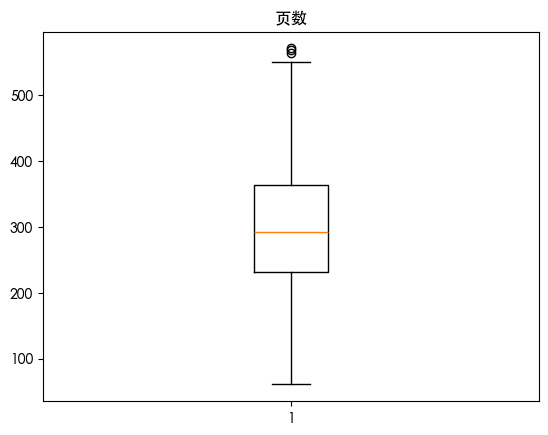
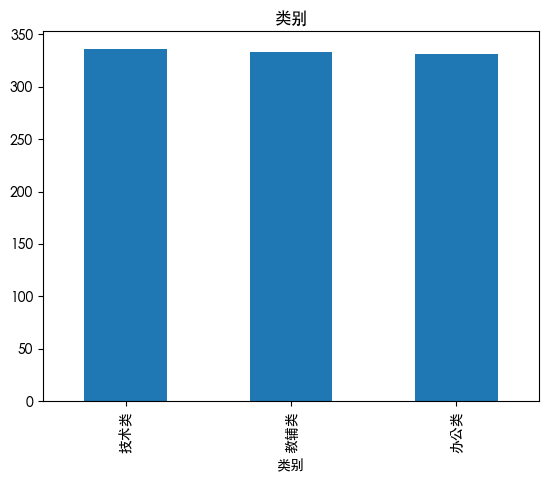
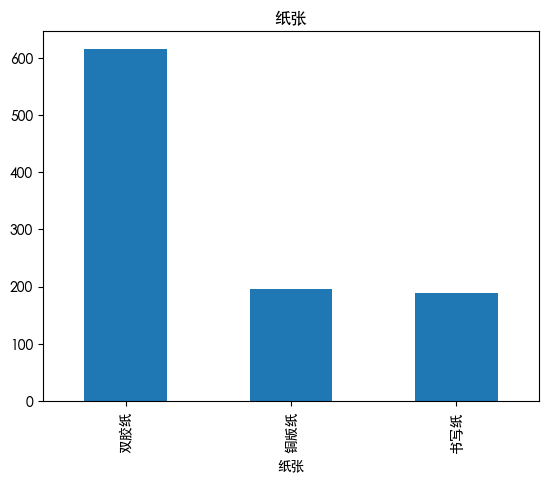
异常值处理 1 2 3 4 5 6 7 8 9 for col in df.columns: if df [col].dtype in ['int64' , 'float64' ]: plt.boxplot(df [col]) plt.title(col) plt.show() else : df [col].value_counts().plot(kind='bar' ) plt.title(col) plt.show()
发现页数存在异常值 将页数进行胜率变换
1 2 from scipy.stats import mstats df ['页数' ] = mstats.winsorize(df ['页数' ], limits=[0.01, 0.01])
特征编码 1 2 3 4 5 6 7 df ['类别' ].describe()df ['纸张' ].describe()from sklearn.preprocessing import LabelEncoder le = LabelEncoder() df ['类别' ] = le.fit_transform(df ['类别' ])df ['纸张' ] = le.fit_transform(df ['纸张' ])
统计量
值
count
1000
unique
3
top
技术类
freq
336
统计量
值
count
1000
unique
3
top
双胶纸
freq
615
数据划分 1 2 3 4 5 6 from sklearn.model_selection import train_test_split X = df.drop(['价格' ], axis=1) y = df ['价格' ] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
GBDT 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from sklearn.ensemble import GradientBoostingRegressor GBDT = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42) GBDT.fit(X_train, y_train) y_pred = GBDT.predict(X_test) from sklearn.metrics import mean_squared_error rmse = mean_squared_error(y_test, y_pred, squared=False) print ("Root Mean Squared Error:" , rmse)from sklearn.metrics import r2_score r2 = r2_score(y_test, GBDT.predict(X_test)) print (r2)from sklearn.metrics import mean_squared_log_error rmsle = mean_squared_log_error(y_test, y_pred, squared=False) print ("GBDT RMSLE:" , rmsle)
Root Mean Squared Error: 8.252320312081766
XGBoost 1 2 3 4 5 6 7 8 9 10 11 from xgboost import XGBRegressor xgb = XGBRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42) xgb.fit(X_train, y_train) y_pred_xgb = xgb.predict(X_test) rmse_xgb = mean_squared_error(y_test, y_pred_xgb, squared=False) print ("XGBoost Root Mean Squared Error:" , rmse_xgb)r2_xgb = r2_score(y_test, y_pred_xgb) print (r2_xgb)rmsle_xgb = mean_squared_log_error(y_test, y_pred_xgb, squared=False) print ("XGBoost RMSLE:" , rmsle_xgb)
XGBoost Root Mean Squared Error: 8.176196042228552
LGBM 1 2 3 4 5 6 7 8 9 10 11 from lightgbm import LGBMRegressor lgbm = LGBMRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42) lgbm.fit(X_train, y_train) y_pred_lgbm = lgbm.predict(X_test) rmse_lgbm = mean_squared_error(y_test, y_pred_lgbm, squared=False) print ("LightGBM RMSE:" , rmse_lgbm)r2_lgbm = r2_score(y_test, y_pred_lgbm) print (r2_lgbm)rmsle_lgbm = mean_squared_log_error(y_test, y_pred_lgbm, squared=False) print ("LightGBM RMSLE:" , rmsle_lgbm)
LightGBM RMSE: 8.222406796622195
SVM 1 2 3 4 5 6 7 8 9 10 11 from sklearn.svm import SVR svr = SVR(kernel='linear' , C=1.0, epsilon=0.1) svr.fit(X_train, y_train) y_pred_svr = svr.predict(X_test) rmse_svr = mean_squared_error(y_test, y_pred_svr, squared=False) print ("SVR RMSE:" , rmse_svr)r2_svr = r2_score(y_test, y_pred_svr) print (r2_svr)rmsle_svr = mean_squared_log_error(y_test, y_pred_svr, squared=False) print ("SVR RMSLE:" , rmsle_svr)
SVR RMSE: 15.248610756339428
KNN 1 2 3 4 5 6 7 8 9 10 11 from sklearn.neighbors import KNeighborsRegressor knn = KNeighborsRegressor(n_neighbors=5) knn.fit(X_train, y_train) y_pred_knn = knn.predict(X_test) rmse_knn = mean_squared_error(y_test, y_pred_knn, squared=False) print ("KNN RMSE:" , rmse_knn)r2_knn = r2_score(y_test, y_pred_knn) print (r2_knn)rmsle_knn = mean_squared_log_error(y_test, y_pred_knn, squared=False) print ("KNN RMSLE:" , rmsle_knn)
KNN RMSE: 14.38134207923586
产品定价模型回归结果 模型评估结果对比
模型
RMSE
R²
RMSLE
GBDT
8.252
0.847
0.145
XGBoost
8.176
0.849
0.143
LightGBM
8.222
0.848
0.143
SVR
15.249
0.476
0.239
KNN
14.381
0.534
0.238
结果解读 集成树模型(GBDT / XGBoost / LightGBM)
特点:
能捕捉非线性关系和特征交互。
不依赖特征标准化,对异常值不敏感。
Boosting 框架逐步优化残差。
结果:
RMSE ~8、R² ~0.85、RMSLE ~0.14 → 效果最佳。
XGBoost/LightGBM 在优化与并行上更先进,略优于传统 GBDT。
SVR(支持向量回归)
特点:
基于核函数映射,高维空间里拟合线性。
更适合连续、平滑的函数关系。
对高维离散特征敏感,需要标准化与合适核函数。
结果:
RMSE ~15、R² ~0.48 → 误差大,拟合不足。
难以捕捉“跳跃式”的定价规律。
KNN(K近邻回归)
特点:
基于“相似样本价格相似”的假设。
局部模型,对高维数据容易受“维度灾难”影响。
结果:
RMSE ~14、R² ~0.53 → 效果一般。
最近邻不一定能找到真正相似的样本。
总结
最佳模型: XGBoost / LightGBM 稳定且泛化最好可选模型: GBDT 性能稍逊不适合: SVR、KNN 误差大,拟合不足