基于供应链数据协同的服装外贸企业准交率优化研究

基于供应链数据协同的服装外贸企业准交率优化研究
摘要
准时交付是服装外贸企业维系客户信任与市场竞争力的核心指标,然而其受多重供应链因素交织影响,传统经验式管理难以实现精准优化。本研究基于某企业2020–2025年数据,融合结构化业务记录与非结构化文本,系统探究准交率影响机制并提出优化路径。研究发现:
企业整体交付时差分布呈现典型右偏态,部分订单存在严重延迟。
延迟成因具有显著多源并发性:一级延迟、质量问题返工、三级延迟、二级延迟与样品批复滞后五大类原因频次高度接近,表明问题根植于端到端流程断裂,而非单一环节失效。
供应商能力结构决定其价值层级:高绩效者以交付表现为主,多维均衡;中游者依赖质量与配合度维持总分;尾部者则呈质量、准时性双低脆弱结构,亟需干预或淘汰。
使用机器学习模型预测交准率,随机森林模型以最优综合性能成为推荐模型;特征重要性分析表明:年份、采购金额、数量与月份构成前四大预测因子,而供应商、业务员、款式等操作变量贡献微弱,揭示准交率本质是宏观结构性问题,而非微观执行偏差。
关键词: 准交率;供应链协同;特征重要性
一、 引言
在全球价值链深度重构与数字技术加速渗透的双重驱动下,服装外贸行业正经历前所未有的范式变革。一方面,终端消费需求呈现碎片化、快反化、个性化特征,客户对交付周期的容忍阈值持续收窄;另一方面,地缘政治波动、物流成本高企与可持续合规压力叠加,使得供应链脆弱性显著上升,任意环节的微小扰动均可能引发全局性交付危机。在此背景下,订单准时交付率已从一项基础履约指标,跃升为企业维持国际客户黏性、获取溢价能力乃至生存发展的战略级能力。
然而,现实困境依然严峻。大量服装外贸企业仍囿于订单驱动、被动响应的传统运营模式,突出表现为:信息孤岛林立、预测机制失灵、跨组织协同低效。以典型企业为例,因设计、采购、生产、物流各环节数据割裂,销售预测与产能规划脱节,导致计划外插单频发、生产排程反复调整;供应商绩效缺乏量化评估与动态反馈,优质资源难以精准配置;跟单过程依赖人工记录与经验判断,隐性风险难以及时识别与干预。其直接后果是:准交率长期偏低,大量订单依赖空运等高成本方式补救,隐性成本占营收比重过大,严重侵蚀利润空间;更深远的影响在于,持续的交期失信正系统性削弱中国供应商在全球价值链中的议价地位与品牌声誉。
二、 数据准备与预处理
2.1数据集概述
本研究所使用的数据来自某服装外贸企业的供应链业务系统,涵盖订单从接单、采购、生产、验货到出运的完整流程信息。原始数据以业务记录表的形式呈现,共包含30余项与订单执行相关的特征变量,刻画了供应链协同过程中影响准交率的关键因素。
在众多特征变量中,与订单执行时效密切相关的时间节点构成了准交率研究的核心数据基础。具体来说:
1. 销售交期:
指企业与客户在销售合同中约定的最终交付日期,是衡量订单是否按期完成的基准时间点。销售交期通常由市场需求、客户计划及合同约束共同决定,是准交率评价的参考标准。
2. 采购交期:
指供应商承诺向企业交付原料或半成品的时间节点。该日期反映供应商履约能力,是影响生产启动时间和整体交付进度的关键前置环节。
3. 进仓日期:
指原材料或成品进入企业仓库的实际时间。该字段可以评估从供应商交付到企业接收的实际流转周期。
4. 开船日期:
指订单产品实际发运或装船离港的时间,用于衡量物流执行进度。此日期与销售交期的差异可用于判断出运环节是否存在延误。
5. 查货日期:
指质检人员对订单产品进行现场查验的时间点,是生产完成后进入物流环节前的重要质量控制节点。
6. 产前样批复时间:
指客户或内部审核部门对产前样品的确认时间。
7. 建立日期:
指订单在系统中的首次录入日期,是衡量整个订单生命周期的起始时间。
2.2数据预处理
2.2.1数据清洗
- 币种转换:
在供应链数据处理中,不同记录可能使用不同的币种。为保证后续分析的统一性,需要将采购金额统一转换为人民币:
a. 汇率映射
预先根据公开金融数据制定年度汇率表。当记录中采购币别为USD时,程序会依据订单的年份字段自动选择对应汇率。
b. 年份类型检验
由于原始数据可能存在年份类型混乱,程序首先确保年份字段被转换为整数类型,以保证汇率映射的稳定性。
c. 币别标准化
对采购币别执行大写统一和去除空格处理,以避免文本格式造成的匹配错误。
d. 汇率匹配
程序会检查所有USD记录的年份是否在汇率表中。如果出现未定义年份,将自动提示用户补充汇率数据,以增强代码鲁棒性。
e. 缺失汇率补全
对于无法匹配汇率的年份,程序采用前向填充,若仍存在空值,则使用默认汇率7.0,以确保转换逻辑的完整性。
f. 金额转换
对USD行执行采购金额×汇率的换算,并将对应的采购币别字段更新为 RMB,保证后续分析视角一致。 - 颜色细分:
服装的颜色是十分丰富的,若直接将服装的颜色进行独热编码,可能会导致维度爆炸。为了保证颜色处理的稳定性和可维护性,本研究构建了一个颜色映射表,将颜色列细分为:底色、配色、装饰、其他。
具体构建的方法为:
a. 字段标准化
对业务部门提供的颜色命名方案进行清洗,包括: - 去除重复颜色命名;
- 统一大小写;去除多余空格、特殊符号;
- 校验底色与配色字段不冲突;
- 对缺失信息进行补全或标记。
b. 底色提取
底色是颜色映射中的核心字段,主要依据:
1. 颜色常识:如深蓝、浅蓝其主色均是蓝;
2. 若颜色由两种明显色彩构成,则按主色调确定底色;
3. 对于无法归类的颜色,统一归入其它类别。
c. 配色拆解
对于复合颜色,如:黑+红、白/灰渐变、蓝拼橙。按以下规则提取:
主色对应底色;副色对应配色1;次副色对应配色2。若颜色只有一种色,则配色字段留空。
d. 装饰
对于颜色中存在印花、条纹等,提取并保存。
2.2.2缺失值处理
在原始数据中,部分关键日期字段,如进仓日期、查货日期存在不同程度的缺失。由于这些时间变量反映订单执行过程的重要节点,若直接删除相应样本,将导致有效信息损失并可能引入偏差。因此,采用基于K近邻回归的插补方法对缺失的时间字段进行估计,以最大化保留数据信息并提高模型训练的稳定性。
选择KNN而非均值、中位数或线性回归等传统插补方法,主要基于以下考虑:
1. 非线性关系捕捉能力强
日期间的差值与订单属性之间可能存在复杂的非线性关系,如订单难度高可能导致进仓数日延迟,而KNN能在局部特征空间中捕捉这些关系,更符合供应链数据的业务逻辑。
2. 无需假设数据分布
传统插补方法通常隐含正态性或线性关系假设,而订单执行数据往往具有偏态、离散、批量依赖等特征。KNN作为非参数方法,能在无需依赖分布假设的情况下提供稳健预测。
3. 通过邻域信息增强插补准确性
KNN插补依赖最接近的订单样本进行推断,有利于保持局部结构特征,特别适用于同一品牌、供应商或生产类型下执行节奏相近的样本。
4. 避免全局偏移,提高时间变量可信度
均值、中位数插补会造成日期大规模向某一固定值集中,而KNN预测得到的差值具有更真实的波动性,能更好保持原始数据的分布形态。
针对日期变量的缺失问题,本研究首先将所有与时间相关的字段转换为与开船日期之间的天数差形式。还对销售交期、采购交期、建立日期等时间特征计算了相同的时间差值。
这种差分化处理具有两项优势:
1. 消除了不同订单整体时间尺度差异,使样本在时间维度上具有可比较性;
2. 差分特征通常呈现更平滑的分布,更适合作为KNN回归的输入变量。
2.2.3异常值处理
供应链数据在采集和录入过程中容易受到人为失误、系统记录偏差以及业务流程差异的影响,从而产生异常值。异常值若不加以处理,会对后续的模型训练、统计分析和准交率推断造成明显扰动。因此,本研究基于业务逻辑规则和统计方法相结合的策略,对异常值进行了系统化识别与过滤,确保数据质量的稳定性与可信度。
供应链业务流程具有严格的时间顺序和数量约束,因此基于业务知识进行逻辑异常筛查:
1. 时间逻辑约束:
“进仓日期”不应晚于“开船日期”,因为货物必须先入仓才能安排出运。
“查货日期”不应晚于“开船日期”,质检过程必须在出运之前完成。
对上述条件不满足的记录被视为明显违背流程逻辑,因此予以剔除。
2. 数量逻辑约束:
“数量”字段若出现负数,则属于录入错误,直接标记为空。
“出运数量”不得大于“采购数量”,否则说明存在统计口径或记录错误,对此类异常记录的“出运数量”统一设置为缺失值。
2.2.4特征编码
为确保模型能够有效利用供应链数据中的不同类型变量,本研究根据特征的语义和结构特征采用了多种编码策略,包括标签编码、独热编码以及正弦—余弦编码。不同编码方式适用于不同类型的数据,能够有效提升模型对离散型、序数型和周期型变量的表达能力。
1. 标签编码
标签编码通过将类别变量映射为整数形式,例如将类别 A、B、C 分别编码为 0、1、2。本质上是一种保持类别间序关系的编码方式,适用于变量内部具有明确大小或等级关系的场景。
其能够能够保留类别之间的相对大小关系,更符合数据的真实语义;编码为单一数值,降低维度,有利于树模型或基于距离的模型识别等级差异;对于排序变量优于独热编码,因为独热编码会破坏等级信息并引入多余维度。
2. 独热编码
独热编码将每个类别映射为独立的二元变量,用0或1表示某条样本是否属于该类别,例如供应商1、供应商2、供应商3会被编码成:
| 供应商1 | 供应商2 | 供应商3 |
|---|---|---|
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
独热编码适用于无序类别变量,即类别之间不存在大小关系。与标签编码不同,独热编码不会人为赋予类别大小关系,避免模型误解结构;由于独热编码创造的正交向量能够有效表示互斥类别,因此会更适合用于深度学习模型;在供应链场景中,供应商、运输方式等属于纯分类信息,使用独热编码更为合理。
3. 正弦编码
对于具有循环拓扑结构的周期性特征如月份、小时、星期等,其数值表示虽呈线性顺序,但首尾元素在语义上邻近。若直接采用原始整数值进行编码,将导致欧氏距离度量下的语义失真——即模型会错误地将相邻周期点判为最大间隔,违背其内在循环连续性。
为显式建模此类周期性先验,本文采用正弦-余弦联合编码方法,将一维周期变量映射为二维实值向量。
$$
x_{\sin} = \sin\left(\frac{2\pi t}{T}\right)
$$
$$
x_{\cos} = \cos\left(\frac{2\pi t}{T}\right)
$$
其中T为周期长度。此方法能够保证任意两个时间点在单位圆上的弧长距离与其在周期空间中的最短环距严格对应;并且连续可导,便于梯度反向传播,且邻近值在嵌入空间中具有相近表示,符合局部平滑假设。
2.3数据标注
为支持供应链交付风险分析与后续模型训练,本研究对数据集中与交期表现相关的关键事件进行了系统的标注。事件标注逻辑的核心目标在于:
1. 识别异常交付行为;
2. 刻画延迟背后的业务原因;
3. 从时间、数量与流程三类维度建立可解释的事件类型体系。
本研究在结构化数据分析的基础上制定了多层次的事件标注规则,主要包括:延迟交货、旺季缺货、交期风险、延迟原因识别,以及综合事件类型归类。
2.3.1延迟交货的判定
延迟交货通过交付时差>0进行判定,其中交付时差定义为:
交付时差 = 实际交付日期 – 销售交期
该方法基于合同交期约束,强调对实际产出行为进行判定,有助于解决基于空值判断方式可能忽略风险的问题,提高延迟标注的准确率。当交付时差大于0时,表示供应商未按合同约定时间完成交付,标记为延迟。
对于存在销售交期但没有实际交付日期的记录,为避免未交付但不被视为延迟的逻辑错误,将其统一识别为延迟交货。
2.3.2旺季缺货的标注
- 旺季定义:
根据企业物流周期和市场需求波动,将3~5月以及9~11月定义为旺季。通过识别实际交付日期所在月份是否属于旺季,构建二元变量旺季。 - 缺货判定:
缺货通过“出运数量<订单数量”进行判断。若实际出运量不足以满足订单量,则标记为缺货事件。 - 旺季缺货:
当订单处于旺季且存在缺货时,定义为高风险事件旺季缺货,反映供应链在需求峰值期间的供给能力不足。
2.3.3交期风险的判定
为识别未构成延迟但存在潜在风险的交期,本研究设定如下规则:
当交付时差匀值满足-1≤交付时差≤0时,标记该订单为交期风险。
这类订单虽按时交付,但在交期前1天以内才完成,表明供应商产能紧张、生产排期不足或存在潜在履约波动。
2.3.4延迟原因的归因
为增强事件标注的可解释性,本研究进一步引入延迟原因识别,通过以下业务逻辑进行归因:
1. 缺货导致延迟:
当缺货=1且出现延迟交货时,将延迟原因标注为“缺货导致延迟”。此类延迟体现供应商产能不足或库存管理问题。
2. 质量问题导致延迟:
若存在查货日期晚于销售交期的情况,表明产品质量检验耗时超出计划,可能引发延迟,因此将其判定为质量问题导致延迟。
3. 样品批复滞后导致延迟:
若产前样品批复时间超过销售交期,则说明前置工序受阻,进而影响量产,标记为“样品批复滞后导致延迟”。
4. 按延迟程度分级:
对于无法判断具体原因但确实存在延迟的订单,本研究按照延迟天数将其分为三区间:
| 延迟天数 | 延迟等级 |
|---|---|
| 1~7天 | 一级延迟 |
| 8~14天 | 二级延迟 |
| 15天以上 | 三级延迟 |
三、数据分析与可视化
3.1订单数量年度趋势
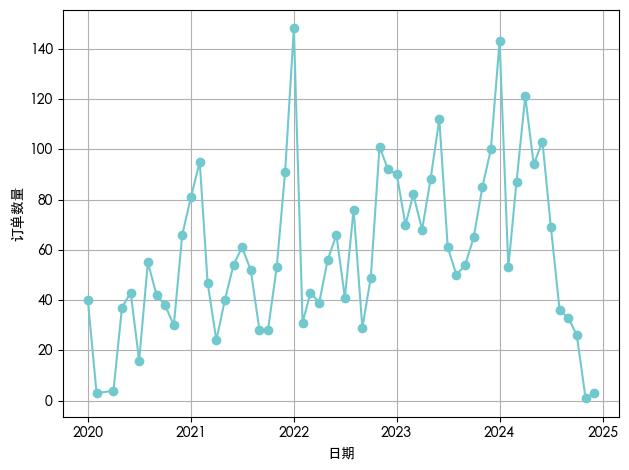
基于订单数据,绘制并分析了企业订单数量的长期演变趋势。如图所示,该时间序列呈现出显著的周期性波动特征,并伴随阶段性增长与结构性转折。
2020年第一季度,企业订单量出现下跌,最低点降至个位数水平。自2020年第二季度起,订单量开始稳步回升,呈现阶梯式增长态势,至2021年下半年已恢复至月均60-90单区间。
2022年全年订单量多次突破百单,其中2022年7月达到历史峰值,显示出市场需求的强劲反弹及企业产能或渠道拓展的有效性。2022年8月订单量又降至30单以下,随后又迅速反弹,这种波峰波谷模式暗示供应链响应机制在高需求压力下仍存在不稳定性,可能源于原材料短缺、物流瓶颈或生产排程失衡等协同问题。
2023年后,订单量虽未再现2022年的极端峰值,但整体维持在较高水平,波动幅度有所收窄,表明市场趋于理性,企业运营逐步进入常态化增长轨道。
2023年下半年至2024年,订单量再次出现阶段性攀升,于2024年4月和7月分别录得142单与120单的次高值,显示企业仍保有较强市场竞争力。然而,从2024年第三季度开始,订单量呈现明确的逐月递减趋势,至2025年1月已跌至10单左右,2025年2月进一步下滑至个位数。这一持续性下滑标志着当前业务周期已进入下行通道,可能预示着宏观经济环境变化、行业竞争加剧、客户需求结构转型或供应链协同效率下降等深层次问题正在显现。
3.2交付时差分布
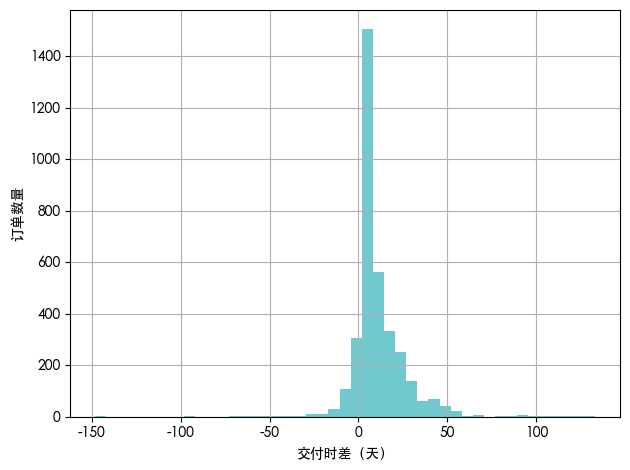
从图中可见,交付时差分布呈现典型的特征,数据主体高度集中在0天附近,且峰值显著高于其他区间。具体而言:
大部分订单的交付时差分布在[-10, +30]天区间内。
在0天右侧,分布曲线缓慢下降,表明存在少量但不可忽视的严重延迟订单,其时差可延伸至+50天甚至更长,尽管其绝对数量较小,但对客户满意度和供应链信誉构成潜在风险。
在0天左侧,分布急剧衰减,几乎无订单出现超过-30天以上的提前交付,说明企业在生产排程上普遍采取保守策略,较少主动压缩交付周期。
保守型排程策略:企业倾向于预留充足缓冲时间,以应对原材料到货延迟、生产异常或物流不确定性,因此大部分订单能按时或提前完成。
供应链瓶颈效应:少数订单出现严重延迟,往往源于特定环节的突发性中断,此类问题具有偶发性和不可预测性,但影响巨大。
缺乏动态协同机制:当前交付时差分布的“尖峰+长尾”结构,表明企业在需求预测、产能调度与供应商响应之间尚未形成高效闭环,难以在波动环境下实现精准交付。
3.3供应商可靠性分析
为了全面、客观、量化地评估供应商在交付履约过程中的可靠性表现,本研究设计并构建了一套多维度、加权融合的供应商可靠性评分算法。该算法以交付表现为核心,兼顾稳定性、质量控制、协作配合及风险缓释等关键能力维度,旨在突破传统单一指标的局限性,从系统层面识别高价值合作对象与潜在风险源。
本研究提出的评分模型采用五维加权框架,总分100分,各维度权重及计算逻辑如下:
1. D——交付表现:占50%,其是核心维度,包含与平均延迟惩罚。
2. S——稳定性:占20%,包含交付波动性惩罚与缺货风险控制。
3. Q——质量表现:占15%,基于质检通过率,确保质量底线不被突破。
4. C——配合度:占10%,依据采购审批及时率。
5. R——风险因子:占5%,作为调节项,惩罚高延迟行为。
所有子项均经过非线性变换,例如指数衰减、平方函数,以降低极端值对评分的过度冲击,同时保留区分度。
基于上述评分模型,本研究对全部活跃供应商进行了绩效打分并给出其分布,如图所示。
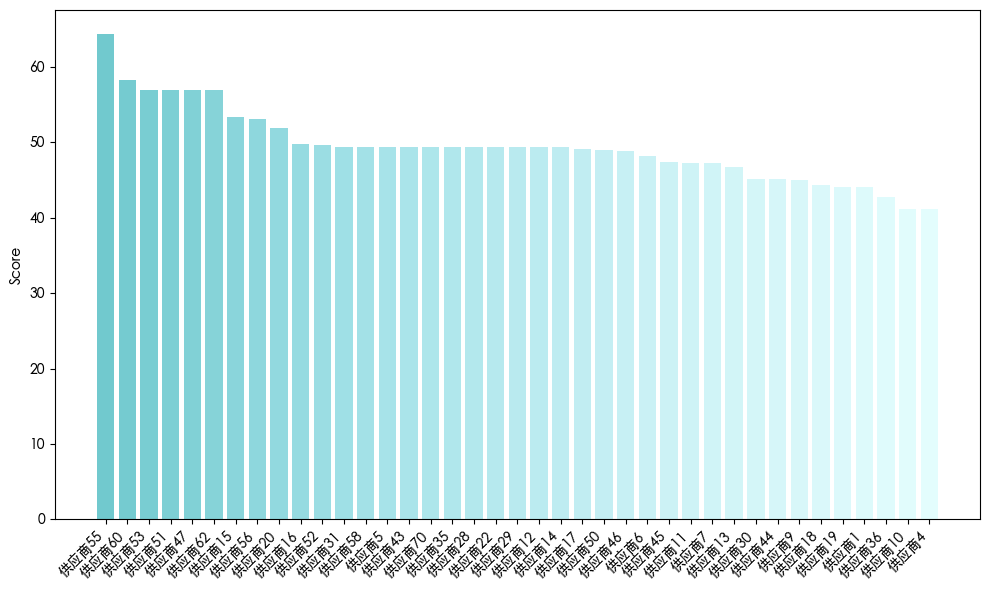
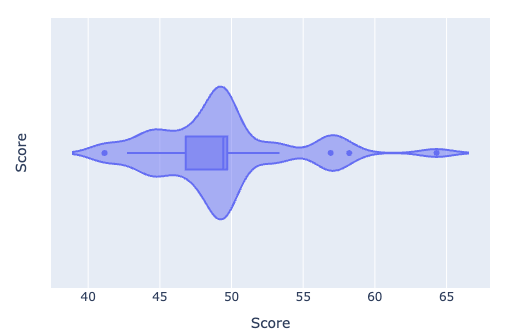
发现整体分布呈头部集中、长尾衰减的格局。
头部集群:得分普遍高于55分,最高达65分左右,表明少数核心供应商在交付准时性、生产稳定性、质量控制等方面表现卓越,是企业供应链韧性的关键支柱。
中游主体:得分集中在45–55分区间。这些供应商虽无突出亮点,但能基本满足订单交付要求,属于合格但需优化的中间力量。
尾部群体:得分低于45分,部分甚至不足40分,构成明显的长尾。
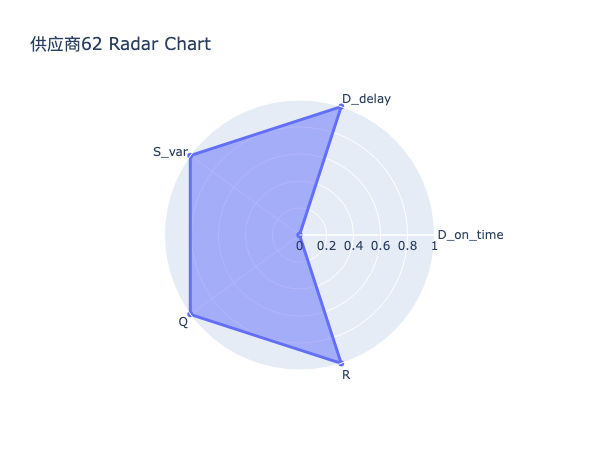
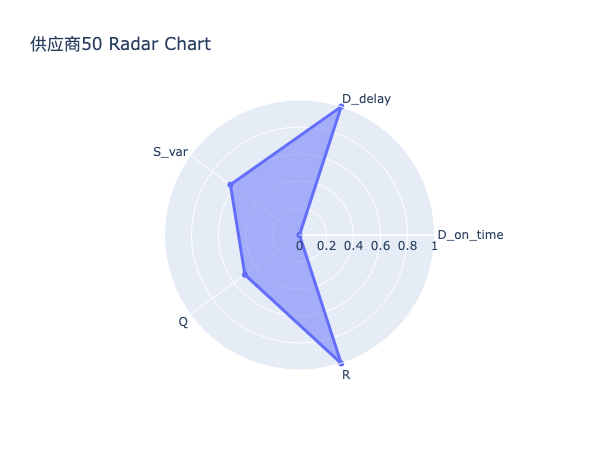
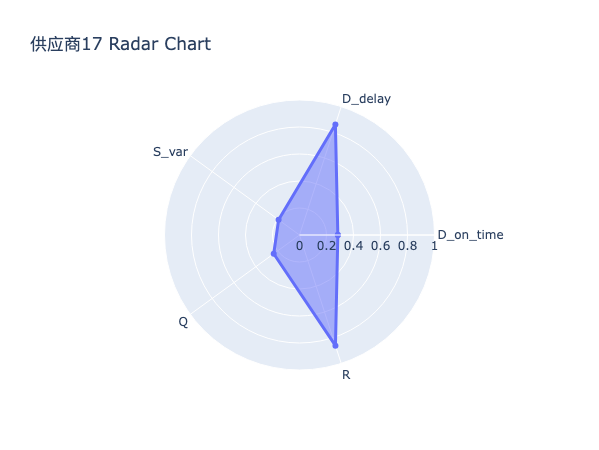
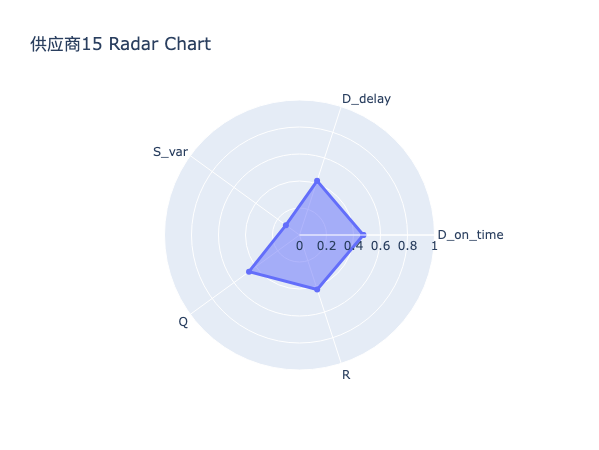
通过对各供应商五维能力雷达图的系统性比对与结构化分析,发现:
高分供应商普遍呈现出交付能力突出、多维协同均衡的能力结构特征。具体而言,其在交付表现上得分显著高于平均水平,多数供应商该项得分超过40分,且其子维度准时率与平均延迟惩罚均表现优异,表明该类供应商不仅具备高度稳定的交付履约能力,亦能有效控制异常延迟风险。同时,其在稳定性、质量、配合度等辅助维度上亦维持较高水平,形成以交付为核心、多能力支撑的良性循环结构。此类供应商构成企业供应链的核心,是实现高准交率目标的核心资源。
中游供应商的能力结构呈现非均衡依赖型特征。其总体得分虽处于合格区间,但主要依赖于质量表现与配合度所提供的得分,而其交付表现得分则普遍低于35分,反映出其在准时交付与延迟控制方面存在系统性短板。此类供应商虽能保证基本产品质量与流程协作效率,但在应对订单波动、紧急插单或产能压力时往往力不从心,易成为供应链响应速度的瓶颈环节,需通过针对性赋能提升其交付弹性。
尾部供应商的能力结构普遍表现为能力塌陷以及风险积聚。其最显著特征为 交付表现项与风险因子项双低——交付表现项得分常低于30分,意味着其交付准时率低下、平均延迟严重;风险因子得分亦普遍低于3分,表明其延迟行为已构成持续性、系统性风险。此外,部分供应商在稳定性或质量上亦出现明显凹陷,进一步加剧其履约不确定性。此类供应商属于供应链中的脆弱节点,其存在不仅拉低整体准交率,更可能因突发中断引发连锁反应,亟需启动专项整改或实施淘汰机制。
3.4延迟原因分析
为深入探究影响服装外贸企业订单准交率的核心障碍,基于历史订单交付记录,对导致交付延迟的根本原因进行了系统性归类与频次统计,并绘制延迟原因分布柱状图,如图所示。
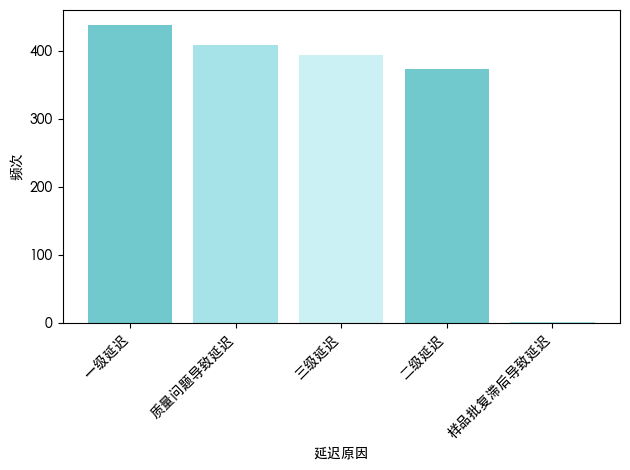
从延迟事件的频次分布形态可见,各类延迟高度集中于一级与二级层级,且无单一类别占据绝对主导地位。此分布特征表明,当前供应链延迟问题并非由孤立偶发因素驱动,而是多重扰动源并发、多层级环节耦合所引致的系统性失稳现象,呈现出非线性叠加效应。据此推断,局部修补式干预难以根治,需构建跨职能协同治理与全流程韧性优化的战略框架。
一级延迟为发生频次最高的类别,其典型诱因集中于供应链上游计划环节——包括需求预测偏差、采购计划失准、物料齐套率不足及主生产计划刚性过强等。此类延迟具有显著的上游放大效应,常通过牛鞭效应向下游逐级传导,导致多个订单同步延误,修复成本呈非线性增长。其高频发生反映出企业在动态需求响应能力,如滚动预测更新机制缺失,与跨组织协同弹性,如供应商产能可视性不足、安全库存策略静态化方面存在结构性短板。
建议构建三层联动计划协同体系:
1. 战略层:建立基于滚动窗口的主计划动态校准机制;
2. 战术层:部署高级计划与排程系统,实现有限产能约束下的多目标优化;
3. 执行层:针对关键瓶颈物料,实施差异化安全库存策略,如基于供应风险-需求波动矩阵的ABC-R分类法。
质量问题导致延迟频次紧随其后,反映出企业在追求交付速度的同时,质量控制体系尚未实现与生产节奏的有效同步。常见场景包括:面料色差、工艺不符、检验返工等,导致订单被迫停滞或返修,进而延误最终交付。这揭示出质量成本与时间成本之间的内在张力。
推行预防型质量管理,前置QC节点,如产前样确认、过程巡检,建立供应商质量绩效挂钩机制,将质量风险控制在源头。
三级延迟频次居中,通常指向跨部门协作断点或信息系统割裂所致的延误,例如:销售未及时传递客户变更、跟单未同步生产指令、物流未提前预约舱位等。此类延迟虽不直接源于生产或采购,但因其涉及多角色、多系统,协调难度大、责任模糊。
建议推行端到端订单可视化治理平台,通过PLM-ERP-SCM系统集成,固化三大关键节点:明确客户变更响应窗口;实现物料可用性实时反馈;触发物流资源自动预约。同步嵌入基于规则引擎的预警机制,对跨系统状态异步实施分级干预。
二级延迟一般对应生产执行阶段的异常波动,如设备故障、人员缺勤、工序衔接不畅等。其频次略低于一级延迟,但仍属高频事件,说明企业在制造过程稳定性与应急响应能力方面仍有提升空间。
3.5非结构化文本挖掘
在服装外贸企业的订单履行过程中,跟单备注作为一线业务人员实时记录的非结构化文本数据,承载了订单执行链中多维度的隐性运营知识,包括:供应链节点阻滞、质量偏差事件、跨职能协作断点以及客户诉求动态演变等关键信息。此类文本虽具高度情境依赖性与表达异质性,但其语义聚合可为识别系统性运营瓶颈提供重要的数据线索。
为系统性提取高信息价值的语义特征,本研究TF- IDF方法提取关键词。
具体的处理流程为:
1. 将每一段文本去除标点后分词并去重得到词表;
2. 把每个文档和词表逐一比对,根据词语出现的次数进行标记得到词频;
3. 将词语出现的次数除以句子中词语的数量并取对数得到词语的稀有性;
4. 词频与稀有性相乘就是TF- IDF,取TF- IDF法结果最高的作为关键词。

该词云图中,字体越大表示该词在整体文本中出现频率越高且区分度越强,即其在描述订单执行问题时具有更高的信息价值与代表性。
3.5.1风险分析
通过对词云中高频词的聚类分析,识别出当前企业订单履约过程中存在的三大核心风险:
1. 客户投诉与责任归属风险
“客诉”与“承担”以最大字号居于词云中心,表明客户不满是当前最突出、最频繁的问题来源。
“后果自负”、“承担”等词高频出现,反映出企业在面对客户索赔或变更时,常需被动接受责任划分,缺乏前置风险管控机制。
“返工”、“修改”则揭示了因设计、工艺或生产失误导致的重复劳动成本,是影响交付周期与利润率的关键因素。
需建立客户投诉闭环处理机制,将事后补救转为事前预防;同时强化设计评审与首件确认流程,降低返工率。
产品质量与工艺控制风险
“色差”、“偏小”、“无样”等词集中出现,指向产品在颜色一致性、尺寸规格、样品确认等环节存在系统性缺陷。
“熨烫”、“压痕”、等工艺相关词汇高频出现,表明后道工序质量不稳定,易引发客户拒收或退货。
“面料”、“做工”作为基础要素被反复提及,提示原材料选型与生产过程控制仍存疏漏。
应推行全链路质量管理,从面料采购、产前样确认、过程巡检到成品检验实施标准化控制;引入AI视觉检测技术辅助人工质检,提升一致性。流程协同与信息传递风险
“更改”、“重新”等词频繁出现,反映订单执行过程中需求变更频繁、信息更新滞后,导致生产计划反复调整,资源浪费严重。
应构建订单变更管理系统,实现销售、设计、生产、仓储各环节的信息同步与版本控制;推行5S现场管理与目视化作业指导书,减少人为操作误差。
3.5.2词云分布
从词云布局可见,上述三类风险并非孤立存在,而是高度重叠、相互诱发:
“客诉”常由“色差”或“偏小”引发;
“返工”往往源于“更改”未及时传达;
“后果自负”则多发生在“无样”或“未订”情况下。
这表明当前供应链风险已从单一环节的“点状问题”,演变为跨部门、跨流程的“网状危机”,任何局部优化都难以根治,必须采取端到端协同治理策略。
将“客诉率”、“返工率”等词频指标纳入供应商评分模型,使非结构化文本数据转化为可量化的管理工具,倒逼上游协作质量提升。
四、模型构建与验证
4.1模型选择
为系统评估不同建模方法在供应链准交率预测任务中的适用性,本文从线性模型、集成学习模型和神经网络模型三个角度,选取五种具有代表性的分类模型进行对比实验,分别为
1. Logistic Regression
2. Random Forest
3. XGBoost
4. LightGBM
5. MLP
4.2各模型原理与特点分析
4.2.1 Logistic Regression
逻辑回归是一种广义线性模型,通过Sigmoid函数将线性组合输入映射至[0,1] 区间,输出为事件发生的概率估计。其参数估计通常采用极大似然估计,并结合梯度下降或牛顿法进行优化。
由于逻辑回归结构简单、训练速度快、结果稳定,常被用作机器学习任务中的基线模型。通过与更复杂模型的对比,可以直观评估非线性模型在性能提升上的实际贡献。
逻辑回归模型的回归系数具有明确的统计学意义,能够反映各特征对预测结果的正负影响方向及相对强度,具有较高的可解释性,适合用于业务分析和决策支持场景。
4.2.2 Random Forest
随机森林是一种基于Bagging思想的集成学习算法,通过对原始数据进行多次自助采样,并训练多棵决策树,最终通过投票或平均方式输出预测结果。
由于随机森林通过集成多棵相互独立的决策树进行预测,单棵树受到异常样本或噪声数据影响的风险被有效削弱,因此整体模型具有较强的鲁棒性。
随机森林在节点分裂时引入特征随机选择机制,使其能够有效处理高维特征空间。但随着树的数量和深度增加,模型的计算复杂度和存储开销也相应提高。
4.2.3 XGBoost
XGBoost是对传统GBDT算法的工程化和算法层面优化,通过加法模型逐步迭代生成弱学习器,以最小化整体目标函数。
相比传统GBDT仅使用一阶梯度信息,XGBoost在目标函数中引入二阶导数,使得模型在优化过程中具有更快的收敛速度和更稳定的学习过程。
XGBoost在目标函数中显式引入对叶节点数量和叶节点权重的正则化项,有效控制模型复杂度,从而降低过拟合风险。
基于决策树结构,XGBoost能够自动捕捉复杂的非线性关系和高阶特征交互,在实际预测任务中通常具有较高的建模精度。
4.2.4 LightGBM
LightGBM采用直方图算法对连续特征进行离散化,并使用叶子优先生长策略,相较于传统层级生长方式能够更快降低损失函数。
通过特征离散化与高效的数据结构设计,LightGBM在大规模数据集上具有较高的训练效率和较低的内存消耗。
LightGBM在处理大样本、高维特征数据时具有显著优势,尤其适用于工业级场景和需要快速迭代的建模任务。
4.2.5 MLP
多层感知机是一种典型的前馈神经网络,由输入层、一个或多个隐藏层以及输出层组成,层与层之间通过全连接方式进行信息传递。
通过引入非线性激活函数,MLP能够逼近复杂的非线性函数关系,适用于特征关系复杂的预测任务。
MLP对输入特征的尺度较为敏感,通常需要对数值特征进行标准化处理;同时,其性能对样本规模依赖较大,小样本场景下容易出现过拟合。
4.3模型训练与交叉验证方法
为提高模型评估结果的稳健性与可靠性,采用K折交叉验证方法对各模型进行性能评估。
单次训练—测试划分容易受到数据随机性的影响,评估结果具有不确定性。
通过多次不同数据子集的训练与验证,交叉验证能够有效降低偶然样本划分对模型评估结果的干扰。
K折交叉验证通过对模型在不同数据子集上的综合表现进行评估,使得模型性能指标更能反映其在未知数据上的泛化能力。
4.4模型评估
4.4.1分类性能对比分析
为全面评估不同模型在二分类任务中的预测性能,本文选取Logistic Regression、Random Forest、XGBoost、LightGBM 以及 MLP五种模型进行对比实验。评估指标包括 Accuracy、Precision、Recall、F1-score、AUC、PR-AUC,并综合考虑模型运行时间与内存占用,以分析模型在预测效果与计算成本之间的权衡。
| model | AUC | PR-AUC | Accuracy | F1 |
|---|---|---|---|---|
| RandomForest | 0.869 | 0.871 | 0.807 | 0.827 |
| XGBoost | 0.863 | 0.869 | 0.785 | 0.806 |
| LightGBM | 0.860 | 0.867 | 0.778 | 0.799 |
| LogisticRegression | 0.815 | 0.827 | 0.750 | 0.774 |
| MLP | 0.840 | 0.852 | 0.775 | 0.795 |
从整体分类效果来看,各模型在测试集上的表现存在一定差异,如表中所示。
Random Forest在多数核心指标上表现最优,Accuracy达到0.807,F1-score达到 0.827,AUC与PR-AUC分别为 0.869和0.871,说明其在区分正负样本方面具有较强的综合能力。
XGBoost的整体性能略低于Random Forest,但仍保持较高的AUC与PR-AUC,在复杂非线性关系建模方面具备较强能力。
LightGBM在预测性能上略逊于XGBoost,但差距较小,其Accuracy为 0.778,F1-score为0.799。
MLP的表现较为稳定,各项指标处于中等水平,说明在当前特征规模与样本量下,深度模型未能显著优于树模型。
Logistic Regression作为线性基线模型,整体性能最低,但仍具备一定预测能力,验证了问题本身存在较为明显的可分性。
4.4.2交叉验证稳定性分析
为验证模型泛化能力,本研究在训练集上执行5折分层交叉验证,结果如下
| model | CV Acc | CV AUC | CV F1 |
|---|---|---|---|
| RandomForest | 0.798+-0.013 | 0.870+-0.015 | 0.817+-0.013 |
| XGBoost | 0.803+-0.009 | 0.887+-0.017 | 0.825+-0.009 |
| LightGBM | 0.798+-0.008 | 0.886+-0.014 | 0.817+-0.011 |
| LogisticRegression | 0.768+-0.005 | 0.829+-0.013 | 0.786+-0.005 |
| MLP | 0.765+-0.010 | 0.833+-0.017 | 0.787+-0.009 |
所有模型CV标准差均小于0.02,表明其在不同数据子集上表现稳定,无严重过拟合或欠拟合现象;
XGBoost 在CV-AUC上表现最优,高于RandomForest,提示其在训练集上具有更强的排序能力;
LightGBM 与 XGBoost 的CV-F1几乎持平,显示二者在平衡精确率与召回率方面能力相当。
4.4.3 混淆矩阵分析
通过混淆矩阵可以进一步分析模型对不同类别的识别能力。
| 随机森林 | XGBoost | LGBM | 逻辑回归 | MLP |
|---|---|---|---|---|
| [[241 83] | ||||
[ 52 323]] |
[[237 87] | |||
[ 63 312]] |
[[236 88] | |||
[ 67 308]] |
[[224 100] | |||
[ 75 300]] |
[[237 87] | |||
[ 70 305]] |
Random Forest对正类的识别能力最强,召回率达到 0.86,误判为负类的样本数量最少。
XGBoost和LightGBM在正类预测上表现接近,但均存在一定程度的漏判问题。
Logistic Regression对负类与正类的区分能力相对较弱,误分类样本数量明显高于其他模型。
各模型整体上对正类的预测能力略高于负类,与样本分布中正类比例略高有关。
4.4.4 ROC曲线与PR曲线分析
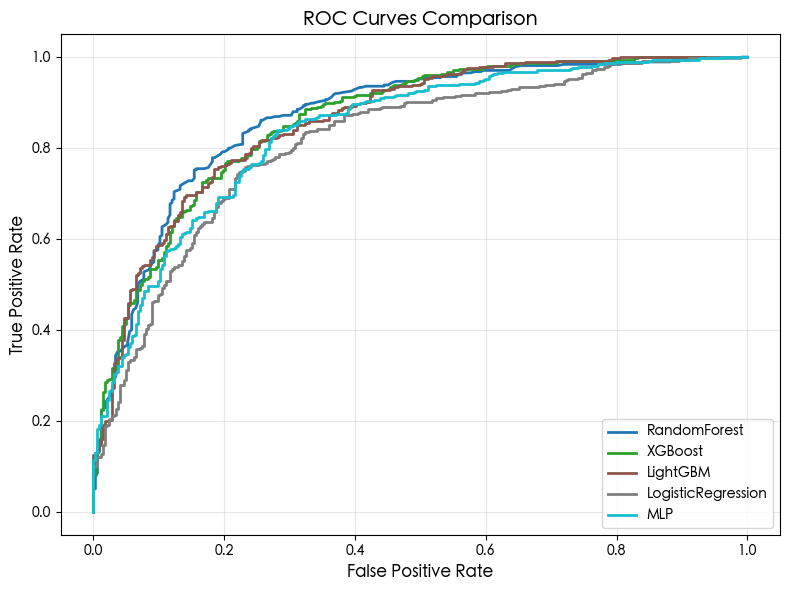
如图所示,五条ROC曲线均位于对角线上方,表明所有模型均优于随机猜测。
RandomForest曲线在中低假阳性率区间表现最优,TPR上升陡峭,意味着其在控制误报前提下能更早识别出真实延迟订单;
XGBoost与LightGBM曲线紧贴RF,尤其在高TPR区域三者几乎重合,显示其在高召回场景下能力相当;
LogisticRegression与MLP曲线明显偏低,尤其在FPR > 0.2后增长缓慢,反映其区分能力受限。
若企业希望在较低误报率下实现较高检出率,RandomForest是首选;若追求极致高召回,则XGBoost以及LightGBM更具优势。
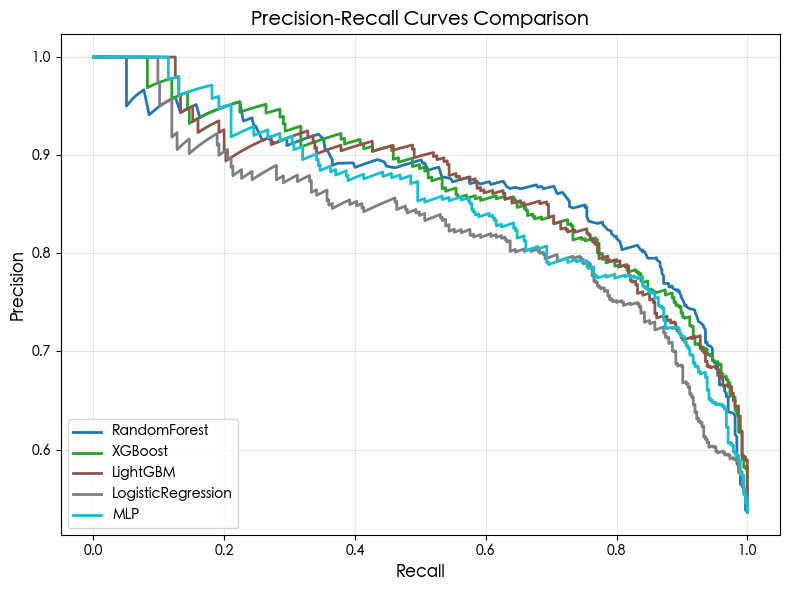
PR曲线对类别不平衡问题更为敏感,其曲线下面积直接反映模型在正类上的实用价值。图中可见:
RandomForest 的PR曲线在全召回范围内均保持最高精度,尤其在Recall > 0.6时仍维持Precision > 0.8,表明其在实际部署中能有效控制误报成本;
XGBoost 与 LightGBM曲线紧随其后,在Recall > 0.7时Precision约0.75–0.78,略低于随机森林;
LogisticRegression与MLP曲线下降较快,在Recall > 0.5后Precision迅速跌破0.7,实用性受限。
对于服装外贸企业而言,避免漏报延迟订单比减少误报更重要,因此应优先关注PR曲线在高Recall区域的表现。在此维度上,RandomForest显著优于其他模型。
4.4.5计算效率与资源消耗对比
| model | Time (s) | Memory (MB) |
|---|---|---|
| RandomForest | 1.741 | 235.73 |
| XGBoost | 1.521 | 406.08 |
| LightGBM | 0.653 | 331.33 |
| LogisticRegression | 1.737 | 328.52 |
| MLP | 1.761 | 356.97 |
LightGBM效率最高,训练时间最短,内存适中,适合边缘设备或高频推理场景;
RandomForest具有高性价比,虽训练稍慢,但内存占用最低,且性能最优;
XGBoost资源代价较高,内存消耗最大,可能限制其在资源受限设备上的部署。
4.5模型选择依据
综合以上分析,在预测精度、业务实用性、模型稳定性、计算效率四个维度进行评估,得出如下结论:
推荐模型:RandomForest
理由一:综合性能最优
在AUC、PR-AUC、Accuracy、F1四项核心指标上均排名第一,尤其在PR曲线高Recall区域表现突出,符合高召回、控误报的业务需求;
理由二:稳定性强
CV标准差最小,泛化能力可靠;
理由三:资源友好
内存占用最低,适合在中小企业本地服务器或边缘设备部署;
理由四:可解释性强
特征重要性输出可直接用于延迟归因分析,支持业务决策。
尽管XGBoost在CV-AUC上略胜一筹,但其在测试集上的AUC低于RandomForest,且内存消耗高、F1-score略低,故未作为首选。LightGBM虽快,但精度与稳定性略逊于RF。
4.6特征重要性分析
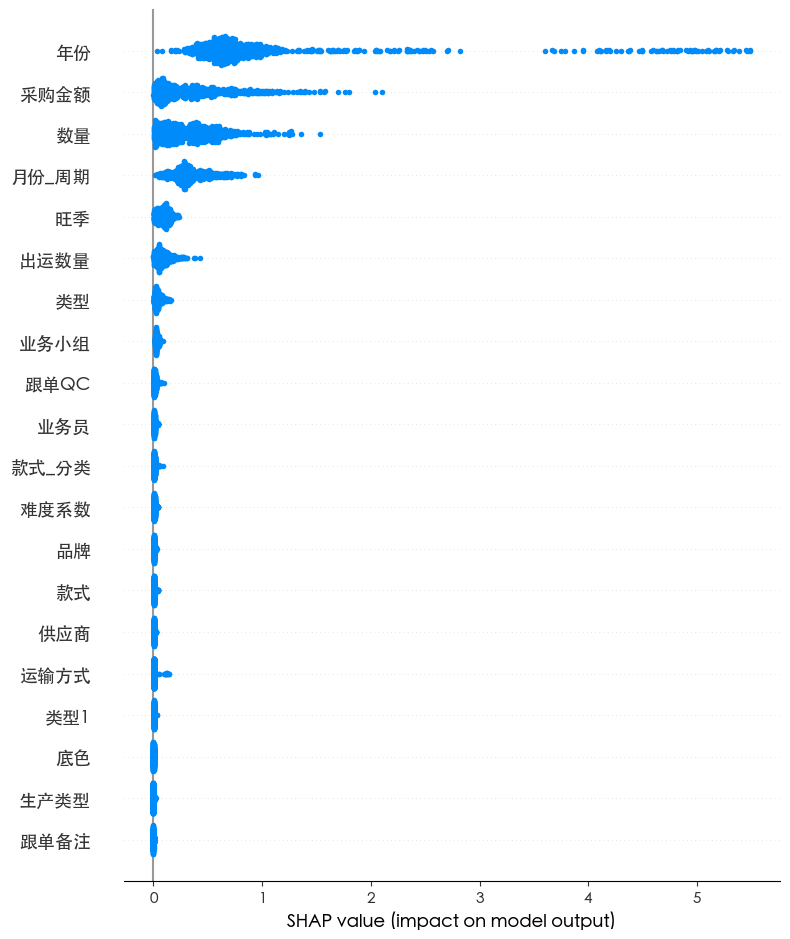
从图中可见,特征重要性呈现高度集中、层级分明的分布结构:
4.6.1总体分析
“年份”与“采购金额”,其重要性均值显著高于其他变量;“数量”、“月份_周期”、“旺季”、“出运数量” 等特征,属于次关键变量;“业务小组”、“跟单QC”、“品牌”、“供应商”等,表明其对模型输出的边际贡献有限。
此分布格局揭示了:订单是否准时交付并非由单一环节决定,而是受宏观时间趋势、订单经济规模、季节波动等结构性因素主导。
4.6.2具体分析
- 年份
“年份”以最高重要性居首,表明订单准时率存在显著的年度周期性或结构性演变。可能原因包括:企业供应链能力随年份提升;外部环境变化;内部管理政策调整。
应建立年度绩效基线,将当前订单表现与历史同期对比,识别异常波动;同时将“年份”作为分层分析维度,用于评估战略举措的长期效果。 - 采购金额
采购金额反映订单价值量级直接影响资源配置与交付优先级。高金额订单往往伴随:更多内部资源倾斜;供应商配合意愿更强;质检与物流环节更谨慎,降低延迟风险。
可考虑建立订单价值分级响应机制,对高金额订单实施VIP通道管理,如设置专属交付窗口、提前锁定产能、增加过程监控频次等。 - 数量与出运数量
数量与出运数量的重要性仅次于前两者,说明订单体量是影响交付稳定性的重要变量。大规模订单易引发:生产排程冲突;原材料齐套难度上升;包装/仓储/物流压力陡增。
需优化大单拆解策略,将超大订单按生产节拍拆分为多个子批次,降低单点压力;同时加强出运数量与生产计划的联动,避免生产完成但无法出货的局面。 - 月份与旺季
月份与旺季共同刻画了时间对交付能力的周期性冲击。月份通过正弦余弦编码捕捉月度循环特性,其重要性表明某些月份存在交付瓶颈;旺季作为二元标识,进一步强化了这一趋势。
应建立季节性产能储备机制,在预判旺季来临前3个月启动产能扩张或外包预案;同时对旺季订单实施提前锁定和缓冲库存策略,平滑需求高峰。
五、结论
5.1 准交率呈现高平均、低稳定的结构性特征
订单交付时差分布分析表明,企业整体准交率虽达较高水平,但分布呈显著右偏态,存在不容忽视的长尾延迟风险。少数订单的严重延误虽占比不足5%,却对客户满意度与供应链信誉构成实质性威胁。这一现象揭示了当前交付管理仍处于被动响应阶段,缺乏对极端风险的主动防控能力。
5.2 延迟成因具有高度系统性与多源并发性
延迟原因分布与跟单备注文本挖掘共同证实:交付延迟并非由单一环节主导,而是前端计划偏差、过程质量失控、跨部门协同断点、执行波动与决策滞后五大因素交织作用的结果。其中,“客诉”“返工”“色差”“更改”等高频词频,直观反映了企业在需求变更管理、质量前置控制与信息流贯通三大环节的短板。这要求优化策略必须端到端协同治理。
5.3 供应商绩效分化显著
供应商可靠性评分体系与雷达图联合分析揭示:高绩效供应商普遍呈现交付能力突出、多维均衡的结构特征;中游供应商依赖质量与配合度维持总分,但在交付弹性上存在硬伤;尾部供应商则呈现质量、准时度双低的风险积聚状态。表明,供应商管理不能仅关注是否交付,更需评估其能力结构健康度。
5.4宏观结构性因素主导交付结果
影响准交率的核心驱动因素并非传统认为的人员、款式或供应商,而是宏观趋势、经济规模、执行压力与时间波动等结构性变量。其中,年份重要性最高,反映企业供应链能力随时间演进的系统性提升;采购金额凸显订单价值对资源配置优先级的决定性影响。这提示:需建立与宏观周期、订单规模相匹配的弹性响应机制。
- Title: 基于供应链数据协同的服装外贸企业准交率优化研究
- Author: 姜智浩
- Created at : 2025-12-19 11:45:14
- Updated at : 2025-12-19 11:43:58
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/12/19/20251219基于供应链数据协同的服装外贸企业准交率优化研究/
- License: This work is licensed under CC BY-NC-SA 4.0.