商业数据分析--信用卡数据

声明
本文代码均保存在
https://github.com/super-213/business_data_analysis
有需要的可以自行下载
查看数据
1 | df = pd.read_excel('信用卡数据.xlsx') |
| 编号 | 年龄 | 负债比率 | 月收入 | 贷款数量 | 家属人数 | 分类 |
|---|---|---|---|---|---|---|
| 1 | 29 | 0.22 | 7800 | 1 | 3 | 0 |
| 2 | 52 | 0.46 | 4650 | 1 | 0 | 0 |
| 3 | 28 | 0.10 | 3000 | 0 | 0 | 0 |
| 4 | 29 | 0.20 | 5916 | 0 | 0 | 0 |
| 5 | 27 | 1.28 | 1300 | 0 | 0 | 1 |
缺失值处理
1 | df.isnull().sum() |
异常值处理
查看异常值
1 | for col in df.columns: |
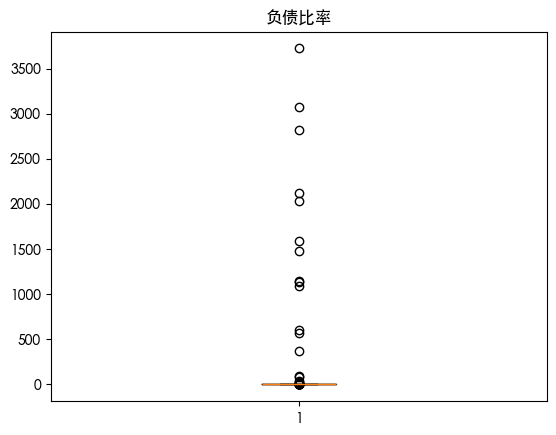
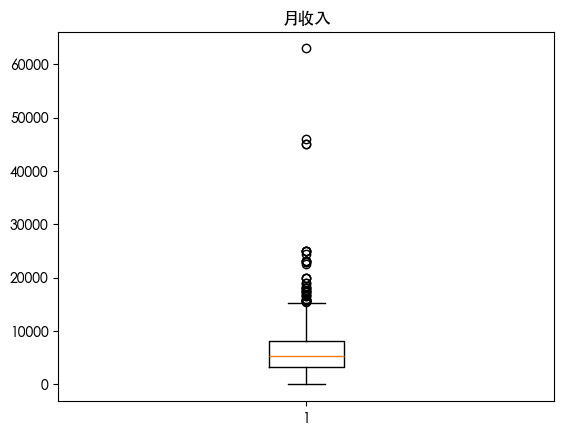
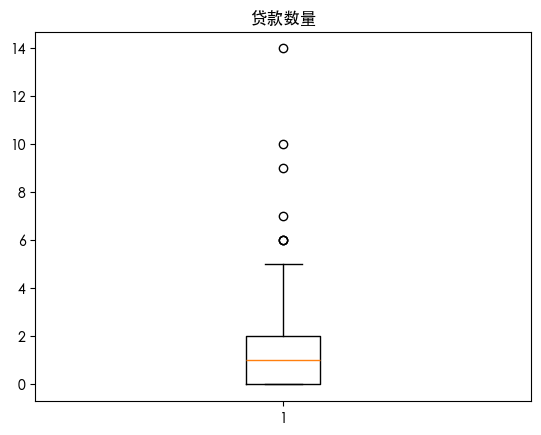
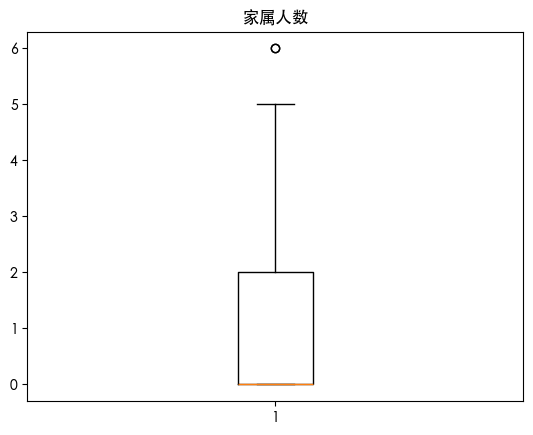
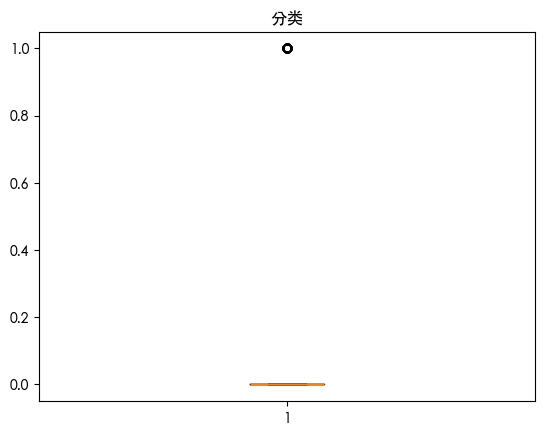
查看数据分布
1 | from scipy import stats |
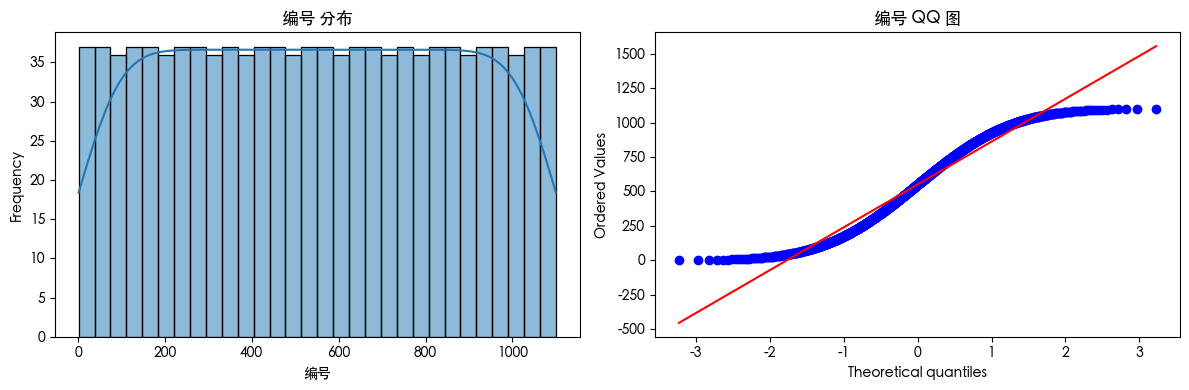
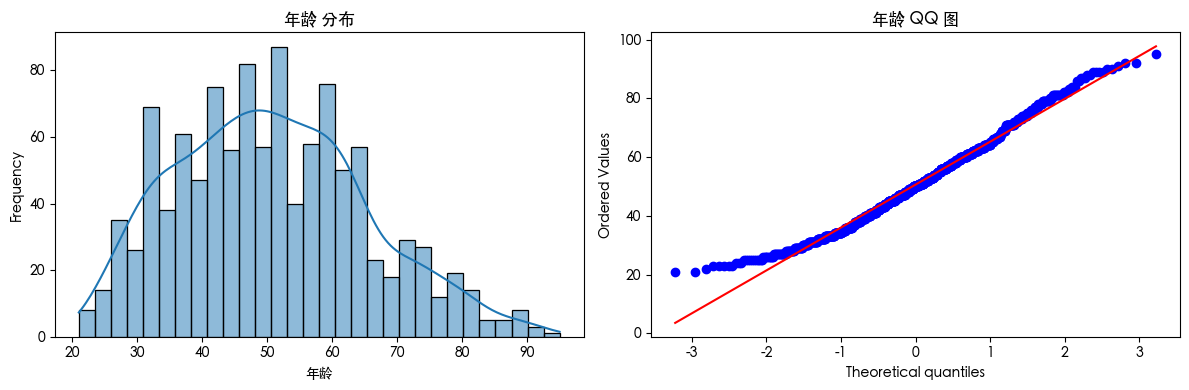
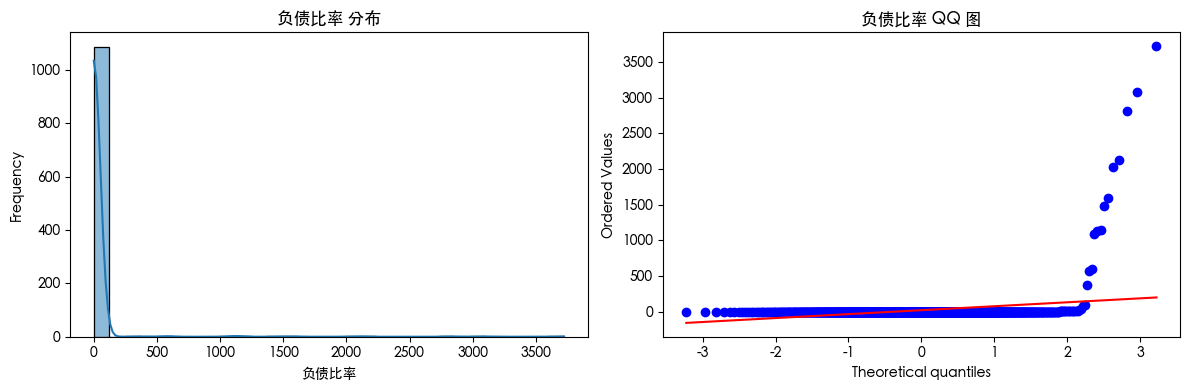
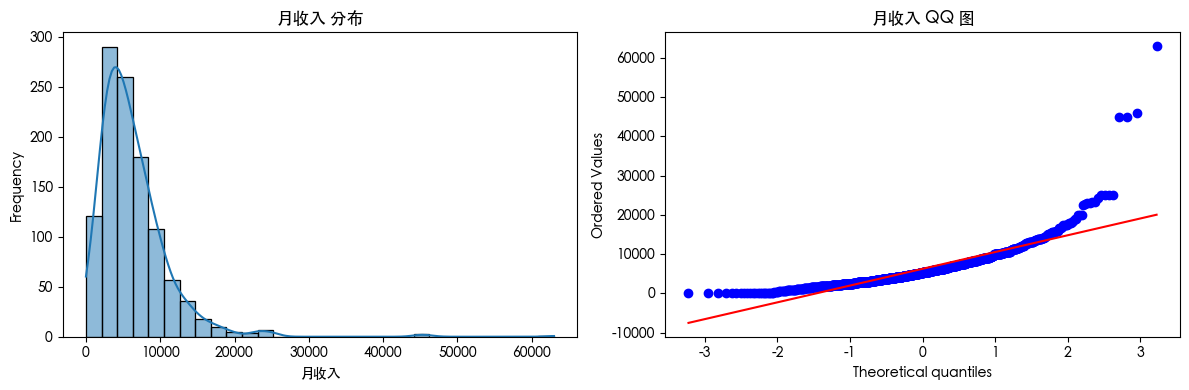
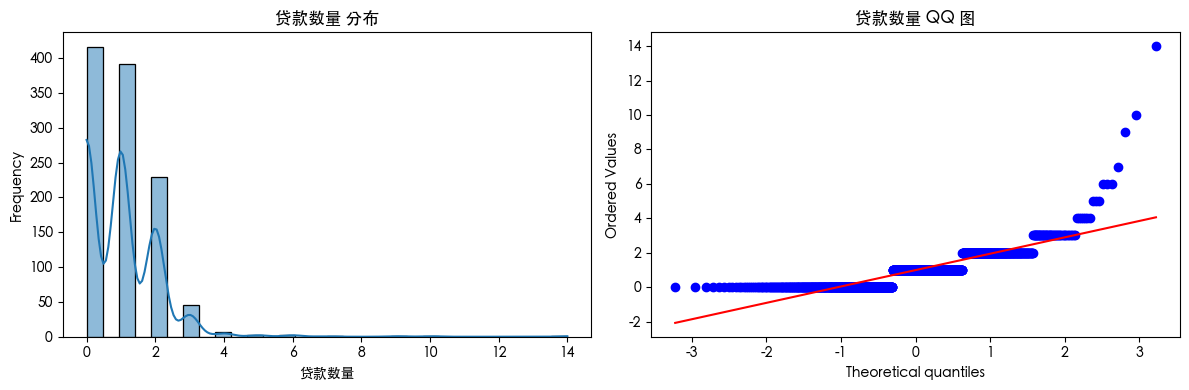
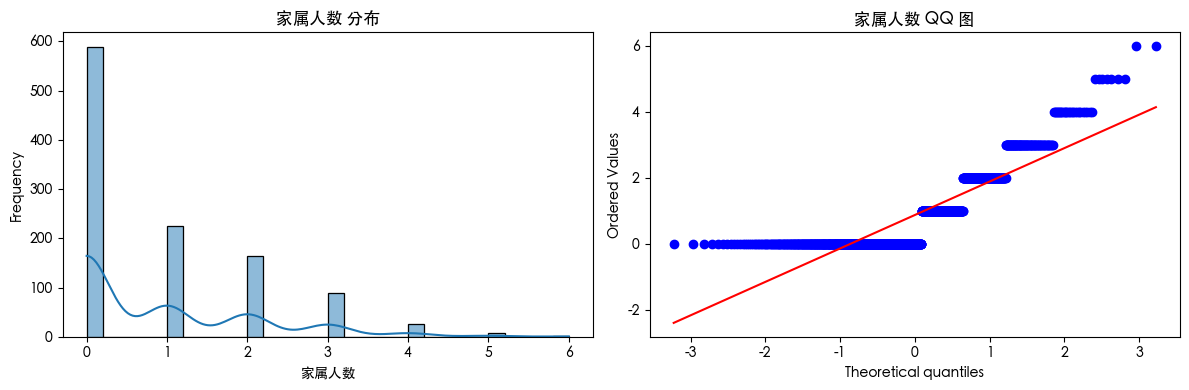
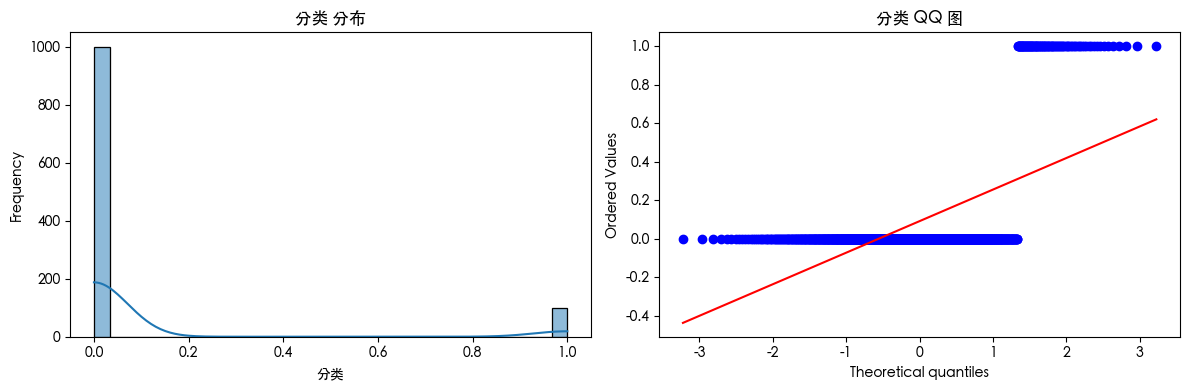
查看数据可知 数据存在异常值 查看数据分布得知 数据是长尾分布 并且目标的数据是不平衡的数据集
对数变换
1 | import numpy as np |
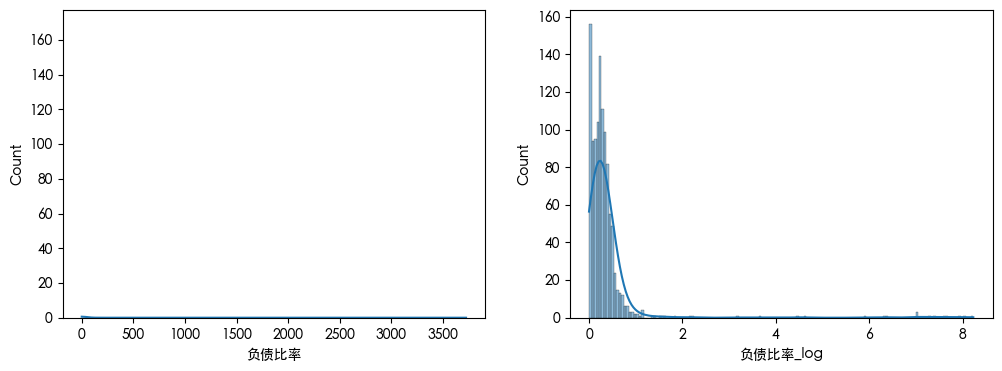
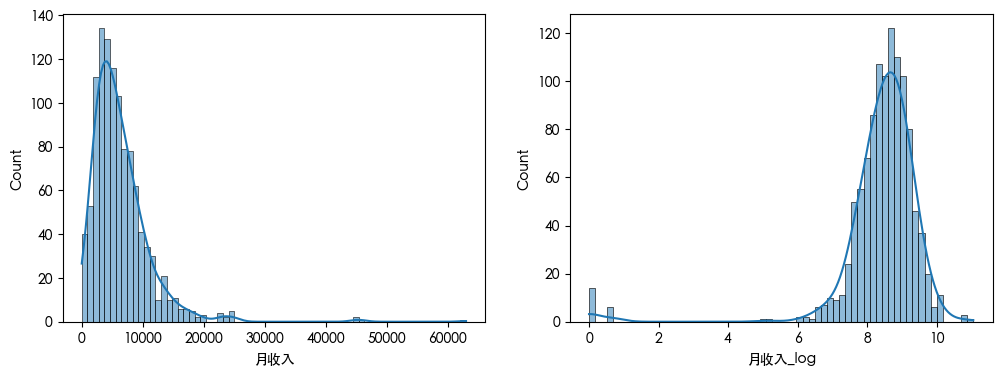
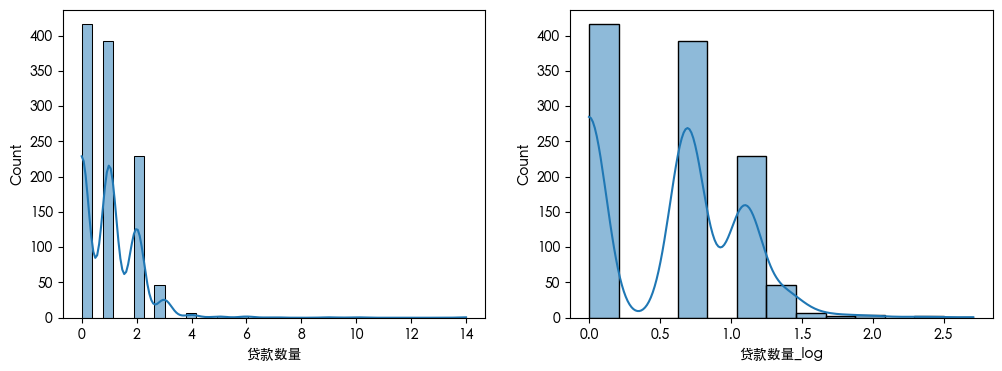
数据划分
1 | df = df.drop(columns=['负债比率', '月收入', '贷款数量']) |
随机森林
1 | from sklearn.ensemble import RandomForestClassifier |
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 200 | 0 |
| 1 | 20 | 0 |
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.91 | 1.00 | 0.95 | 200 |
| 1 | 0.00 | 0.00 | 0.00 | 20 |
| accuracy | 0.91 | 220 | ||
| macro avg | 0.45 | 0.50 | 0.48 | 220 |
| weighted avg | 0.83 | 0.91 | 0.87 | 220 |
XGBoost
1 | from xgboost import XGBClassifier |
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 197 | 3 |
| 1 | 19 | 1 |
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.91 | 0.98 | 0.95 | 200 |
| 1 | 0.25 | 0.05 | 0.08 | 20 |
| accuracy | 0.90 | 220 | ||
| macro avg | 0.58 | 0.52 | 0.52 | 220 |
| weighted avg | 0.85 | 0.90 | 0.87 | 220 |
LGBM
1 | from lightgbm import LGBMClassifier |
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 197 | 3 |
| 1 | 20 | 0 |
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.91 | 0.98 | 0.94 | 200 |
| 1 | 0.00 | 0.00 | 0.00 | 20 |
| accuracy | 0.90 | 220 | ||
| macro avg | 0.45 | 0.49 | 0.47 | 220 |
| weighted avg | 0.83 | 0.90 | 0.86 | 220 |
KNN
1 | from sklearn.neighbors import KNeighborsClassifier |
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 197 | 3 |
| 1 | 20 | 0 |
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.91 | 0.98 | 0.94 | 200 |
| 1 | 0.00 | 0.00 | 0.00 | 20 |
| accuracy | 0.90 | 220 | ||
| macro avg | 0.45 | 0.49 | 0.47 | 220 |
| weighted avg | 0.83 | 0.90 | 0.86 | 220 |
SVM
1 | from sklearn.svm import SVC |
| 实际 \ 预测 | 0 | 1 |
|---|---|---|
| 0 | 200 | 0 |
| 1 | 20 | 0 |
| 类别 | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0 | 0.91 | 1.00 | 0.95 | 200 |
| 1 | 0.00 | 0.00 | 0.00 | 20 |
| accuracy | 0.91 | 220 | ||
| macro avg | 0.45 | 0.50 | 0.48 | 220 |
| weighted avg | 0.83 | 0.91 | 0.87 | 220 |
模型横向比较
| 模型 | Accuracy | Recall(类别1) | Precision(类别1) | 主要问题 |
|---|---|---|---|---|
| 随机森林 | 0.91 | 0.00 | 0.00 | 完全没预测出类别1 |
| XGBoost | 0.90 | 0.05 | 0.25 | 能预测到1个类别1,但严重偏向类别0 |
| LightGBM | 0.90 | 0.00 | 0.00 | 和随机森林类似,类别1全漏掉 |
| KNN | 0.90 | 0.00 | 0.00 | 全部预测为类别0 |
| SVM (线性核) | 0.91 | 0.00 | 0.00 | 完全没识别类别1 |
分析
总体表现
- 所有模型在 总体准确率 (accuracy ~0.90–0.91) 上看似不错,但这主要来自于对 类别0 的正确预测。
- 类别1(少数类)几乎完全无法识别,F1=0。
类别分布极度不均衡
- 从混淆矩阵看,真实标签中类别1只有20个(占比 < 10%)。
- 模型都选择了“保守预测类别0”,因为这样可以最小化整体错误率。
XGBoost 稍微好一些
- 至少捕捉到了1个类别1(recall=0.05),但 precision 很低(0.25),说明模型在识别少数类上还是力不从心。
改进
要解决“类别1完全被忽视”的问题,可以尝试以下方法:
数据层面
- 过采样少数类:用 SMOTE 等方法扩充类别1。
- 欠采样多数类:平衡正负样本。
- 组合方法:如 SMOTEENN(过采样+清理噪声)。
模型层面
- 类别权重调整:在
RandomForestClassifier、XGBClassifier、LGBMClassifier、SVC中都可以加class_weight='balanced'或手动设置{0:1, 1:10}类似的比例。 - 调节阈值:现在默认阈值是 0.5,可以通过 ROC/PR 曲线选择更适合的阈值,提高对少数类的 recall。
- 专门针对不平衡的算法:比如
BalancedRandomForest、EasyEnsemble、CatBoost(支持内置类别平衡)。
- 类别权重调整:在
评价指标改进
- 不要只看 accuracy,更适合看 Recall/F1-score(尤其是少数类) 或 AUC-ROC / AUC-PR。
总结
目前模型对多数类预测很好,但由于样本严重不平衡,少数类(类别1)几乎被完全忽略。你需要通过 采样方法 + 类别权重 + 阈值调整 来改善模型对类别1的识别。
- Title: 商业数据分析--信用卡数据
- Author: 姜智浩
- Created at : 2025-09-30 11:45:14
- Updated at : 2025-09-30 08:50:28
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/09/30/20250930商业数据分析--信用卡数据/
- License: This work is licensed under CC BY-NC-SA 4.0.