糖尿病预测分析

数据描述
心血管病、糖尿病等慢性疾病,每年导致的死亡人数占总死亡人数的80%,每年用于慢病医疗费用占中国公共医疗卫生支出的比例超过13%。作为一种常见慢性疾病,糖尿病目前无法根治,但通过科学有效的干预、预防和治疗,能降低发病率和提高患者的生活质量。本课题拟对UCI的糖尿病诊断数据集进行机器学习建模分析,在此基础上探讨诱发糖尿病的重要病因
过程
导入库
1 | import pandas as pd |
1 | import data_analysis_tools as dat #我自己创建的库 |
查看数据
1 | df=pd.read_csv('pima-indians-diabetes.data.csv') |
{‘head’: 6 148 72 35 0 33.6 0.627 50 1 Unnamed: 9
0 1.0 85.0 66.0 29.0 0.0 26.6 0.351 31.0 0.0 NaN
1 8.0 183.0 64.0 0.0 0.0 23.3 0.672 32.0 1.0 NaN
2 1.0 89.0 66.0 23.0 94.0 28.1 0.167 21.0 0.0 NaN
3 0.0 137.0 40.0 35.0 168.0 43.1 2.288 33.0 1.0 NaN
4 5.0 116.0 74.0 0.0 0.0 25.6 0.201 30.0 0.0 NaNUnnamed: 10 Unnamed: 11 Unnamed: 120 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 NaN NaN NaN
4 NaN NaN NaN ,
‘tail’: 6 148 72 35 0 33.6 0.627 50 1 Unnamed: 9 Unnamed: 10
772 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
773 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
774 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
775 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
776 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaNUnnamed: 11 Unnamed: 12772 NaN # 5. 2-Hour serum insulin (mu U/ml)
773 NaN # 6. Body mass index (weight in kg/(height in …
774 NaN # 7. Diabetes pedigree function
775 NaN # 8. Age (years)
776 NaN # 9. Class variable (0 or 1) ,
‘describe’: 6 148 72 35 0
count 767.000000 767.000000 767.000000 767.000000 767.000000
unique NaN NaN NaN NaN NaN
top NaN NaN NaN NaN NaN
freq NaN NaN NaN NaN NaN
mean 3.842243 120.859192 69.101695 20.517601 79.903520
std 3.370877 31.978468 19.368155 15.954059 115.283105
min 0.000000 0.000000 0.000000 0.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000
50% 3.000000 117.000000 72.000000 23.000000 32.000000
75% 6.000000 140.000000 80.000000 32.000000 127.500000
max 17.000000 199.000000 122.000000 99.000000 846.00000033.6 0.627 50 1 Unnamed: 9 \count 767.000000 767.000000 767.000000 767.000000 0.0
unique NaN NaN NaN NaN NaN
top NaN NaN NaN NaN NaN
freq NaN NaN NaN NaN NaN
mean 31.990482 0.471674 33.219035 0.348110 NaN
std 7.889091 0.331497 11.752296 0.476682 NaN
min 0.000000 0.078000 21.000000 0.000000 NaN
25% 27.300000 0.243500 24.000000 0.000000 NaN
50% 32.000000 0.371000 29.000000 0.000000 NaN
75% 36.600000 0.625000 41.000000 1.000000 NaN
max 67.100000 2.420000 81.000000 1.000000 NaNUnnamed: 10 Unnamed: 11 Unnamed: 12count 0.0 0.0 9
unique NaN NaN 9
top NaN NaN # 1. Number of times pregnant
freq NaN NaN 1
mean NaN NaN NaN
std NaN NaN NaN
min NaN NaN NaN
25% NaN NaN NaN
50% NaN NaN NaN
75% NaN NaN NaN
max NaN NaN NaN ,
‘info’: “<class ‘pandas.core.frame.DataFrame’>\nRangeIndex: 777 entries, 0 to 776\nData columns (total 13 columns):\n # Column Non-Null Count Dtype \n— —— ————– —– \n 0 6 767 non-null float64\n 1 148 767 non-null float64\n 2 72 767 non-null float64\n 3 35 767 non-null float64\n 4 0 767 non-null float64\n 5 33.6 767 non-null float64\n 6 0.627 767 non-null float64\n 7 50 767 non-null float64\n 8 1 767 non-null float64\n 9 Unnamed: 9 0 non-null float64\n 10 Unnamed: 10 0 non-null float64\n 11 Unnamed: 11 0 non-null float64\n 12 Unnamed: 12 9 non-null object \ndtypes: float64(12), object(1)\nmemory usage: 79.0+ KB\n”,
‘dtypes’: 6 float64
148 float64
72 float64
35 float64
0 float64
33.6 float64
0.627 float64
50 float64
1 float64
Unnamed: 9 float64
Unnamed: 10 float64
Unnamed: 11 float64
Unnamed: 12 object
dtype: object,
‘missing’: 6 10
148 10
72 10
35 10
0 10
33.6 10
0.627 10
50 10
1 10
Unnamed: 9 777
Unnamed: 10 777
Unnamed: 11 777
Unnamed: 12 768
dtype: int64}
通过上述查看,我们得知此数据集的特征描述在文件的右下角,我们将字段名称补充进去
我们首先得到列名
df.columns.tolist()
[‘6’,
‘148’,
‘72’,
‘35’,
‘0’,
‘33.6’,
‘0.627’,
‘50’,
‘1’,
‘Unnamed: 9’,
‘Unnamed: 10’,
‘Unnamed: 11’,
‘Unnamed: 12’]
1 | df.drop([ 'Unnamed: 9', |
1 | df.head() |
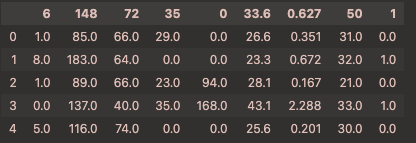
1 | df.info() |
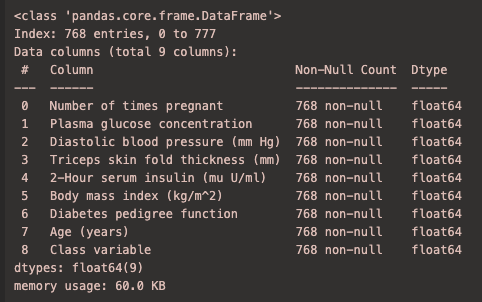
1 | columns = [ |
1 | df=pd.read_csv('new_pima-indians-diabetes.data.csv') |
从之前的输出中我们可以看到有空白行 将其删除
1 | df = df.dropna(how='all') |
1 | df.isnull().sum() |
Number of times pregnant 0
Plasma glucose concentration 0
Diastolic blood pressure (mm Hg) 0
Triceps skin fold thickness (mm) 0
2-Hour serum insulin (mu U/ml) 0
Body mass index (kg/m^2) 0
Diabetes pedigree function 0
Age (years) 0
Class variable 0
dtype: int64
- Number of times pregnant
- 怀孕次数
- Plasma glucose concentration a 2 hours in an oral glucose tolerance test
- 口服葡萄糖耐量试验中 2 小时的血浆葡萄糖浓度
- Diastolic blood pressure (mm Hg)
- 舒张压(毫米汞柱)
- Triceps skin fold thickness (mm)
- 三头肌皮褶厚度(毫米)
- 2-Hour serum insulin (mu U/ml)
- 2 小时血清胰岛素(微单位/毫升)
- Body mass index (weight in kg/(height in m)^2)
- 体重指数(体重以千克除以身高以米的平方)
- Diabetes pedigree function
- 糖尿病家族史功能
- Age (years)
- 年龄(年)
- Class variable (0 or 1)
- 类别变量(0 或 1)
1 | df.describe() |
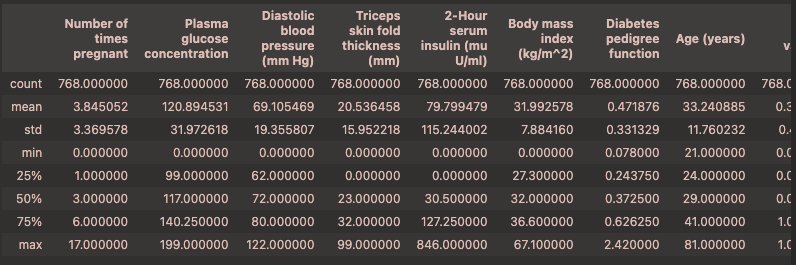
从min中看到,有0元素,像是Diastolic blood pressure (mm Hg)之类的特征不应该存在0
说明这是缺失值,用均值填充
1 | columns = ['Plasma glucose concentration', |
接下来我们查看是否存在异常值 通过查询相关信息,得到了以下结果
- Number of times pregnant (怀孕次数)
正常范围 :0 到任意正整数。
解释 :这是一个计数字段,表示一个人怀孕的次数。通常没有上限,但常见的范围是 0 到 15 次(极少数情况下可能更高)。 - Plasma glucose concentration a 2 hours in an oral glucose tolerance test (口服葡萄糖耐量试验中 2 小时的血浆葡萄糖浓度)
单位 :mg/dL 或 mmol/L
正常范围 :
正常:小于 140 mg/dL(7.8 mmol/L)
空腹血糖受损(IFG)或糖耐量受损(IGT):140-199 mg/dL(7.8-11.1 mmol/L)
糖尿病:大于等于 200 mg/dL(11.1 mmol/L)
解释 :这是诊断糖尿病的重要指标之一。通过口服葡萄糖耐量试验(OGTT),可以评估身体对葡萄糖的代谢能力。 - Diastolic blood pressure (mm Hg) (舒张压,毫米汞柱)
正常范围 :60-80 mm Hg
异常范围 :
高血压前期:80-89 mm Hg
高血压:大于等于 90 mm Hg
低血压:小于 60 mm Hg
解释 :舒张压是指心脏放松时血管内的压力。长期高血压可能导致心血管疾病。 - Triceps skin fold thickness (mm) (三头肌皮褶厚度,毫米)
正常范围 (因性别和年龄而异):
男性:约 10-15 mm
女性:约 15-25 mm
解释 :三头肌皮褶厚度用于估算体脂百分比。较高的值可能表明较高的体脂水平。 - 2-Hour serum insulin (mu U/ml) (2 小时血清胰岛素,微单位/毫升)
正常范围 :小于 30 mu U/ml
解释 :胰岛素是调节血糖的关键激素。高胰岛素水平可能表明胰岛素抵抗或糖尿病前期。 - Body mass index (BMI) (体重指数,kg/m²)
正常范围 :18.5-24.9
分类 :
低于 18.5:体重过轻
18.5-24.9:正常体重
25-29.9:超重
大于等于 30:肥胖
解释 :BMI 是衡量体重是否健康的常用指标,但它不考虑肌肉质量等因素。 - Diabetes pedigree function (糖尿病家族史功能)
单位 :无单位(通常是概率值)
正常范围 :0 到 1
解释 :这是一个计算值,表示患糖尿病的概率。值越高,患糖尿病的风险越大。具体范围因模型而异,但通常在 0 到 1 之间。
通过查看 没有存在那种明显超过人类水平的异常值
EDA
1 | dat.plot_all_barplots(df, hue='Class variable') |
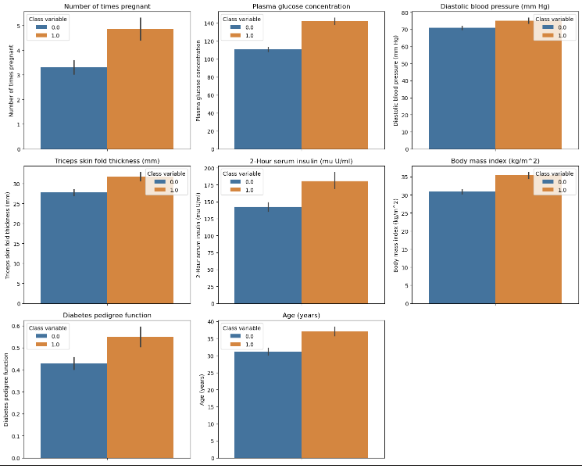
可以看到 有糖尿病的患者各项指标均比非糖尿病的患者高
1 | df.corr() |
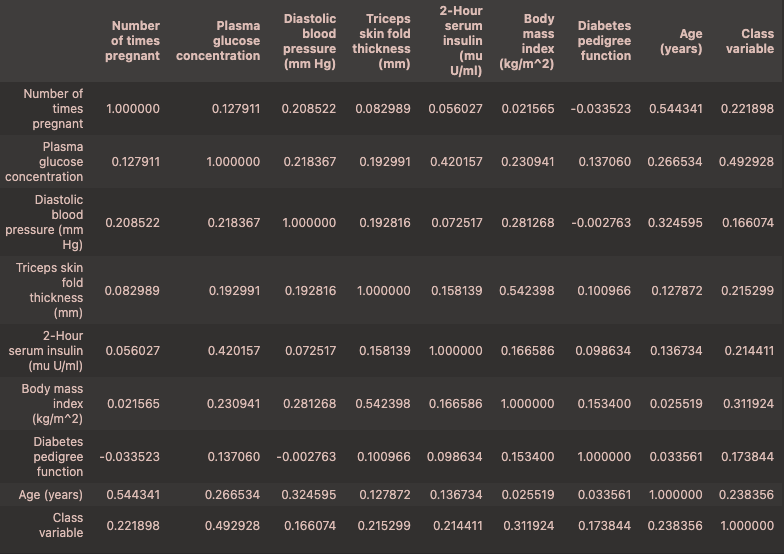
我们重点关系class variable行 可以看到 Plasma glucose concentration的相关性最高,为0.492928 但仍然不能算作强相关
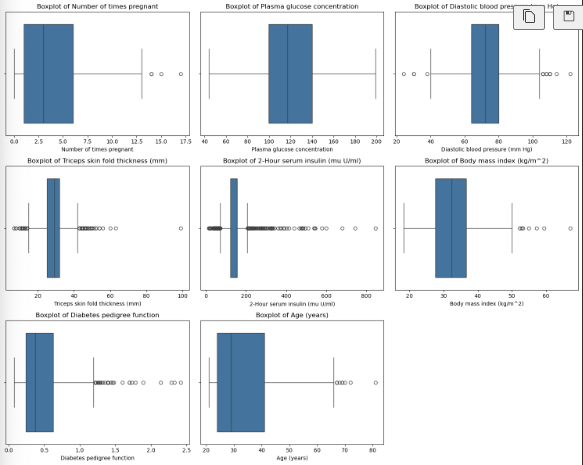
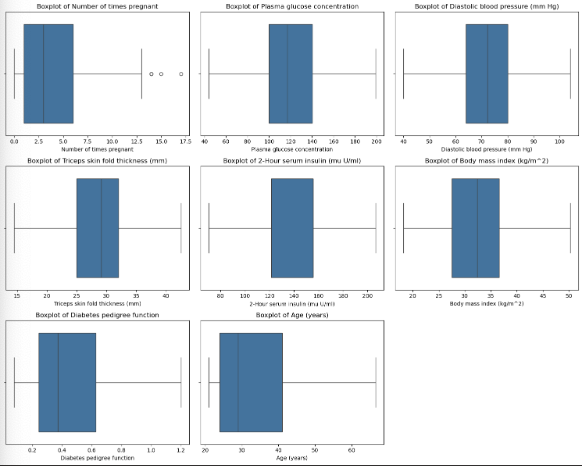
尽管数据中的值在真实世界中都是合理的 但一些特别大的值在进行机器学习时会影响模型的泛化能力,使用IQR方法将异常值替换成边界值
1 | dat.plot_all_boxplots(df,exclude_columns=['Class variable']) |
数据划分
1 | X = df.drop(columns=['Class variable']) |
标准化
1 | dat.plot_feature_distributions(df) |
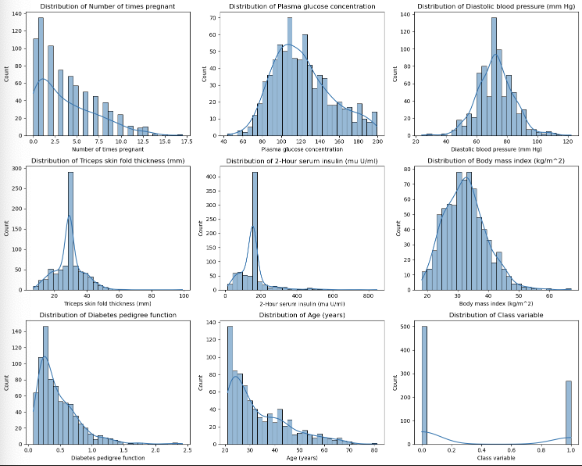
1 | dat.detect_skewness(df) |
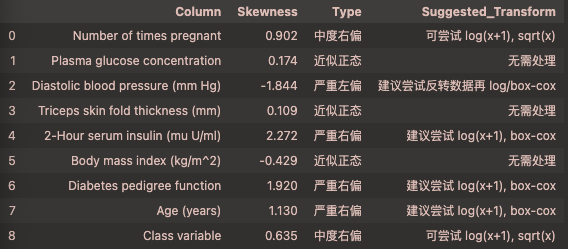
1 | std = dat.DataStandardizer(method='boxcox', cols=['Number of times pregnant', |
模型选择
1 | models = { |
1 | # 初始化结果字典 |
模型: RandomForestClassifier
准确率: 0.7597
分类报告:
precision recall f1-score support
0.0 0.79 0.84 0.81 97
1.0 0.69 0.63 0.66 57
accuracy 0.76 154
macro avg 0.74 0.73 0.74 154
weighted avg 0.76 0.76 0.76 154
模型: LogisticRegression
准确率: 0.7468
分类报告:
precision recall f1-score support
0.0 0.83 0.75 0.79 97
1.0 0.64 0.74 0.68 57
accuracy 0.75 154
macro avg 0.73 0.74 0.74 154
weighted avg 0.76 0.75 0.75 154
模型: SVM
准确率: 0.5779
分类报告:
precision recall f1-score support
0.0 0.68 0.62 0.65 97
1.0 0.44 0.51 0.47 57
accuracy 0.58 154
macro avg 0.56 0.56 0.56 154
weighted avg 0.59 0.58 0.58 154
模型: KNN
准确率: 0.6558
分类报告:
precision recall f1-score support
0.0 0.71 0.77 0.74 97
1.0 0.54 0.46 0.50 57
accuracy 0.66 154
macro avg 0.62 0.61 0.62 154
weighted avg 0.65 0.66 0.65 154
模型: XGBoost
准确率: 0.7597
分类报告:
precision recall f1-score support
0.0 0.82 0.79 0.81 97
1.0 0.67 0.70 0.68 57
accuracy 0.76 154
macro avg 0.74 0.75 0.75 154
weighted avg 0.76 0.76 0.76 154
优化
由于我们是要预测糖尿病,要做到减少漏诊,因此我们更关心召回率,提高召回率,精确率不必在意
随机森林的优化
1 | # 定义参数搜索空间 |
XGBoost的优化
1 | # 计算类别不平衡比例,用于 scale_pos_weight |
打印最佳召回率
1 | best_rf = opt.best_estimator_ |
Recall: 0.7719298245614035
Test Recall: 0.7719298245614035
- Title: 糖尿病预测分析
- Author: 姜智浩
- Created at : 2025-05-18 11:45:14
- Updated at : 2025-05-21 20:07:19
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/05/18/20250518糖尿病预测分析/
- License: This work is licensed under CC BY-NC-SA 4.0.