商业数据分析--中医辨证

声明
本文代码均保存在
https://github.com/super-213/business_data_analysis
有需要的可以自行下载
查看数据
1 | df = pd.read_excel('中医辨证.xlsx') |
| 病人编号 | 病人症状 |
|---|---|
| 1 | 消化不良,便秘 |
| 2 | 心悸,失眠 |
| 3 | 腰疼,脱发,眼干 |
| 4 | 腹胀,便秘,哮喘,胸闷气短,消化不良 |
| 5 | 神经衰弱,失眠,月经不调 |
数据处理
1 | transactions = [] |
Apriori
原理
Apriori 基于向下封闭原则
如果一个项集是频繁的,那么它的所有子集也一定是频繁的
如果一个项集不是频繁的,那么它的所有超集也不可能频繁
我们先找出每个单个症状出现的频率
然后只保留出现频率高(支持度高)的症状
再用它们组合成双项、三项……,逐步扩展
并在每次扩展时剪枝,减少不可能频繁的组合
代码
1 | for i in results: # 遍历results中的每一个频繁项集 |
FP-Growth
原理
Apriori 的问题是“候选项集太多”,计算量指数级增加。
FP-Growth 采用 压缩存储 和 模式增长 思想:
- 把所有样本转成一棵频繁模式树(FP-Tree),只存出现次数;
- 然后从树结构中“挖”出所有频繁项集,而不用穷举所有组合。
这样可以极大提升效率,尤其在上千条病例时,FP-Growth 比 Apriori 快 10~100 倍。
代码
1 | from mlxtend.frequent_patterns import apriori, fpgrowth, association_rules |
| antecedents | consequents | antecedent support | consequent support | support | confidence | lift | representativity | leverage | conviction | zhangs_metric | jaccard | certainty | kulczynski |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (腹胀, 消化不良) | (便秘) | 0.076 | 0.184 | 0.076 | 1.000000 | 5.434783 | 1.0 | 0.062016 | inf | 0.883117 | 0.413043 | 1.000000 | 0.706522 |
| (腹胀) | (便秘, 消化不良) | 0.092 | 0.160 | 0.076 | 0.826087 | 5.163043 | 1.0 | 0.061280 | 4.830000 | 0.888013 | 0.431818 | 0.792961 | 0.650543 |
| (胸闷气短) | (哮喘) | 0.140 | 0.124 | 0.088 | 0.628571 | 5.069124 | 1.0 | 0.070640 | 2.3 |
Word2Vec
原理
Word2Vec 是一种词嵌入模型(embedding),最初用于自然语言处理。
思想非常简单:
如果两个词经常出现在相同的上下文中,它们的意义就可能相似。
这就是分布式语义假设(Distributional Hypothesis)。
模型通过两种方式学习:
CBOW(Continuous Bag of Words):用周围词预测中间词;
Skip-gram:用当前词预测周围词
训练后,每个词(症状)都会得到一个向量表示
向量之间的余弦相似度代表症状的语义相似度
如果我们把每个病例当作一句话,症状当作词语,Word2Vec 就能学出“哪些症状经常一起出现”的语义模式
例如模型可能学出
头痛 与 眩晕 相似度高(0.89)
咳嗽 与 咽干 相似度高(0.84)
说明它们经常一起出现,甚至可以作为同一证候的表现。
这种方法从连续分布的角度理解“症状间的语义接近度”,
比 Apriori 的硬规则更柔和、能度量相似强度。
代码
1 | model = Word2Vec(sentences=transactions, vector_size=50, window=3, min_count=1, sg=1) |
与『便秘』最相似的症状:
[(‘哮喘’, 0.32900574803352356), (‘神经衰弱’, 0.30445194244384766), (‘腰疼’, 0.29307475686073303), (‘心悸’, 0.29051631689071655), (‘失眠’, 0.2569029927253723)]
K-Means
原理
K-Means 是一种经典的无监督学习算法。
它的目标是:把样本自动分成 k 个簇,使得同一簇内部相似度高、不同簇之间差异大。
算法步骤:
- 随机选 k 个初始中心;
- 把每个样本分配到距离最近的中心;
- 重新计算各簇的中心;
- 重复直到收敛。
数学目标
在中医理论中,不同病人虽然症状各异,但可以归为几种“证型”:
气滞血瘀型
湿热内蕴型
阴虚火旺型
……
KMeans 可以把患者按照症状向量(One-Hot 形式)聚类,
从而自动分出潜在的证型群体。
之后可以观察每类群体中最常见的症状组合,就能从数据中“还原证候分类”。
代码
1 | from sklearn.cluster import KMeans |
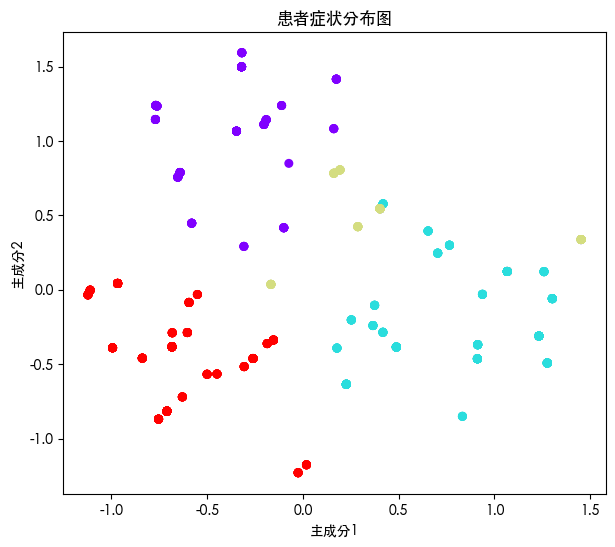
PCA
原理
PCA(Principal Component Analysis)是一种降维算法,
通过线性变换找到数据中最主要的变化方向(主成分)。
核心思想:
找一组正交方向,使得投影后样本的方差最大。
换句话说:
它用尽量少的维度(通常 2~3 个)去保留最多的信息。
症状矩阵维度非常高(每个症状一列),
直接观察不方便。
PCA 可以把这些高维数据投影到二维平面,
让我们直观地看到:
• 不同患者在症状空间中的分布;
• 不同聚类(证型)之间是否分离清晰;
• 哪些症状是主要的区分因素(主成分载荷高的症状)。
这样医生或研究者可以快速识别:
“这群患者的症状模式相似、可能属于同一证型。”
代码
1 | all_symptoms = sorted(list(set(sum(transactions, [])))) |
- Title: 商业数据分析--中医辨证
- Author: 姜智浩
- Created at : 2025-10-09 11:45:14
- Updated at : 2025-10-09 12:20:44
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/10/09/20251009商业数据分析--中医辨证/
- License: This work is licensed under CC BY-NC-SA 4.0.