商业数据分析--产品评价

声明
本文代码均保存在
https://github.com/super-213/business_data_analysis
有需要的可以自行下载
查看数据
1 | import pandas as pd |
分词
1 | def clean_text(text): |
TF-IDF
1 | # TF-IDF特征 |
数据划分
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
模型
1 | from sklearn.naive_bayes import MultinomialNB |
模型:朴素贝叶斯
准确率: 0.875
precision recall f1-score support0 1.00 0.70 0.83 91 1 0.82 1.00 0.90 125 accuracy 0.88 216macro avg 0.91 0.85 0.86 216
weighted avg 0.90 0.88 0.87 216模型:逻辑回归
准确率: 0.9814814814814815
precision recall f1-score support0 0.97 0.99 0.98 91 1 0.99 0.98 0.98 125 accuracy 0.98 216macro avg 0.98 0.98 0.98 216
weighted avg 0.98 0.98 0.98 216模型:支持向量机
准确率: 0.9629629629629629
precision recall f1-score support0 0.93 0.99 0.96 91 1 0.99 0.94 0.97 125 accuracy 0.96 216macro avg 0.96 0.97 0.96 216
weighted avg 0.96 0.96 0.96 216模型:随机森林
准确率: 0.9768518518518519
precision recall f1-score support0 0.96 0.99 0.97 91 1 0.99 0.97 0.98 125 accuracy 0.98 216macro avg 0.97 0.98 0.98 216
weighted avg 0.98 0.98 0.98 216模型:XGBoost
准确率: 0.9675925925925926
precision recall f1-score support0 0.94 0.99 0.96 91 1 0.99 0.95 0.97 125 accuracy 0.97 216macro avg 0.96 0.97 0.97 216
weighted avg 0.97 0.97 0.97 216模型:MLP
准确率: 0.9583333333333334
precision recall f1-score support0 0.93 0.98 0.95 91 1 0.98 0.94 0.96 125 accuracy 0.96 216macro avg 0.96 0.96 0.96 216
weighted avg 0.96 0.96 0.96 216
CNN
1 | import pandas as pd |
测试集准确率: 0.9676
1/1 ━━━━━━━━━━━━━━━━━━━━ 1s 681ms/step
(‘好评’, 0.999203622341156)
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step
(‘差评’, 0.03876214474439621)
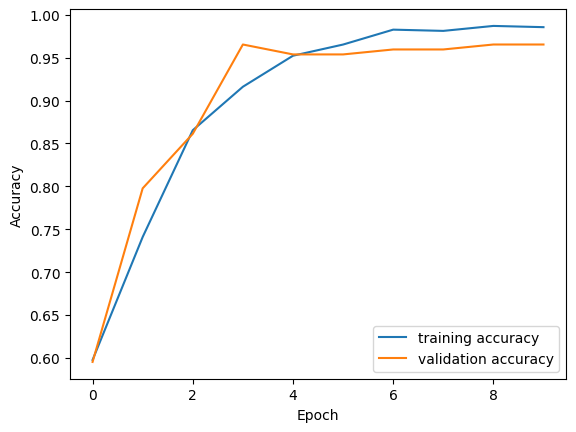
1 | import matplotlib.pyplot as plt |
- Title: 商业数据分析--产品评价
- Author: 姜智浩
- Created at : 2025-10-09 11:45:14
- Updated at : 2025-10-09 12:21:14
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/10/09/20251009商业数据分析--产品评价/
- License: This work is licensed under CC BY-NC-SA 4.0.