商业数据分析--广告收益数据

声明
本文代码均保存在
https://github.com/super-213/business_data_analysis
有需要的可以自行下载
查看数据
1 | df = pd.read_excel('广告收益数据.xlsx') |
| 电视 | 广播 | 报纸 | 收益 |
|---|---|---|---|
| 230.1 | 37.8 | 69.2 | 331.5 |
| 44.5 | 39.3 | 45.1 | 156.0 |
| 17.2 | 45.9 | 69.3 | 139.5 |
| 151.5 | 41.3 | 58.5 | 277.5 |
| 180.8 | 10.8 | 58.4 | 193.5 |
缺失值处理
1 | df.isnull().sum() |
| 字段 | 缺失值数量 |
|---|---|
| 电视 | 0 |
| 广播 | 0 |
| 报纸 | 0 |
| 收益 | 0 |
异常值处理
1 | for col in df.columns: |
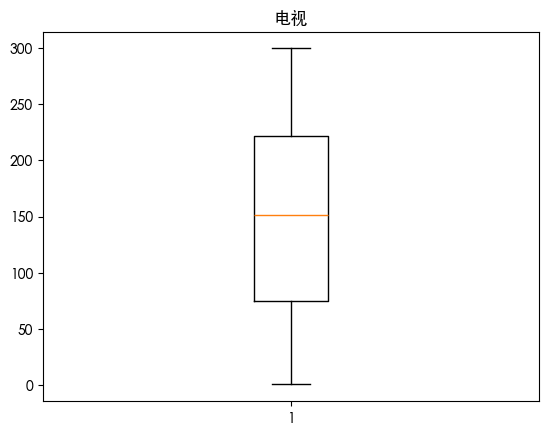
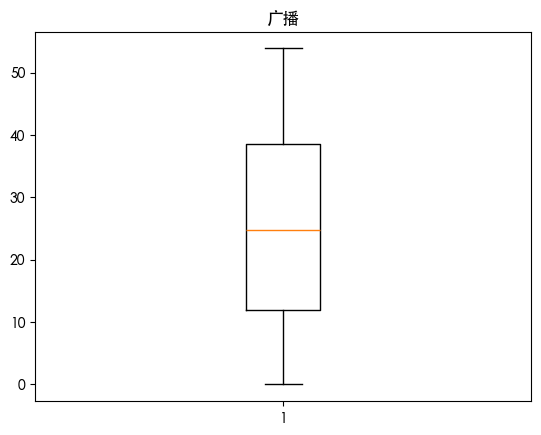
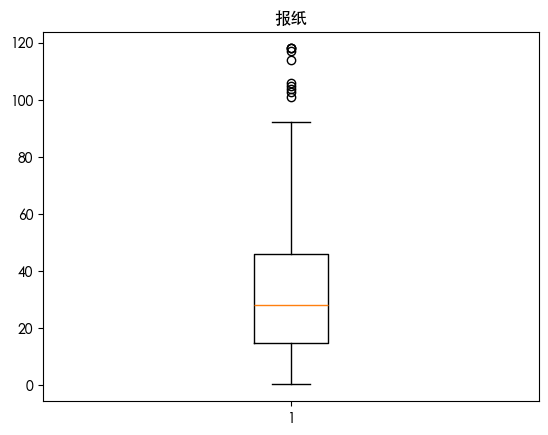
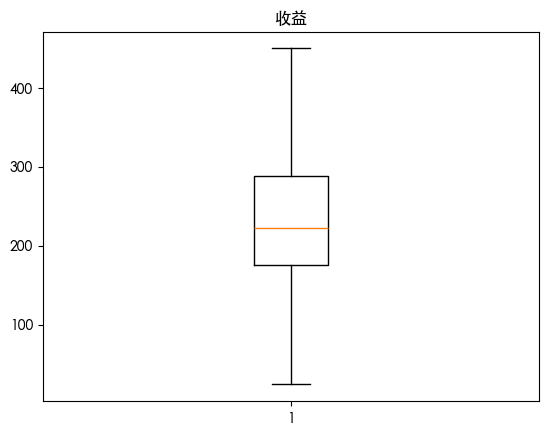
发现报纸存在异常值 画出热力图查看其相关性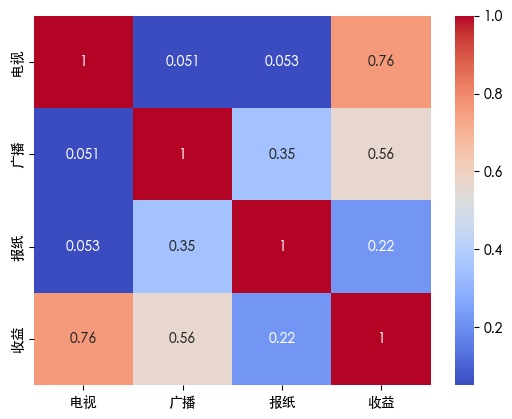
发现报纸与收益的相关性系数为0.22 虽然是一个比较小的数 但是考虑到数据只有3个特征 我们添加一列用于保留异常值
1 | col = '报纸' |
数据划分
1 | from sklearn.model_selection import train_test_split |
XGBoost
1 | from xgboost import XGBRegressor |
XGBoost 模型性能
- MSE: 297.333
- R²: 0.9586
| feature | importance |
|---|---|
| 电视 | 0.561881 |
| 广播 | 0.412244 |
| 报纸 | 0.025875 |
| 报纸_is_outlier | 0.000000 |
可以看到 我们新增的特征完全没有用 可以将上述的新增特征的代码删除
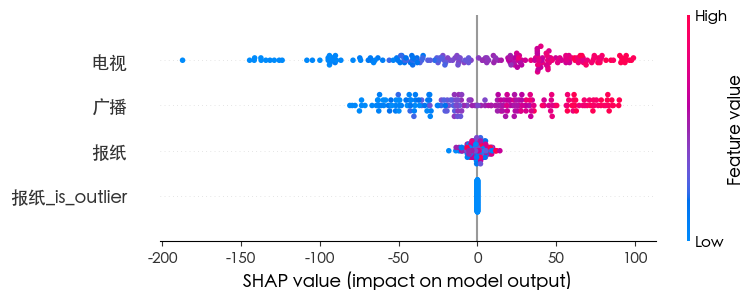
LGBM
1 | from lightgbm import LGBMRegressor |
LGBM 模型性能
- MSE: 308.58
- R²: 0.9570
| feature | importance |
|---|---|
| 广播 | 990 |
| 电视 | 981 |
| 报纸 | 978 |
| 报纸_is_outlier | 0 |
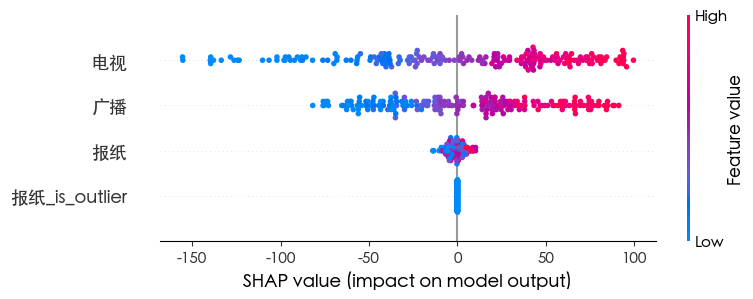
随机森林
1 | from sklearn.ensemble import RandomForestRegressor |
Random Forest 模型性能
- MSE: 277.82
- R²: 0.9613
| feature | importance |
|---|---|
| 电视 | 0.624624 |
| 广播 | 0.356226 |
| 报纸 | 0.018884 |
| 报纸_is_outlier | 0.000266 |
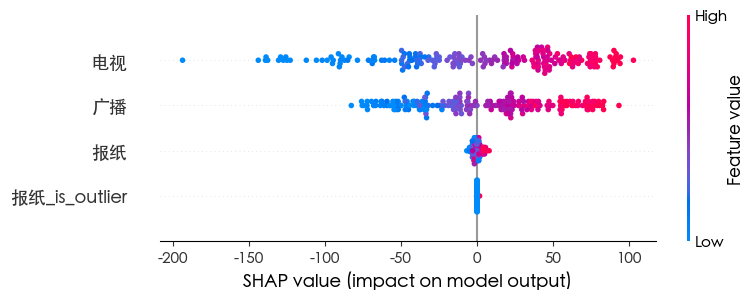
SVM
1 | from sklearn.svm import SVR |
SVR MSE: 2942.2258137398626
SVR R2: 0.5903858154199828
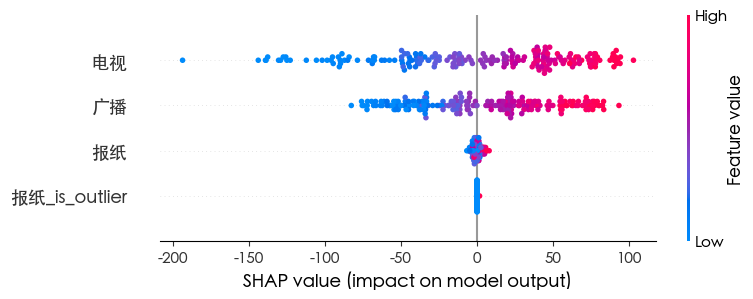
KNN
1 | from sklearn.neighbors import KNeighborsRegressor |
KNN MSE: 423.61199999999997
KNN R2: 0.9410250963240132
模型横向对比
XGBoost
- 性能: MSE = 297.33,R2 = 0.9586
- 特征重要性: 电视 > 广播 > 报纸
- 特点:
- 作为 Boosting 模型,它在处理非线性关系和特征交互方面很强 能较好地拟合广告投入与收益的关系
- 由于数据集相对简单(变量少,关系较直观) XGBoost 表现稳定但没有压倒性优势
- 新增的“报纸_is_outlier”特征完全无效 说明模型能自动忽略无信息量的特征 避免过拟合
LightGBM
- 性能: MSE = 308.58,R2 = 0.9570
- 特征重要性: 广播 ≈ 电视 ≈ 报纸(几乎持平)
- 特点:
- LightGBM 与 XGBoost 同属 Boosting 系列 但它采用了基于直方图的分裂方式,更适合高维稀疏特征
- 在这个小数据集上 优势不明显 反而略逊于 XGBoost
- 特征重要性差别不大 说明 LightGBM 在分裂时对每个特征都较平均地利用 但这可能导致它对真实最关键的“电视”变量抓取力度稍弱
随机森林
- 性能: MSE = 277.82,R2 = 0.9613
- 特征重要性: 电视 > 广播 > 报纸
- 特点:
- Bagging 思路 适合低维小数据 能降低方差、提高稳定性
- 在广告收益数据集中 投入与收益的关系并不复杂 因此随机森林可以在不需要 Boosting 那种强烈逐步修正的情况下 直接通过平均化结果取得最优表现
- 树模型捕捉到了 “电视广告” 的关键作用
SVM
- 性能: MSE = 2942.23,R2 = 0.5904
- 特点:
- 默认参数的 SVR(核函数 RBF,C=1)不适合这种回归任务。它需要仔细调参(C、γ、ε)才能拟合非线性关系
- 数据集维度很低(只有 3 个主要特征) 而 SVR 在小样本、复杂边界时更有优势 但这里的关系接近线性 SVR 没有优势。
- 因此在这个广告收益场景中 SVR 明显欠拟合
KNN
- 性能: MSE = 423.61,R2 = 0.9410
- 特点:
- 基于邻居的局部平均方法 效果依赖样本分布和邻居数 k
- 在数据集较小、关系清晰时 KNN 能捕捉到一定趋势 但预测平滑化严重
- 所以它的表现比树模型差 但仍然比 SVR 稳定
| 模型 | MSE | R2 | 特点 |
|---|---|---|---|
| 随机森林 | 277.82 | 0.9613 | Bagging 模型,抗过拟合强,最适合此数据集 |
| XGBoost | 297.33 | 0.9586 | Boosting 思路,拟合能力强,但未明显优于RF |
| LightGBM | 308.58 | 0.9570 | 与XGB接近,小数据集不占优 |
| KNN | 423.61 | 0.9410 | 捕捉趋势,但预测过于平滑 |
| SVR | 2942.23 | 0.5904 | 默认参数欠拟合,不适合本任务 |
结论:
- 广告收益预测是一个低维、非极复杂的回归问题,随机森林表现最佳。
- Boosting 系列(XGBoost / LightGBM) 在特征复杂、数据量大时会更有优势。
- SVR 和 KNN 更适合特定场景,这里表现不佳。
- Title: 商业数据分析--广告收益数据
- Author: 姜智浩
- Created at : 2025-09-26 11:45:14
- Updated at : 2025-09-26 10:58:36
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/09/26/20250926商业数据分析--广告收益数据/
- License: This work is licensed under CC BY-NC-SA 4.0.