摘要 本研究针对古塔的变形监测与预测问题展开分析,主要解决三个方面的问题:层中心定位、塔体形变特征量化及未来变形趋势预测。
关键词: 圆拟合;Theil–Sen 稳健趋势估计;Mann–Kendall 趋势显著性检验
一、 问题重述 由于长时间承受自重、气温、风力 等各种作用,偶然还要受地震、飓风的影响,古塔会产生各种变形,诸如倾斜、弯曲、扭曲等。为保护古塔,文物部门需适时对古塔进行观测,了解各种变形量,以制定必要的保护措施。某古塔已有上千年历史,是我国重点保护文物。管理部门委托测绘公司先后于1996年7月、2006年8月、2019年3月和2021年3月对该塔进行了4次观测。请你们根据附件1提供的4次观测数据,讨论以下问题:
二、 问题分析 2.1问题一的分析 古塔变形监测的首要任务是准确确定各层的中心位置,这是后续变形分析的基础。由于古塔各层在空间中大致呈圆形分布,但在长期自然环境作用下可能发生倾斜、弯曲等复杂变形,观测点不再保持理想的圆形分布,直接采用算术平均法计算中心坐标会引入较大误差。基于上述约束,确定层中心位置的关键在于在水平面上进行圆拟合,从而稳健估计圆形投影的中心,降低观测误差的干扰。
2.2问题二的分析 在获得各层中心坐标之后,需要进一步分析古塔的整体与局部变形特征。这一问题的核心在于如何将 几何直观的变形现象如倾斜、弯曲、扭曲转化为可量化的数学指标。为此,我们的主要思路是通过 塔轴拟合分析整体倾斜趋势;通过层心偏离量计算刻画塔体的弯曲变形;通过旋转角度分析反映扭曲特征;结合塔尖偏心量,考察局部敏感部位的变形情况。
2.3问题三的分析 问题三的重点在于:如何利用有限的监测数据,提取可靠的长期趋势;如何在存在测量误差和异常值的情况下,避免预测受到过度干扰。
三、 模型准备 3.1模型假设
假设古塔形状对称
假设塔轴是一条直线
古塔变形过程在该时间尺度上可近似为线性变化
层心可代表整层的几何中心
测量的误差相互独立
塔体材料与结构不发生突变
3.2符号说明
\theta
倾角
\alpha
倾向
d_i
弯曲量
ecc
层心偏心量
\phi
扭曲量
3.3数据预处理 在古塔变形分析的过程中,原始观测数据可能存在缺失或不一致的情况,直接影响模型建立的准确性,因此我们对1996年、2006年、2019年和2021年的四次观测数据进行了处理与填充。
由于附件1的数据格式不便于后续处理,我们将其重组为“年份、层号、点号、X、Y、Z坐标”的表格形式保存为temp.csv文件,便于后续分析。
我们发现附件1中在1996年和2006年的数据中,第13层第5个观测点的坐标值缺失。由于古塔的结构变形在垂直方向上通常具有连续性,我们采用层间差分法进行填充。该方法假设相邻层之间的变形趋势相似,通过计算下层点的坐标差分来估计缺失点的位置。填充过程如下:首先,找到缺失点所在层的前两层(即第11层和第12层)的对应点坐标;然后计算这两层之间在x、y、z方向上的差分值;最后,将这些差分值应用到第12层的点上,得到第13层缺失点的估计坐标。填充的数据为(567.984,519.5880,52.984)和(567.990,519.5816,52.983)。
四、 模型建立与求解 4.1问题一模型建立与求解 4.1问题一模型建立 基于古塔的结构特点和变形特征,我们采用圆拟合相结合的方法来确定各层中心坐标。考虑到古塔各层在理想状态下应呈圆形分布,但由于长期变形和测量误差,实际观测点往往会偏离理论圆形。我们采通过最小化观测点到拟合圆的代数距离平方和,来估计最可能的圆心位置和半径。这种方法相比简单的算术平均法,能够更好地抵抗异常点的干扰,提供更加稳定的中心坐标估计。Missing or unrecognized delimiter for \left \left{ \left(x_{t,l,i}, y_{t,l,i}\right) ,\middle|, t = 1,2,3,4 ;; l = 1,\ldots,13 ;; i = 1,2,\ldots,8 \right}
理论上应分布在同一圆上(对应古塔水平截面),但受测量误差和古塔变形影响,实际存在偏差。因此,我们需要找到一个圆,让这些点尽可能 “贴近” 拟合圆,圆的标准方程如下:
4.1.2模型的求解
层数
1996年 (x,y,z)
2006年 (x,y,z)
2019年 (x,y,z)
2021年 (x,y,z)
1
566.664,522.709,1.787
566.665,522.708,1.783
566.744,522.700,1.764
566.744,522.700,1.763
2
566.722,522.671,7.320
566.723,522.670,7.314
566.778,522.671,7.308
566.779,522.671,7.290
3
566.778,522.634,12.755
566.780,522.633,12.750
566.811,522.645,12.732
566.812,522.645,12.726
4
566.822,522.605,17.078
566.824,522.603,17.075
566.838,522.623,17.069
566.838,522.622,17.052
5
566.869,522.574,21.720
566.872,522.571,21.716
566.866,522.600,21.709
566.867,522.599,21.703
6
566.918,522.544,26.235
566.922,522.540,26.229
566.955,522.551,26.211
566.956,522.550,26.204
7
566.952,522.527,19.836
566.956,522.523,29.832
566.989,522.529,29.824
566.989,522.528,29.817
8
566.984,522.510,33.350
566.988,522.506,33.345
566.041,522.497,33.339
566.042,522.496,33.336
9
567.017,522.493,36.854
567.022,522.488,36.848
567.094,522.464,36.843
567.095,522.463,36.822
10
567.047,522.479,40.172
567.052,522.473,40.167
567.148,522.410,40.161
567.149,522.409,40.144
11
567.101,522.438,44.440
567.107,522.433,44.435
567.190,522.370,44.432
567.192,522.368,44.424
12
567.155,522.398,48.711
567.161,522.392,48.707
567.233,522.330,48.699
567.234,522.328,48.683
13
567.207,522.360,52.853
567.213,522.354,52.849
567.281,522.284,52.818
567.283,522.283,52.813
塔尖
567.264,522.254,55.108
567.254,522.236,55.119
567.336,522.214,55.091
567.337,522.213,55.087
4.2问题二模型建立、求解与分析 4.2.1问题二模型的建立 问题二要求我们分析塔的倾斜、弯曲、扭曲等变形情况。
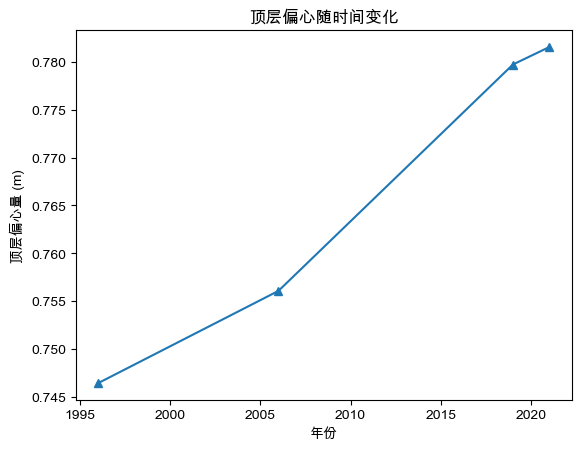
为进一步分析塔尖的局部形变,我们计算顶层偏心量{\text{top}} = \sqrt{(x {\text{top}} - x_0)^2 + (y_{\text{top}} - y_0)^2}
塔的扭曲是指沿高度方向,层心在水平面上旋转或偏转角度的变化。扭曲角\phi_i可定义为:
4.2.2问题二模型的求解 在完成指标体系的构建后,我们基于 1996年、2006年、2019年和 2021年的测量数据,分别计算了各年份对应的倾角、倾向、平均偏心量、平均弯曲量、平均扭曲角以及顶层偏心量。结果见表 4.2.1—表 4.2.4。
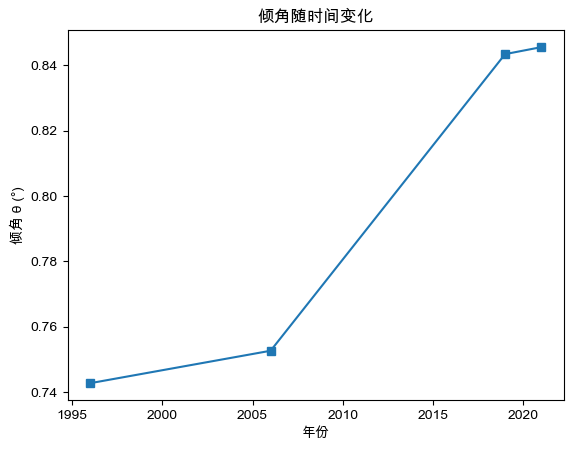
表4.2.1倾角与倾向结果
年份
倾角(度)
倾向(度)
1996
0.7427
-34.81
2006
0.7526
-34.95
2019
0.8434
-37.65
2021
0.8455
-37.68
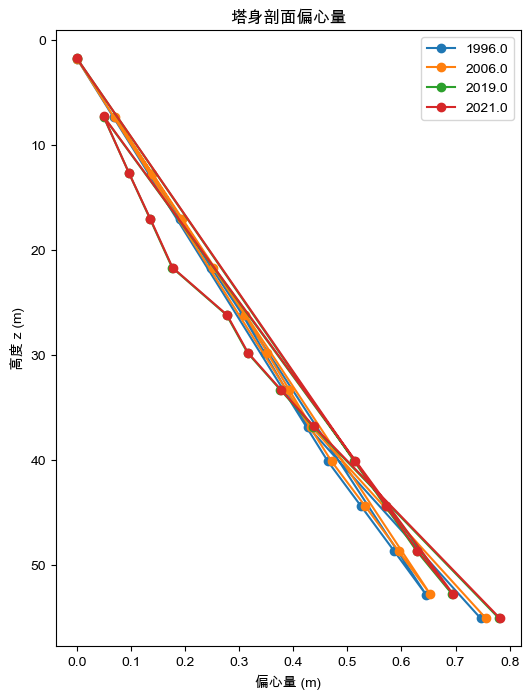
表4.2.2偏心量与顶层偏心量结果
年份
平均偏心量(米)
顶层偏心量(米)
1996
0.3629
0.7464
2006
0.3680
0.7561
2019
0.3605
0.7797
2021
0.3614
0.7815
表4.2.3弯曲量结果
年份
平均弯曲量(米)
1996
0.0117
2006
0.0117
2019
0.0063
2021
0.0063
表4.2.4扭曲角结果
年份
平均扭曲角(度)
1996
-33.0708
2006
-33.1866
2019
-35.5721
2021
-35.5790
4.2.3问题二模型的分析 通过对各项指标的对比与分析,我们可以得到以下结论:(1)整体倾斜趋势:
(2)整体偏移与局部弯曲:
(3)扭曲变化:
(4)塔尖偏移情况:
4.3第三问模型的建立、求解与分析 4.3.1模型的建立 古塔 4 次观测数据1996-2021 年时间跨度大、仅 4 个时间点,样本量少,且观测过程中可能存在仪器误差、环境干扰,如强风、振动等导致的异常值,传统线性回归对异常值敏感,易偏离真实趋势。长期非线性模型难以建立。塔体倾斜和弯曲在短时间尺度上多表现为缓慢累积的单调趋势,我们假设其变形过程在该时间尺度上可近似为线性变化。为验证这一假设,我们绘制了残差散点图,
结果显示残差范围在各变量量级的 5%~10% 内,属于合理范围,残差在零附近随机波动、无系统性模式,说明线性近似是合理的。因此选择Theil-Sen 稳健线性趋势法,这是个非参数方法,抗异常值能力强,无需数据满足正态分布。量化变形速率,搭配Mann-Kendall 检验,其适用于小样本、非正态数据判断趋势是否显著,二者结合可兼顾稳健性与统计严谨性。1. Theil-Sen 稳健趋势斜率估计
(1)计算所有成对斜率:
(2)取中位数作为趋势斜率 \hat{\mathbit{k}}: Missing or unrecognized delimiter for \left \hat{k} = \mathrm{median}\left{ s_{(1)}, s_{(2)}, s_{(3)}, s_{(4)}, s_{(5)}, s_{(6)} \right} = \frac{s_{(3)} + s_{(4)}}{2}
2.Mann-Kendall 趋势显著性检验 (1)构造统计量\mathbit{S}: ( 后 项 前 项 , 记 为 逆 增 ) ( 后 项 前 项 , 无 变 化 ) ( 后 项 前 项 , 记 为 递 减 )
(2)计算方差Var(S): (3)计算检验统计量 \mathbit{Z}
(5)p值的计算
4.3.2模型的求解 表4.3.1趋势估计
指标
倾角 θ
偏心量 ecc
弯曲量 d_i
扭曲量 φ
趋势斜率
0.0046/年
0.0015/年
-0.0017/年
0.0045/年
τ
1
1
-1
0.3333
p值
0.0833
0.0833
0.0833
0.7500
表4.3.2趋势分析结果
年份
倾角 θ
偏心量 ecc
弯曲量 d_i
扭曲量 φ
2022
0.8487
0.7828
0.0119
38.6307
2023
0.8533
0.7843
0.0102
38.6262
2024
0.8578
0.7858
0.0085
38.6216
2025
0.8624
0.7872
0.0067
38.6171
2026
0.8670
0.7887
0.0050
38.6125
4.3.3模型的分析 根据 Theil–Sen 趋势估计与 Mann–Kendall 检验结果,可以得到古塔在未来若干年内的形变演化趋势如下:在整体倾斜方面 ,倾角\theta的趋势斜率为 0.0046/年,M–K 检验结果\tau = 1.0,表明其具有稳定的单调上升趋势。虽然对应的 p 值为 0.0833,未在 95% 置信水平下达到显著性,但结合历年数据可见,塔体倾斜程度正逐步增强。在塔尖偏移方面 ,偏心量的趋势斜率为 0.0015 m/年,同样表现为单调递增趋势(\tau = 1.0,p=0.0833)。预测结果显示,塔尖相对底心的水平偏移量将从 2021 年的约 0.7815 m 增至 2026 年的 0.789 m,说明塔尖在缓慢外移。在弯曲形变方面 ,平均弯曲量的趋势斜率为 -0.0017 m/年,M–K 检验结果\tau = -1.0,表明其呈现单调下降趋势。虽然 p=0.0833 表明显著性不足,但整体结果仍显示塔身弯曲程度在逐步减小。预测结果显示,弯曲量将由 2021 年的 0.0063 m 降至 2026 年约 0.0050 m,说明随着时间推移,塔体在局部曲率上的形变趋缓。在扭曲变形方面 ,扭曲量\phi的趋势斜率为 0.0045/年,但\tau值仅为 0.3333,且 p 值高达 0.75,表明其趋势不显著,数据中随机波动的成分较大。因此,目前无法得出塔体扭曲存在明显长期变化的结论,未来仍需进一步长期监测以提高可靠性。
五、 模型的评价与改进 本研究采用的 Theil–Sen 稳健趋势估计结合 Mann–Kendall 显著性检验具有几个优势。它对异常值和测量误差具有较强的抵抗力,比传统线性回归更稳健;Mann–Kendall 检验可以判断趋势是否显著,不依赖数据的分布类型;这套方法易于理解,斜率和 p 值可以直观反映变形随时间的变化;它适用于观测次数较少的情况,符合古塔监测数据量有限的实际情况。
六、 模型的推广与应用 6.1同类古建筑的变形监测 本模型的核心方法可直接推广至砖石结构、木构结构等不同类型的古建筑,只需根据结构特性微调参数与假设即可适配。对于砖石结构类古塔,其层间变形规律与本次研究的古塔高度相似,仅需沿用 “圆拟合 + z 坐标平均” 的层心定位方法,若塔身截面因风化呈现非标准圆形,如椭圆形、多边形,可将圆拟合扩展为椭圆拟合或多边形拟合。
6.2 近现代竖向结构的健康评估 近现代高耸结构,如钢筋混凝土烟囱、输电塔、水塔,与古塔同属竖向受力结构,变形类型,如倾斜、弯曲、扭曲高度相似,本模型的变形量化与趋势分析方法可直接复用,仅需针对荷载特性调整数据预处理环节。
参考文献 [1] 张立福, 刘经南, 陈军. 基于圆拟合的塔式建筑倾斜监测方法研究[J]. 武汉大学学报(信息科学版), 2004, 29(5): 395-398.
附录 附录A支撑材料文件列表
文件名
文件内容
模拟实战2_古塔的变形.ipynb
三个问题的求解
temp.csv
把 Excel 转换成 CSV 文件
tower.csv
预处理填充后的完整数据
guta_centers_circle.csv
第一问古塔中心坐标数据
problem3.csv
第二问求解得到的数据
problem3_trend.csv
第三问预测数据
附录B程序代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import pandas as pd import numpy as np def fill_missing_interlayer(df , year, layer, point): "" " 用层间差分法填充缺失点 (适用于行存在但 xyz 缺失的情况) df: DataFrame,包含 [year, layer, point, x, y, z] " "" prev_layer = layer - 1 prev2_layer = layer - 2 p1 = df [(df ["year" ] == year) & (df ["layer" ] == prev2_layer) & (df ["point" ] == point)] p2 = df [(df ["year" ] == year) & (df ["layer" ] == prev_layer) & (df ["point" ] == point)] if p1.empty or p2.empty: raise ValueError(f"{year} 年第 {prev2_layer}/{prev_layer} 层缺少第 {point} 点,无法补全 {layer} 层" ) dx = float (p2["x" ].values[0] - p1["x" ].values[0]) dy = float (p2["y" ].values[0] - p1["y" ].values[0]) dz = float (p2["z" ].values[0] - p1["z" ].values[0]) x_missing = float (p2["x" ].values[0] + dx) y_missing = float (p2["y" ].values[0] + dy) z_missing = float (p2["z" ].values[0] + dz) mask = (df ["year" ] == year) & (df ["layer" ] == layer) & (df ["point" ] == point) if mask.sum() == 0: raise ValueError(f"{year} 年第 {layer} 层第 {point} 点行不存在" ) else : df.loc[mask, ["x" , "y" , "z" ]] = [x_missing, y_missing, z_missing] return df file_path = '/Volumes/HIKSEMI/作业/数学建模集训/模拟实战2_古塔的变形/模拟实战2_古塔的变形/temp.csv' df = pd.read_csv(file_path)df ["year" ] = df ["year" ].astype("Int64" )df ["point" ] = df ["point" ].astype("Int64" )df ["layer" ] = pd.to_numeric(df ["layer" ], errors="coerce" )df = fill_missing_interlayer(df , 1996, 13, 5)df = fill_missing_interlayer(df , 2006, 13, 5)df.to_csv("tower.csv" , index=False) print ("缺失点已补全 保存到 tower.csv" )print ("填补的数据为:" )print (df [(df ["year" ].isin([1996, 2006])) & (df ["layer" ] == 13) & (df ["point" ] == 5)])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pandas as pd file_path = '/Volumes/HIKSEMI/作业/数学建模集训/模拟实战2_古塔的变形/模拟实战2_古塔的变形/temp.csv' df = pd.read_csv(file_path)centers = df.groupby(["year" , "layer" ]).agg( x_center=("x" , "mean" ), y_center=("y" , "mean" ), z_center=("z" , "mean" ) ).reset_index() centers.to_csv("guta_centers.csv" , index=False) print ("各层中心坐标已保存到 guta_centers.csv" )print (centers.head(20))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import pandas as pd import numpy as np from scipy.optimize import least_squares def fit_circle(xs, ys): x_m, y_m = np.mean(xs), np.mean(ys) r0 = np.mean(np.sqrt((xs - x_m)**2 + (ys - y_m)**2 )) if r0 <= 0 or np.isnan(r0): r0 = 1.0 init_params = [x_m, y_m, r0] def residuals(params): a, b, r = params return np.sqrt((xs - a)**2 + (ys - b)**2 ) - r # 设置约束:半径 >= 0 res = least_squares(residuals, init_params, bounds=([-np.inf, -np.inf, 0 ], [np.inf, np.inf, np.inf])) a, b, r = res.x return a, b, r df = pd.read_csv(file_path)results = [] for (year, layer), group in df.groupby(["year" , "layer" ]): xs, ys, zs = group["x" ].values, group["y" ].values, group["z" ].values if len(group) >= 3: try: a, b, r = fit_circle(xs, ys) except Exception as e: print (f"{year}-{layer} 拟合失败,改用平均值: {e}" ) a, b = xs.mean(), ys.mean() r = np.nan else : a, b = xs.mean(), ys.mean() r = np.nan zc = zs.mean() results.append([year, layer, a, b, zc, r]) centers_df = pd.DataFrame(results, columns=["year" , "layer" , "x_center" , "y_center" , "z_center" , "radius" ]) centers_df.to_csv("guta_centers_circle.csv" , index=False) print ("圆拟合法结果已保存到 guta_centers_circle.csv" )print (centers_df.head(20))
1 2 3 4 import numpy as np import pandas as pd import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 file_path = '/Volumes/HIKSEMI/作业/数学建模集训/模拟实战2_古塔的变形/guta_centers_circle.csv' centers_df = pd.read_csv(file_path) fig = plt.figure(figsize=(8,12)) ax = fig.add_subplot(111, projection='3d' ) for idx, row in centers_df.iterrows(): x0, y0, z0 = row['x_center' ], row['y_center' ], row['z_center' ] r = row['radius' ] if not np.isnan(r): theta = np.linspace(0, 2*np.pi, 100) x = x0 + r * np.cos(theta) y = y0 + r * np.sin(theta) z = np.full_like(x, z0) ax.plot(x, y, z, color='b' ) ax.scatter(x0, y0, z0, color='r' , s=20) else : ax.scatter(x0, y0, z0, color='r' , s=20) ax.set_xlabel('X' ) ax.set_ylabel('Y' ) ax.set_zlabel('Z' ) ax.set_box_aspect([1,1,2]) plt.title("古塔三维图" ) plt.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import pandas as pd import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d.art3d import Poly3DCollection from scipy.spatial import ConvexHull file_path = '/Volumes/HIKSEMI/作业/数学建模集训/模拟实战2_古塔的变形/模拟实战2_古塔的变形/temp.csv' df = pd.read_csv(file_path)def layer_sort_key(x): try: return int(x) except: return 1000 layers = sorted(df ['layer' ].unique(), key=layer_sort_key) fig = plt.figure(figsize=(10,12)) ax = fig.add_subplot(111, projection='3d' ) layer_points = [] for layer in layers: pts = df [df ['layer' ]==layer][['x' ,'y' ,'z' ]].values if len(pts) >= 3: hull = ConvexHull(pts[:, :2]) boundary = pts[hull.vertices] layer_points.append(boundary) ax.scatter(pts[:,0], pts[:,1], pts[:,2], s=10, color='r' ) else : layer_points.append(None) ax.scatter(pts[:,0], pts[:,1], pts[:,2], s=20, color='r' ) for i in range(len(layer_points)-1): pts1 = layer_points[i] pts2 = layer_points[i+1] if pts1 is not None and pts2 is not None: n1 = len(pts1) n2 = len(pts2) for j in range(n1): p1 = pts1[j] p2 = pts1[(j+1)%n1] distances = np.sum((pts2[:, :2 ] - p1[:2 ])**2 , axis=1 ) idx = np.argsort(distances)[:2 ] p3, p4 = pts2[idx[0 ]], pts2[idx[1 ]] verts = [[p1, p2, p4, p3]] ax.add_collection3d(Poly3DCollection(verts, color='orange', alpha=0.3 )) ax.set_xlabel('X' ) ax.set_ylabel('Y' ) ax.set_zlabel('Z' ) ax.set_box_aspect([1,1,2]) plt.title("古塔三维网格模型" ) plt.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 import pandas as pd import numpy as np import matplotlib.pyplot as plt from collections import defaultdict from sklearn.linear_model import LinearRegression file_path = '/Volumes/HIKSEMI/作业/数学建模集训/模拟实战2_古塔的变形/模拟实战2_古塔的变形/temp.csv' df = pd.read_csv(file_path)layer_centers = [] for (year, layer), group in df.groupby(["year" , "layer" ]): x_mean = group["x" ].mean() y_mean = group["y" ].mean() z_mean = group["z" ].mean() layer_centers.append([year, layer, x_mean, y_mean, z_mean]) centers_df = pd.DataFrame(layer_centers, columns=["year" , "layer" , "x" , "y" , "z" ]) def fit_axis(centers): "" " 输入:某一年的层心数据 (x,y,z) 输出:塔轴方向向量、倾角theta、倾向alpha " "" X = centers[["z" ]].values Yx = centers["x" ].values Yy = centers["y" ].values regx = LinearRegression().fit(X, Yx) regy = LinearRegression().fit(X, Yy) a = regx.coef_[0] b = regy.coef_[0] c = 1.0 theta = np.arctan(np.sqrt(a**2 + b**2) / c) * 180 / np.pi alpha = np.arctan2(b, a) * 180 / np.pi return (a, b, c), theta, alpha axis_results = {} for year, group in centers_df.groupby("year" ): vec, theta, alpha = fit_axis(group) axis_results[year] = {"theta" : theta, "alpha" : alpha} ecc_results = defaultdict(list) for (year, group) in centers_df.groupby("year" ): base_x, base_y = group[group["layer" ] == group["layer" ].min()][["x" , "y" ]].values[0] for _, row in group.iterrows(): ecc = np.sqrt((row["x"] - base_x) ** 2 + (row["y"] - base_y) ** 2 ) ecc_results[year].append((row["layer"], row["z"], ecc)) bending_results = defaultdict(list) torsion_results = defaultdict(list) for year, group in centers_df.groupby("year" ): x0, y0 = group[group["layer" ]==group["layer" ].min()][["x" ,"y" ]].values[0] vec, theta, alpha = fit_axis(group) a, b, c = vec for _, row in group.iterrows(): x, y, z = row["x" ], row["y" ], row["z" ] d = abs((x - x0)*b - (y - y0)*a) / np.sqrt(a**2 + b**2 ) bending_results[year].append((row["layer"], z, d)) phi = np.arctan2(y - y0, x - x0) * 180/np.pi torsion_results[year].append((row["layer"], z, phi)) print ("=== 倾角与倾向 ===" )for year in sorted(axis_results.keys()): print (f"{year}: 倾角 θ = {axis_results[year]['theta']:.4f}°, 倾向 α = {axis_results[year]['alpha']:.2f}°" ) print ("=== 偏心量 ===" )for year, values in ecc_results.items(): print (f"{year}: 平均偏心量 = {np.mean([v[2] for v in values]):.4f} m" ) print ("=== 弯曲量 ===" )for year, values in bending_results.items(): print (f"{year}: 平均弯曲量 = {np.mean([v[2] for v in values]):.4f} m" ) print ("=== 扭曲量 ===" )for year, values in torsion_results.items(): print (f"{year}: 平均扭曲角 = {np.mean([v[2] for v in values]):.4f}°" ) print ("=== 顶层偏心量 ===" )for year, values in ecc_results.items(): top_layer, top_z, top_ecc = values[-1] print (f"{year}: 顶层 {top_layer} 偏心量 = {top_ecc:.4f} m" ) years = sorted(axis_results.keys()) theta_values = [axis_results[y]["theta" ] for y in years] ecc_top = [max(ecc_results[y], key=lambda v: v[1])[2] for y in years] di = [max(bending_results[y], key=lambda v: v[1])[2] for y in years] phi = [max(torsion_results[y], key=lambda v: v[1])[2] for y in years] predict_df = pd.DataFrame({ "year" : years, "theta" : theta_values, "ecc" : ecc_top, "di" : di, "phi" : phi }) predict_df.to_csv("problem3.csv" , index=False) print ("问题3使用的数据已保存到 problem3.csv" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 plt.figure(figsize=(6,8)) for year, values in ecc_results.items(): zs = [v[1] for v in values] eccs = [v[2] for v in values] plt.plot(eccs, zs, marker="o" , label=str(year)) plt.xlabel("偏心量 (m)" ) plt.ylabel("高度 z (m)" ) plt.title("塔身剖面偏心量" ) plt.legend() plt.gca().invert_yaxis() plt.show() years = sorted(axis_results.keys()) thetas = [axis_results[y]["theta" ] for y in years] plt.figure() plt.plot(years, thetas, marker="s" ) plt.xlabel("年份" ) plt.ylabel("倾角 θ (°)" ) plt.title("倾角随时间变化" ) plt.show() top_ecc = [] for year, values in ecc_results.items(): top_ecc.append((year, max(values, key=lambda v: v[1 ])[2 ])) top_ecc.sort() plt.figure() plt.plot([t[0] for t in top_ecc], [t[1] for t in top_ecc], marker="^" ) plt.xlabel("年份" ) plt.ylabel("顶层偏心量 (m)" ) plt.title("顶层偏心随时间变化" ) plt.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression df = pd.read_csv("problem3.csv" )for col in ["theta" , "ecc" , "di" , "phi" ]: X = df [["year" ]].values y = df [col].values model = LinearRegression().fit(X, y) y_pred = model.predict(X) residuals = y - y_pred plt.figure(figsize=(10,4)) plt.subplot(1,2,1) plt.scatter(df ["year" ], residuals, color="blue" , s=60) plt.axhline(0, color="red" , linestyle="--" ) plt.xlabel("Year" ) plt.ylabel("Residuals" ) plt.ylim(-1,1) plt.title(f"{col} Residuals Scatter Plot" ) plt.subplot(1,2,2) plt.hist(residuals, bins=5, color="orange" , edgecolor="black" , alpha=0.7) plt.xlabel("Residual" ) plt.ylabel("Frequency" ) plt.title("Residuals Distribution" ) plt.tight_layout() plt.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import pandas as pd, numpy as np from sklearn.linear_model import LinearRegression from scipy.stats import kendalltau df = pd.read_csv("problem3.csv" )def ols_forecast(x_year, y, years_ahead=5): X = x_year.reshape(-1,1) reg = LinearRegression().fit(X, y) y_fit = reg.predict(X) future_years = np.arange(x_year.max()+1, x_year.max()+1+years_ahead) y_future = reg.predict(future_years.reshape(-1,1)) return reg.coef_[0], reg.intercept_, y_fit, future_years, y_future def mann_kendall(y): t = np.arange(len(y)) tau, p = kendalltau(t, y) return tau, p series_list = ["theta" ,"ecc" ,"di" ,"phi" ] out = {} for name in series_list: s = df [name].values years = df ["year" ].values slope, intercept, y_fit, fy, y_pred = ols_forecast(years, s, years_ahead=5) tau, p = mann_kendall(s) out[name] = { "ols_slope_per_year" : slope, "kendall_tau" : tau, "kendall_p" : p, "future_years" : fy, "future_pred" : y_pred } print ("趋势分析结果:" )for name, res in out.items(): print (f"=== {name} ===" ) print (f"OLS 斜率: {res['ols_slope_per_year']:.4f} /年" ) print (f"Mann-Kendall τ: {res['kendall_tau']:.4f}, p值: {res['kendall_p']:.4f}" ) print (f"未来预测: {list(zip(res['future_years'], res['future_pred']))}" ) trend_df = [] for name, res in out.items(): for year, pred in zip(res['future_years' ], res['future_pred' ]): trend_df.append([name, year, pred]) trend_df = pd.DataFrame(trend_df, columns=["name" , "year" , "pred" ]) trend_df.to_csv("problem3_trend.csv" , index=False)