商业数据分析--IT行业收入表

前期准备
导入一些必要库
1 | import pandas as pd |
查看数据
1 | df.head() |
| 工龄 | 薪水 | |
|---|---|---|
| 0 | 0.0 | 10808 |
| 1 | 0.1 | 13611 |
| 2 | 0.2 | 12306 |
| 3 | 0.3 | 12151 |
| 4 | 0.4 | 13057 |
工龄 0
薪水 0
dtype: int64
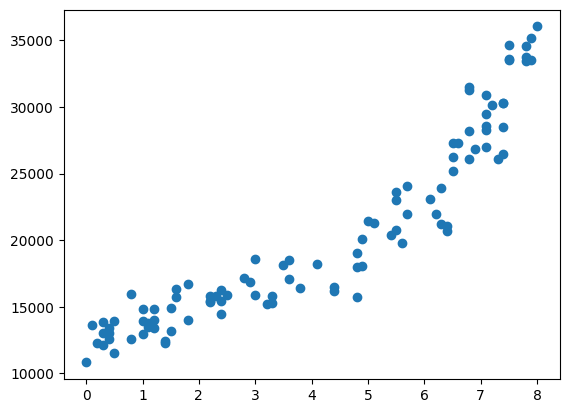
1 | plt.scatter(df['工龄'], df['薪水']) |
1 | plt.figure(figsize=(10, 4)) |
发现数据无异常值和缺失值,接下来我们直接使用各种模型进行应用
拆分数据
1 | from sklearn.model_selection import train_test_split |
线性回归
1 | from sklearn.linear_model import LinearRegression |
mse: 4855442.658615259
r2: 0.8815705091563912
随机森林
1 | from sklearn.ensemble import RandomForestRegressor |
mse: 2389839.0208794717
r2: 0.9417092449977235
XGBoost
1 | from xgboost import XGBRegressor |
MSE: 3569750.747018099
r2: 0.9129299235657095
LGBM
1 | from lightgbm import LGBMRegressor |
MSE: 3749728.9875734868
r2: 0.9085400598827179
SVM
1 | from sklearn.preprocessing import StandardScaler |
MSE: 19519338.352298636
r2: 0.5239022546038833
发现其效果并不好 SVM需要进行调参 使用网格优化
1 | from sklearn.model_selection import GridSearchCV |
最佳参数: {‘svr__C’: 1000, ‘svr__gamma’: ‘scale’, ‘svr__kernel’: ‘rbf’}
最佳交叉验证r2: 0.8533151968605445
汇总
上述五种模型的成绩为
| 模型 | r2 |
|---|---|
| 线性回归 | 0.881 |
| 随机森林 | 0.941 |
| XGBoost | 0.912 |
| LGBM | 0.908 |
| SVM | 0.853 |
我们看到 面对同一份数据 不同的模型 其成绩各不相同
在使用线性回归的时候 我们通常假定变量和目标之间存在线性关系 即y=kx 当变量和目标之间的确是存在线性关系时 模型得分会很高 若变量和目标之间不是线性关系 例如 y=kx^2 那线性回归的得分肯定不高
线性回归的特点是简单 复杂性低 泛化稳定 但容易欠拟合
随机森林属于集成算法 训练大量决策树 每颗树用不同的有放回抽烟者 每次分裂时在随机子集特征上寻找最优划分 回归任务就取树预测的平均值
随机森林的特点是鲁棒性好 对异常值不敏感 免交叉验证 对低维数据表现有限
XGBoost是基于梯度提升对思想 逐步构建决策树 每棵树拟合前一轮的残差 采用二阶泰勒展开来加速优化 加入正则化项控制复杂度
XGBoost的特点是准确率高 适用性强 超参数多 调参麻烦
LGBM是一种高效的梯度提升框架
LGBM的特点是训练和预测速度快 内存占用小 适合稀疏数据 容易过拟合
SVM原理是在高维空间中找到一个最优超平面 使得不同类别的样本间隔最大 在回归时 使预测函数在一定容忍范围内尽量平滑
SVM的特点是泛化能力强 适合高维小样本 核函数灵活 计算复杂度高 参数敏感 可解释性差
- Title: 商业数据分析--IT行业收入表
- Author: 姜智浩
- Created at : 2025-09-18 11:45:14
- Updated at : 2025-09-18 18:44:34
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/09/18/20250918商业数据分析--IT行业收入表/
- License: This work is licensed under CC BY-NC-SA 4.0.