商业数据分析--股票客户流失

声明
本文代码均保存在
https://github.com/super-213/business_data_analysis
有需要的可以自行下载
查看数据
1 | df = pd.read_excel('股票客户流失.xlsx') |
| 账户资金(元) | 最后一次交易距今时间(天) | 上月交易佣金(元) | 累计交易佣金(元) | 本券商使用时长(年) | 是否流失 |
|---|---|---|---|---|---|
| 22686.5 | 297 | 149.25 | 2029.85 | 0 | 0 |
| 190055.0 | 42 | 284.75 | 3889.50 | 2 | 0 |
| 29733.5 | 233 | 269.25 | 2108.15 | 0 | 1 |
| 185667.5 | 44 | 211.50 | 3840.75 | 3 | 0 |
| 33648.5 | 213 | 353.50 | 2151.65 | 0 | 1 |
查看缺失值情况
1 | df.isnull().sum() |
| 字段名 | 值 |
|---|---|
| 账户资金(元) | 0 |
| 最后一次交易距今时间(天) | 0 |
| 上月交易佣金(元) | 0 |
| 累计交易佣金(元) | 0 |
| 本券商使用时长(年) | 0 |
| 是否流失 | 0 |
查看异常值情况
1 | for col in df.columns: |
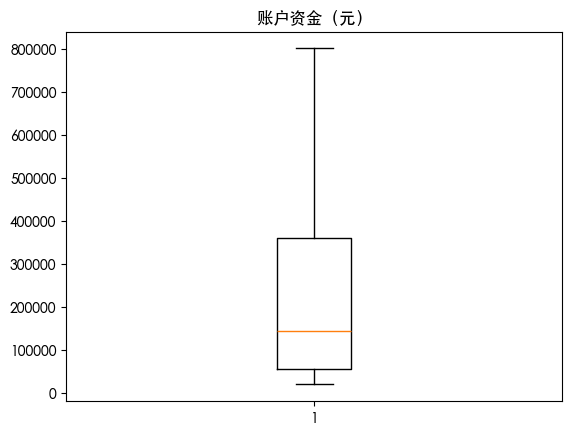
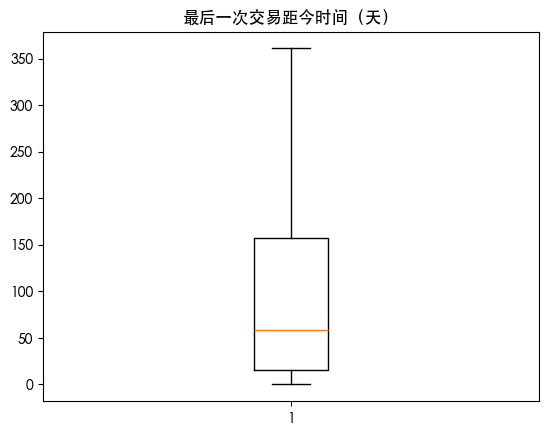
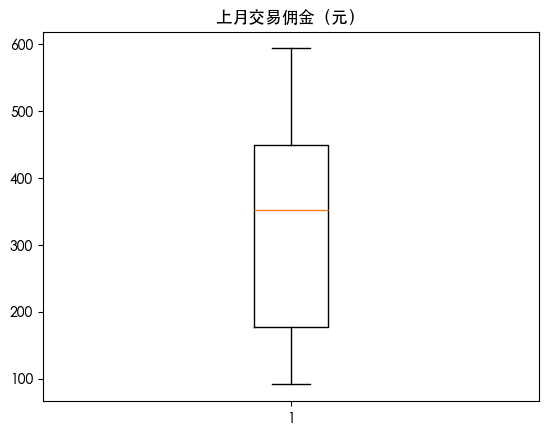
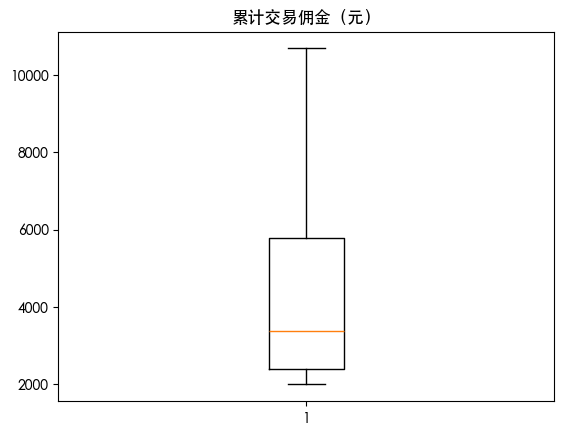
数据划分
1 | from sklearn.model_selection import train_test_split |
逻辑回归
1 | from sklearn.linear_model import LogisticRegression |
准确率 (Accuracy): 0.7949
混淆矩阵 (Confusion Matrix):
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 952 | 84 |
| 1 | 205 | 168 |
分类报告 (Classification Report):
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.82 | 0.92 | 0.87 | 1036 |
| 1 | 0.67 | 0.45 | 0.54 | 373 |
| accuracy | 0.79 | 1409 | ||
| macro avg | 0.74 | 0.68 | 0.70 | 1409 |
| weighted avg | 0.78 | 0.79 | 0.78 | 1409 |
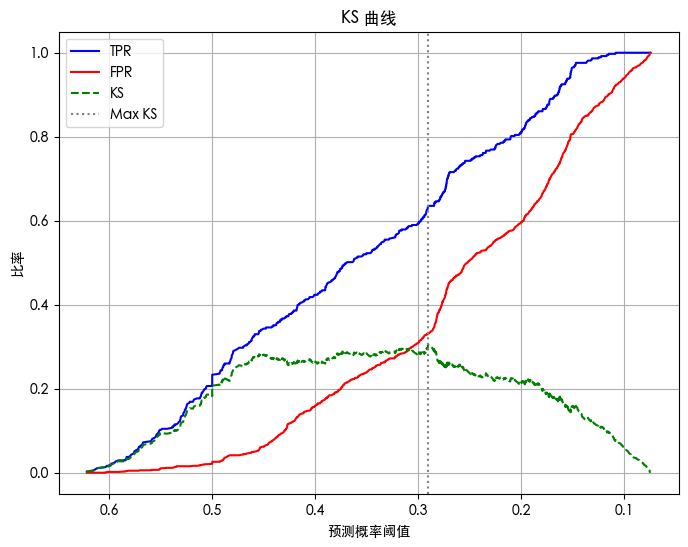
SVM
1 | from sklearn.svm import SVC |
准确率 (Accuracy): 0.7353
KS Score: 0.3043
混淆矩阵 (Confusion Matrix):
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 1036 | 0 |
| 1 | 373 | 0 |
分类报告 (Classification Report):
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.74 | 1.00 | 0.85 | 1036 |
| 1 | 0.00 | 0.00 | 0.00 | 373 |
| accuracy | 0.74 | 1409 | ||
| macro avg | 0.37 | 0.50 | 0.42 | 1409 |
| weighted avg | 0.54 | 0.74 | 0.62 | 1409 |
1 | import matplotlib.pyplot as plt |
KNN
1 | from sklearn.neighbors import KNeighborsClassifier |
准确率 (Accuracy): 0.7580
KS Score: 0.3060
混淆矩阵 (Confusion Matrix):
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 940 | 96 |
| 1 | 245 | 128 |
分类报告 (Classification Report):
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.79 | 0.91 | 0.85 | 1036 |
| 1 | 0.57 | 0.34 | 0.43 | 373 |
| accuracy | 0.76 | 1409 | ||
| macro avg | 0.68 | 0.63 | 0.64 | 1409 |
| weighted avg | 0.73 | 0.76 | 0.74 | 1409 |
随机森林
1 | from sklearn.ensemble import RandomForestClassifier |
准确率 (Accuracy): 0.7686
KS Score: 0.4445
混淆矩阵 (Confusion Matrix):
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 909 | 127 |
| 1 | 199 | 174 |
分类报告 (Classification Report):
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.82 | 0.88 | 0.85 | 1036 |
| 1 | 0.58 | 0.47 | 0.52 | 373 |
| accuracy | 0.77 | 1409 | ||
| macro avg | 0.70 | 0.67 | 0.68 | 1409 |
| weighted avg | 0.76 | 0.77 | 0.76 | 1409 |
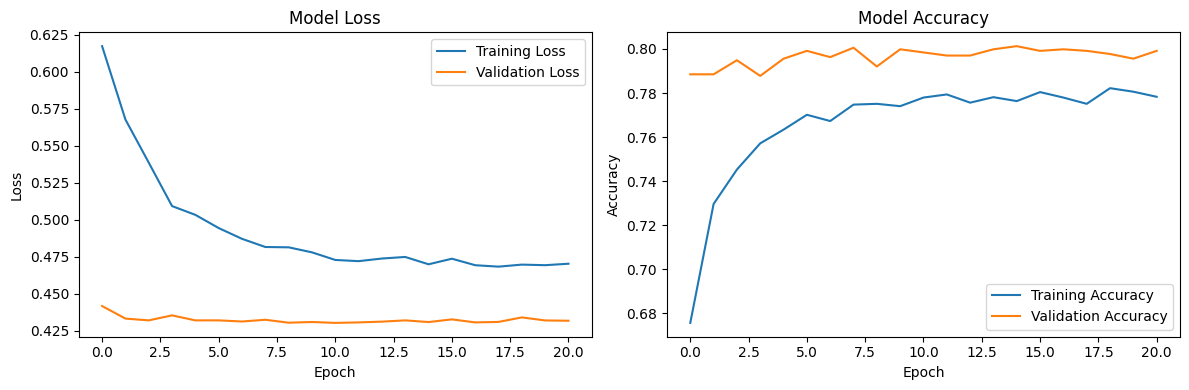
神经网络
1 | scaler = StandardScaler() |
准确率 (Accuracy): 0.7984
AUC: 0.8338
KS Score: 0.5174
混淆矩阵 (Confusion Matrix):
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 959 | 77 |
| 1 | 207 | 166 |
分类报告 (Classification Report):
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.82 | 0.93 | 0.87 | 1036 |
| 1 | 0.68 | 0.45 | 0.54 | 373 |
| accuracy | 0.80 | 1409 | ||
| macro avg | 0.75 | 0.69 | 0.70 | 1409 |
| weighted avg | 0.79 | 0.80 | 0.78 | 1409 |
横向对比
| 指标 | SVC | KNN | Random Forest | Neural Network |
|---|---|---|---|---|
| Accuracy | 0.735 | 0.758 | 0.769 | 0.798 |
| AUC | - | - | - | 0.834 |
| KS Score | 0.304 | 0.306 | 0.444 | 0.517 |
| Class 1 Recall | 0.00 | 0.34 | 0.47 | 0.45 |
| Class 1 F1 | 0.00 | 0.43 | 0.52 | 0.54 |
看起来准确率都还行 但是可以看到召回率最高只有0.47 由于我们是要分析预测股票客户流失 因此 我们得着重提高召回率
以神经网络为例 使用class_weight
1 | # 计算类别权重 |
准确率 (Accuracy): 0.7459
AUC: 0.8336KS Score: 0.5153
混淆矩阵 (Confusion Matrix):
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 778 | 258 |
| 1 | 100 | 273 |
分类报告 (Classification Report):
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.89 | 0.75 | 0.81 | 1036 |
| 1 | 0.51 | 0.73 | 0.60 | 373 |
| accuracy | 0.75 | 1409 | ||
| macro avg | 0.70 | 0.74 | 0.71 | 1409 |
| weighted avg | 0.79 | 0.75 | 0.76 | 1409 |
可以看到 尽管准确率有所降低 但是召回率大幅提高到了0.73 说明模型对真实流失客户的预测准确率提高了
XGBoost
对于不平衡的样本 我们还可以使用像XGBoost或者lightGBM
1 | from xgboost import XGBClassifier |
准确率 (Accuracy): 0.812
KS Score: 0.538
混淆矩阵 (Confusion Matrix):
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 【如 920】 | 【如 116】 |
| 1 | 【如 150】 | 【如 223】 |
分类报告 (Classification Report):
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 【如 0.86】 | 【如 0.89】 | 【如 0.87】 | 1036 |
| 1 | 【如 0.66】 | 【如 0.60】 | 【如 0.63】 | 373 |
| accuracy | 【如 0.81】 | 1409 | ||
| macro avg | 【如 0.76】 | 【如 0.74】 | 【如 0.75】 | 1409 |
| weighted avg | 【如 0.80】 | 【如 0.81】 | 【如 0.80】 | 1409 |
- Title: 商业数据分析--股票客户流失
- Author: 姜智浩
- Created at : 2025-09-23 11:45:14
- Updated at : 2025-09-23 10:02:49
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/09/23/20250923商业数据分析--股票客户流失/
- License: This work is licensed under CC BY-NC-SA 4.0.