Lifestyle_and_Health_Risk_Prediction_Synthetic_Dataset

数据来源
https://www.kaggle.com/datasets/miadul/lifestyle-and-health-risk-prediction
查看数据
1 | import pandas as pd |
1 | df.info() |
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 5000 entries, 0 to 4999
Data columns (total 12 columns):Column Non-Null Count Dtype
0 age 5000 non-null int64
1 weight 5000 non-null int64
2 height 5000 non-null int64
3 exercise 5000 non-null object
4 sleep 5000 non-null float64
5 sugar_intake 5000 non-null object
6 smoking 5000 non-null object
7 alcohol 5000 non-null object
8 married 5000 non-null object
9 profession 5000 non-null object
10 bmi 5000 non-null float64
11 health_risk 5000 non-null object
dtypes: float64(2), int64(3), object(7)
memory usage: 468.9+ KB
缺失值查看和处理
1 | df.isnull().sum() |
age 0
weight 0
height 0
exercise 0
sleep 0
sugar_intake 0
smoking 0
alcohol 0
married 0
profession 0
bmi 0
health_risk 0
dtype: int64
异常值查看与处理
1 | for column in df.select_dtypes(include=['number']).columns: |
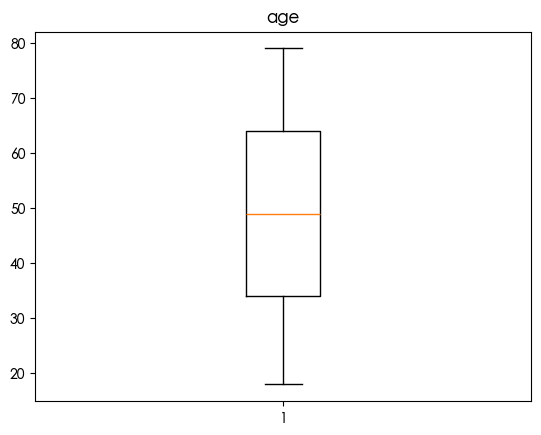
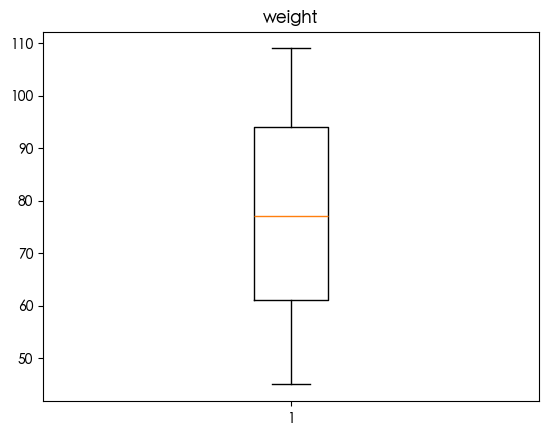
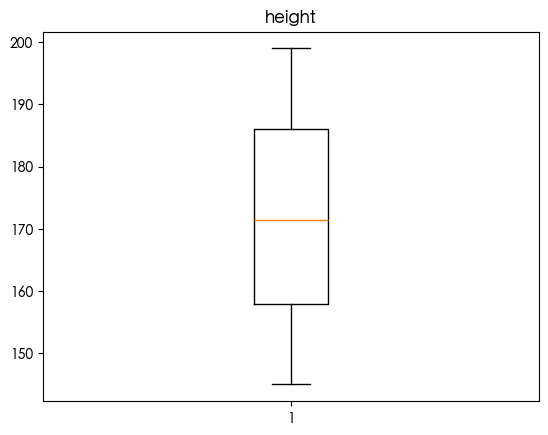
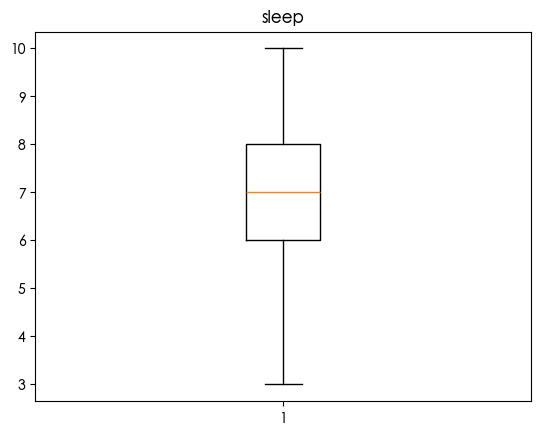
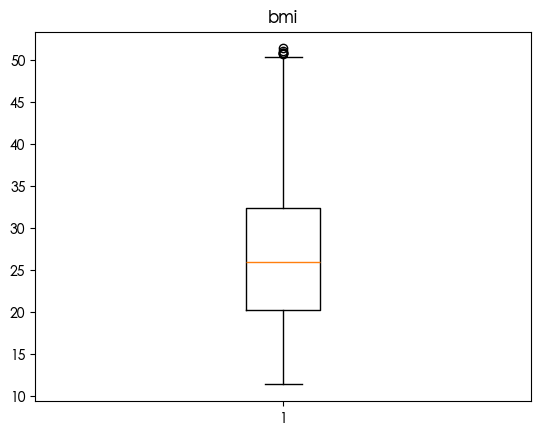
发现bmi存在异常值 鉴于bmi过高会导致健康风险 查看两者的关系
1 | import seaborn as sns |
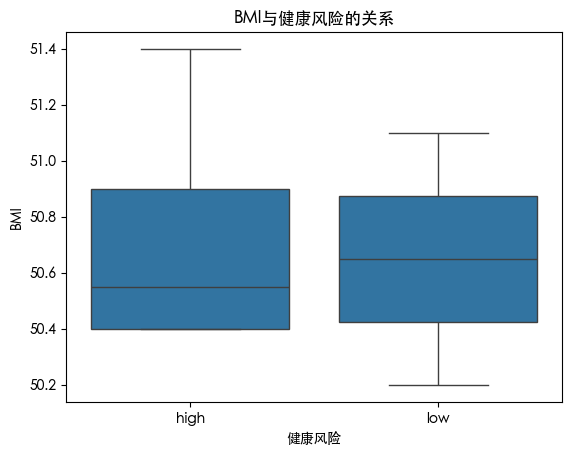
可以看到 健康风险较高的人群 其bmi最大值较高 但是在bmi>50的人群中 健康风险低的人群 bmi平均值要比健康风险高的人群高 这说明 衡量健康风险不仅仅看bmi 还要考虑其他因素
EDA
1 | df['profession'].value_counts().plot(kind='bar') |
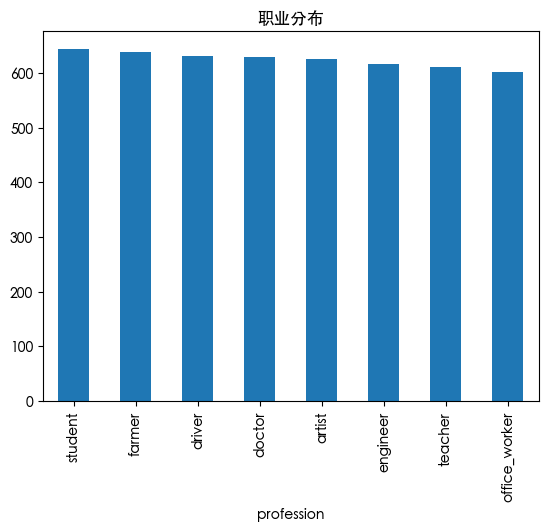
数据集中不同职业的数量分布是均衡的
1 | age_groups = pd.cut(df['age'], bins=5) |
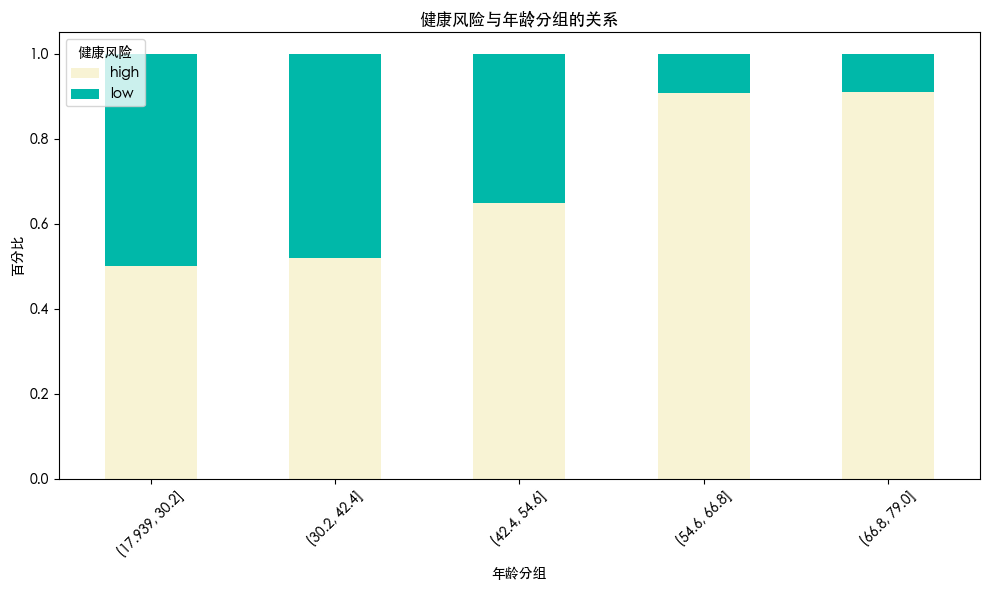
可以看到 随着年龄的增加 健康风险也在增加
1 | import pandas as pd |
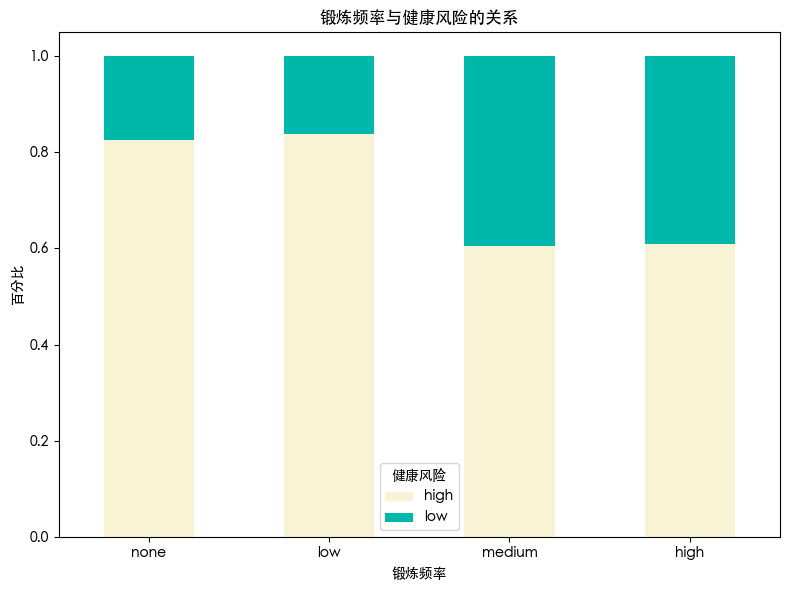
发现 锻炼频率高的人群 健康风险有明显的降低
1 | sleep_groups = pd.cut(df['sleep'], bins=5) |
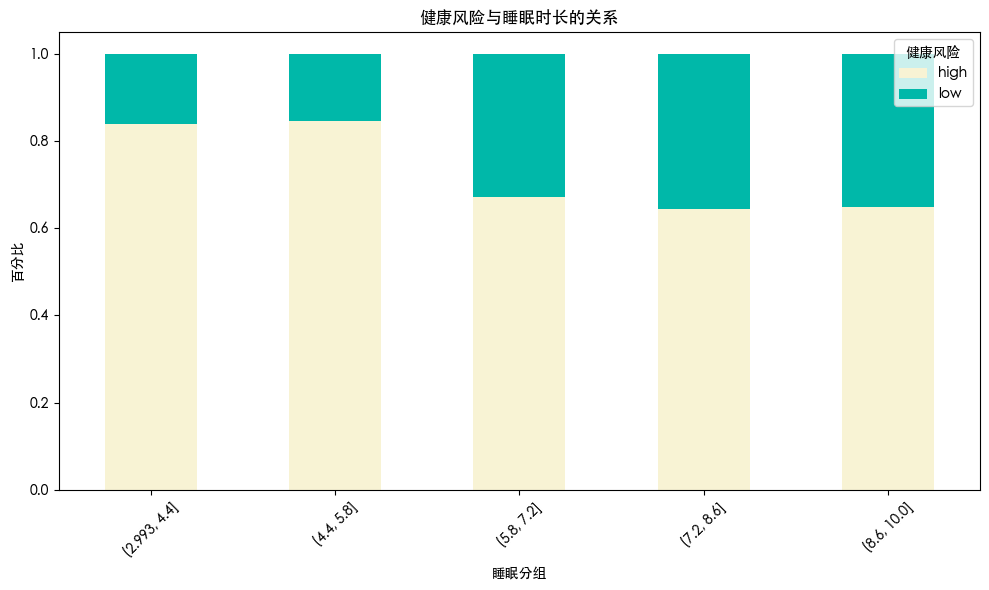
发现 睡眠时长长的人群 健康风险更低
更长的睡眠时间说明其睡眠质量更好 休息得更充分 这有助于提高健康水平
1 | import pandas as pd |
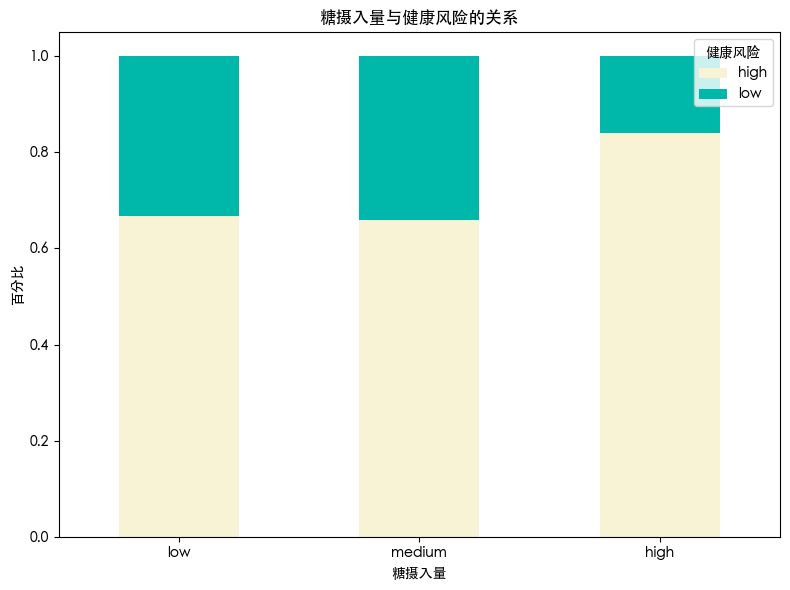
发现 糖摄入量高的人群 其健康风险更高 这可能是因为糖对身体的影响更大 会有患糖尿病的风险 导致健康风险增加
1 | ct = pd.crosstab(df['smoking'], df['health_risk']) |
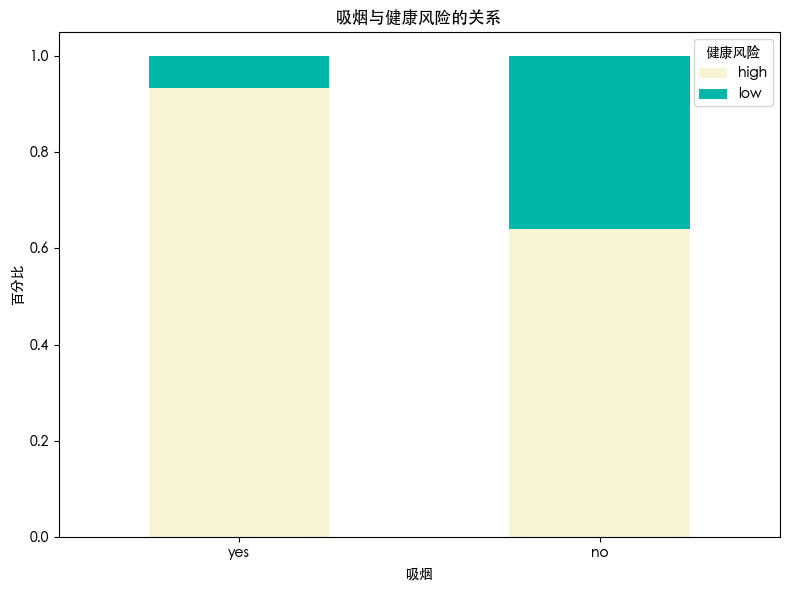
发现 不吸烟的人健康风险要比吸烟人的健康风险低
吸烟有患肺癌的风险
1 | ct = pd.crosstab(df['alcohol'], df['health_risk']) |
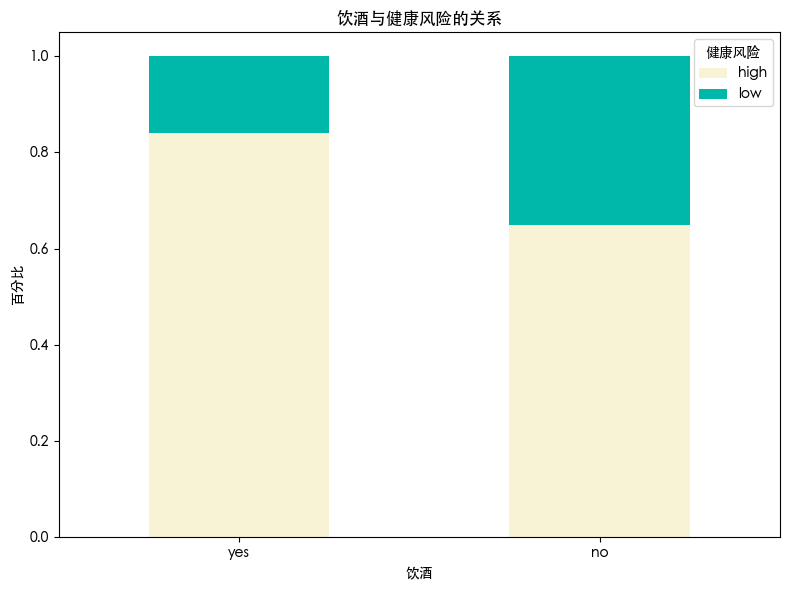
发现 不饮酒的人健康风险要比饮酒的人健康风险低
饮酒有患肝脏疾病的风险
1 | ct = pd.crosstab(df['married'], df['health_risk']) |
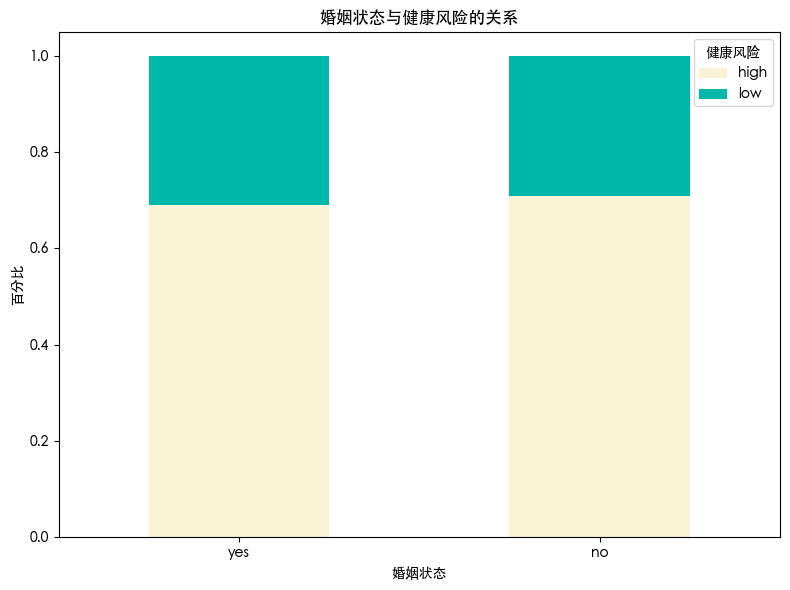
婚姻状况与健康风险的关系不明显 可以把这个特征删除
特征编码
对于exercise、sugar_intake、smoking、alcohol、married、health_risk
这些类别型特征是有明显大小关系的 因此使用标签编码保留其大小区别
对于profession由于特征中的值是无关的 并且特征中的唯一值只有8个 因此我们可以用独热编码
1 | #标签编码 |
1 | # 删除'married'列 |
数据划分
1 | from sklearn.model_selection import train_test_split |
模型选择
1 | from sklearn.linear_model import LogisticRegression |
1 | from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score,classification_report,confusion_matrix |
k折交叉验证
1 | from sklearn.model_selection import cross_val_score |
1 | model_scores.head() |
| Model | Accuracy | Precision | Recall | F1_Score | Cross_Val_Score |
|---|---|---|---|---|---|
| logistic_regression | 0.858 | 0.893056 | 0.908192 | 0.90056 | 0.8652 |
| random_forest | 0.99 | 0.992938 | 0.992938 | 0.992938 | 0.993 |
| svm | 0.804 | 0.829897 | 0.909605 | 0.867925 | 0.8076 |
| XGB | 0.995 | 0.997171 | 0.995763 | 0.996466 | 0.9966 |
| LGBM | 0.997 | 0.997179 | 0.998588 | 0.997883 | 0.9968 |
特征重要性
1 | name = ['random_forest', 'XGB', 'LGBM'] |
random_forest模型特征重要性排序
age 0.268261
bmi 0.182540
smoking 0.100002
exercise 0.094879
sleep 0.085877
weight 0.079399
sugar_intake 0.065287
alcohol 0.063469
height 0.038578
profession_teacher 0.003532
profession_doctor 0.003400
profession_student 0.003397
profession_engineer 0.003007
profession_driver 0.002944
profession_farmer 0.002875
profession_office_worker 0.002553
dtype: float64
XGB模型特征重要性排序
bmi 0.198563
smoking 0.173180
age 0.148690
alcohol 0.139040
exercise 0.122766
sugar_intake 0.114938
sleep 0.075064
profession_doctor 0.007731
profession_engineer 0.005987
profession_student 0.004006
profession_farmer 0.002454
profession_driver 0.002379
weight 0.002147
height 0.001987
profession_teacher 0.001068
profession_office_worker 0.000000
dtype: float32
LGBM模型特征重要性排序
sleep 614
sugar_intake 416
exercise 406
smoking 371
bmi 339
alcohol 337
age 298
height 99
weight 66
profession_doctor 14
profession_engineer 10
profession_farmer 10
profession_student 8
profession_teacher 7
profession_driver 5
profession_office_worker 0
dtype: int32
- Title: Lifestyle_and_Health_Risk_Prediction_Synthetic_Dataset
- Author: 姜智浩
- Created at : 2025-10-21 11:45:14
- Updated at : 2025-10-21 19:41:09
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/10/21/20251021Lifestyle_and_Health_Risk_Prediction/
- License: This work is licensed under CC BY-NC-SA 4.0.