一周科技资讯第一期

大模型强化学习新突破——SPO新范式助力大模型推理能力提升!
文章来源
机器之心
https://www.jiqizhixin.com/articles/2025-06-08-6
当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
然而,要实现有效的强化学习,需要解决一个根本性的挑战,即信用分配问题(credit assignment):在大语言模型的场景下,如何将整个序列(LLM 的回复)最终的评估结果,归因到序列中具体的决策动作(token)上。
这一问题的困难在于奖励信号非常稀疏 — 只能在序列结束时才能获得明确的成功或失败反馈。
当前主要方法
在强化学习中,通常采用优势值估计(advantage estimation)的方法来解决信用分配问题。目前针对大语言模型的强化学习方法主要分为两类,它们之间的区别在于优势值估计的粒度不同。
粗粒度的轨迹级 (trajectory-level) 方法,如 DeepSeek R1 使用的 GRPO,只根据最终的奖励为整个序列计算一个优势值。这种方法虽然高效但反馈信号过于粗糙,LLM 无法对错误回答中正确的部分进行奖励,也无法对正确回答中冗余的部分进行惩罚。
另一种极端是细粒度的 token 级(token-level)方法,如经典的 PPO。这类方法为每个 token 估计优势值,需要依赖额外的 critic 模型来预测每个 token 的状态价值(V 值)。然而,在大语言模型的强化学习任务中,不同 prompt 对应的轨迹分布差异很大,而且在训练过程中每个 prompt 采样出来的模型回复数量非常有限,critic 模型难以训练好,造成 token 级的优势值估计误差很大。
新的 SPO 框架
为突破这一瓶颈,来自中科院软件所和香港城市大学的的研究团队创新性提出了 Segment Policy Optimization (SPO) 框架。
论文题目:Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
作者:Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, Shuang Qiu
SPO 使用了一种中等粒度的段级(segment-level)优势值估计方式。它不像轨迹级方法只在最后一步计算优势,也不像 token 级方法每步都计算优势,而是将生成的序列划分为若干相连的段,计算每个段的优势值。
这种段级的优势值估计方式具有几个明显的优势:
(1) 更优的信用分配:相比轨迹级方法,段级方法能够提供更局部化的优势反馈,让模型能够奖励错误回答中仍然有价值的部分,同时也能惩罚正确回答中冗余和无效的片段。
(2) 更准确的优势值估计:相比 token 级方法,段级方法所需的估计点数量更少,从而能够有效利用蒙特卡洛(Monte Carlo, MC)采样得到更加准确且无偏的优势值估计,而无需再依赖额外且不稳定的 critic 模型。
(3) 更灵活、更易调整:段级的划分方式可以任意定义,并不要求语义上的完整性,因此可以灵活地在 token 级与轨迹级之间自由调整粒度,并且可以适应不同的任务和应用场景。
SPO 框架主要包含三个核心部分:(1) 灵活的段级划分策略;(2) 基于蒙特卡洛采样的段级优势值估计;(3) 利用段级优势值进行策略优化。
这种模块化的设计使框架具备高度的灵活性,不同的部分可以有不同的实现策略,以适用不同的应用场景。
该团队进一步针对不同的推理场景提出 SPO 框架的两个具体实例:对于短的思维链(chain-of-thought, CoT)场景,提出了 SPO-chain,该方法使用基于切分点(cutpoint-based)的段划分和链式优势值估计;对于长 CoT 场景,提出极大提升 MC 采样效率的树形结构优势值估计方法。
此外,该团队还提出了一种 token 概率掩码(token probability-mask)策略优化方法,选择性的对段内的低概率 token 计算损失而非段内的所有 token。作者认为这些 token 是模型推理轨迹可能发生分叉的地方,是段级优势值产生的主要原因。这种方法可以用于 SPO-chain 和 SPO-tree,从而进一步强化信用分配。
框架及核心技术
SPO 框架主要围绕以下三个具有挑战性的问题进行设计:(1) 如何将生成的序列划分为多个段?(2) 如何准确且高效地估计每个段对应的优势值?(3) 如何利用段级优势值来更新策略?SPO 的三个核心模块分别解答上面三个问题,每个模块包含多种可选策略,来适用于不同的场景: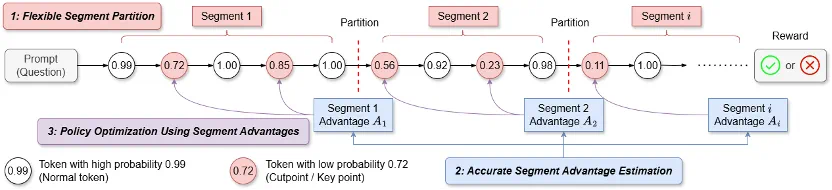
- 段划分 (Segment Partition):
a) 基于切分点的段划分 (Cutpoint-based Partition): 为短思维链场景设计,将段划分点放置在状态值(V 值)更有可能发生变化的地方。根据 token 概率动态确定段边界,优先在模型 “犹豫” 或可能改变推理路径的关键点(cutpoints)进行划分,使信用分配更精确。比如,在下图例子中,标记为红色的 token 是关键点,而标记为蓝色的竖杠是分段结果。
b) 固定 token 数量段划分 (Fixed Token Count Partition): 将序列划分为固定长度的段,便于树形结构的组织和优势值估计,为 SPO-tree 设计。
- 段级优势值估计(Segment Advantage Estimation):
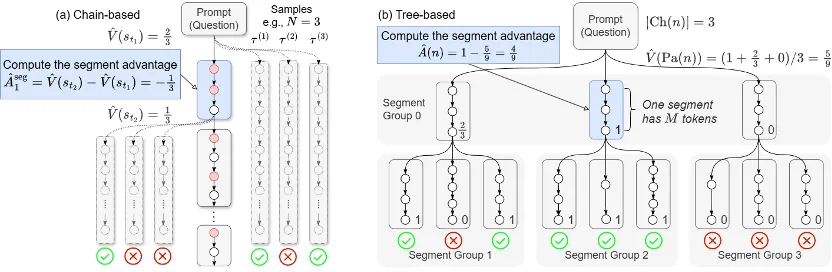
a) 链式优势值估计 (Chain-based) 方法:在短思维链场景下,MC 采样的成本不高,该团队采用一种直接的段级优势值估计方式,独立估计每个段边界的状态值(V 值),然后计算段级优势值。以下公式展示了链式优势值的估计方法。
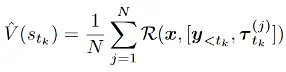
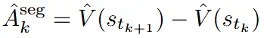
b) 树形优势值估计 (Tree-based): 在长思维链场景下,MC 估计的代价很高,团队提出了一种高效的树形估计方法:将采样轨迹组织成树形结构,通过自底向上的奖励聚合计算状态价值(V 值),同一个父节点的子节点形成一个组,在组内计算每个段的优势值。这种方式将用于 V 值估计的样本同时用于策略优化,极大提高了样本效率。以下公式展示了树形优势值估计方法。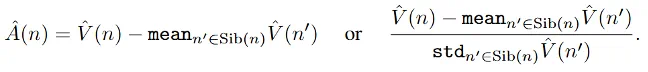
3. 基于段级优势值 token 概率掩码策略优化(Policy Optimization Using Segment Advantages with Token Probability-mask):
在得到段级优势值以后,为了进一步提高信用分配,团队创新性地提出 token 概率掩码策略优化方法,在策略更新仅将段级优势值分配给该段内的低概率(关键)token,而非所有 token。这种方法能更精确地将奖励 / 惩罚赋予关键的决策点,提升学习效率和效果。下面分别展示了 SPO-chain 和 SPO-tree 的优化目标。
a) SPO-chain 优化目标:
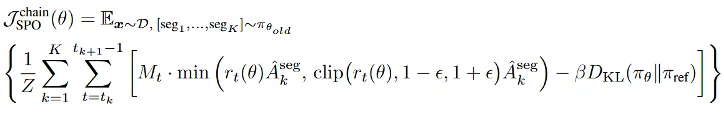
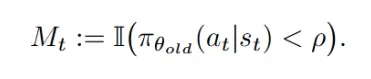
b) SPO-tree 优化目标:
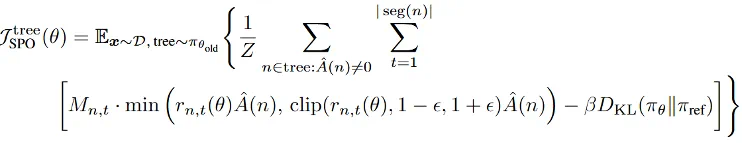
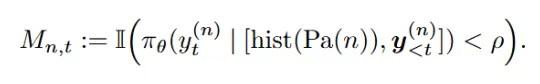
对比基线方法
如下图所示,在短思维链场景,使用 RhoMath1.1B 作为基座模型,使用 GSM8K 训练集进行训练,对比各种训练算法,使用 SPO 训练得到的模型测试集正确率更高。

对于长思维链场景,如下图所示,使用 DeepSeek-R1-Distill-Qwen-1.5B 作为基座模型,使用 MATH 数据集进行训练,在相同的训练时间下,测试集正确率比 GRPO 更高。
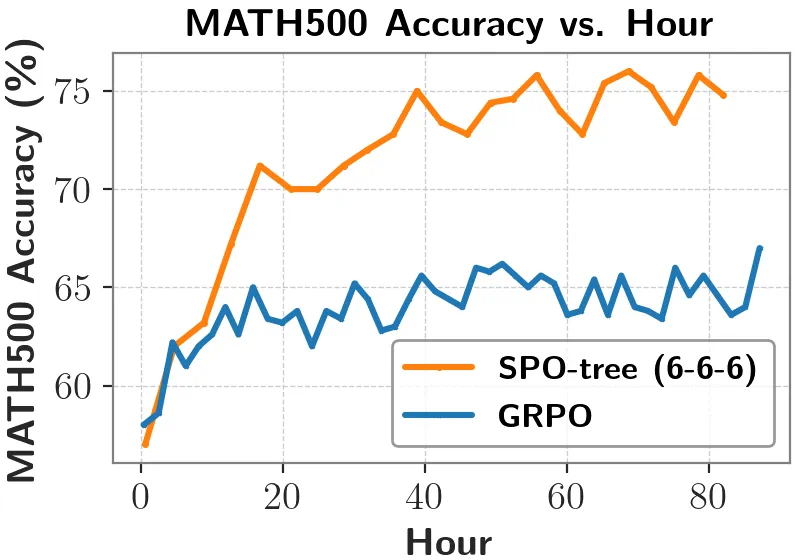
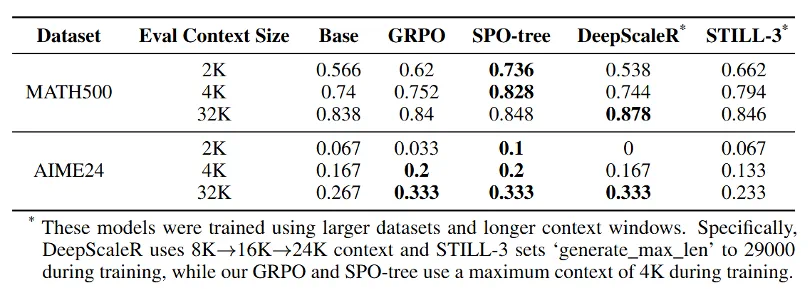
下表展示了在长思维链场景下的更多对比结果:与同期基于相同基座模型(DeepSeek-R1-Distill-Qwen-1.5B)并使用 GRPO 方法训练得到的模型(DeepScaleR、STILL-3)相比,尽管 SPO 仅使用 MATH 数据集且仅使用 4K 的最大上下文长度进行训练,SPO-tree 在各个上下文长度评测下表现优秀。值得注意的是,尽管 DeepScaleR 在 32K 上下文长度评测下表现最佳,但它在较短上下文长度(2K 与 4K)下却表现最差,甚至不及原始基座模型。这表明,GRPO 训练方法可能未有效优化模型的 token 效率,导致输出存在较多冗余,从而在上下文长度有限的情形下出现正确率下降的问题。
分段粒度的影响
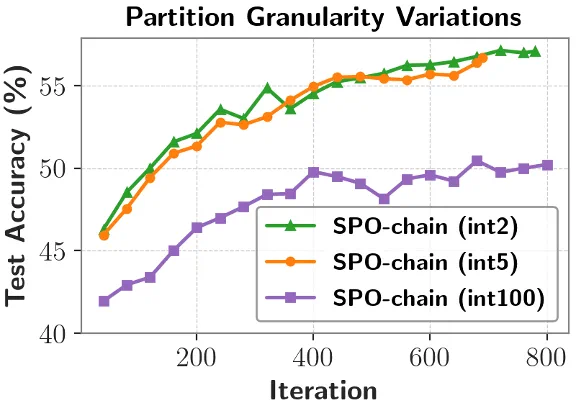
通过实验发现,很细的粒度 (int2,每个两个切分点进行分段),相比于中等粒度 (int5),仅有微小提升,但是过粗的粒度 (int100),相比于中等粒度 (int5),正确率下降很大。证明了 SPO 采用中等粒度优势值的有效性。
段划分方式的影响
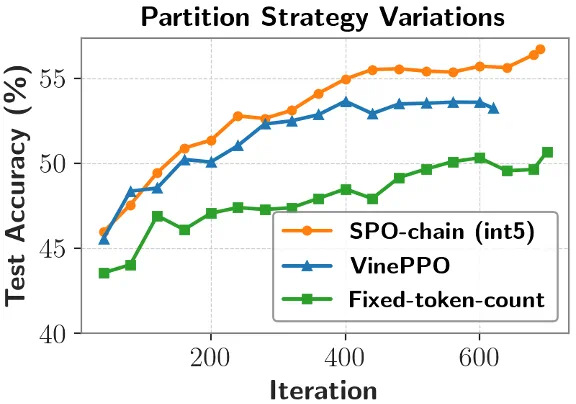
实验表明,在短思维链场景下,采用提出的基于切分点的段划分方式效果最好,优于采用换行符进行划分(VinePPO)以及固定 token 数量划分(Fixed-token-count)。
Token 概率掩码消融
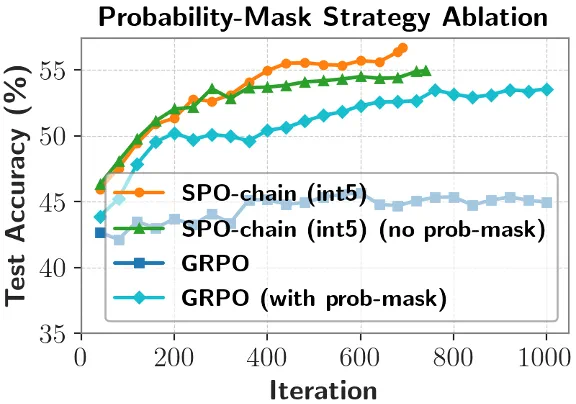
实验表明,将 token 概率掩码去除会导致 SPO-chain 正确率下降,更值得注意的是:将 token 概率掩码应用到 GRPO 上,会让其正确率有明显上升。
不同树结构的影响
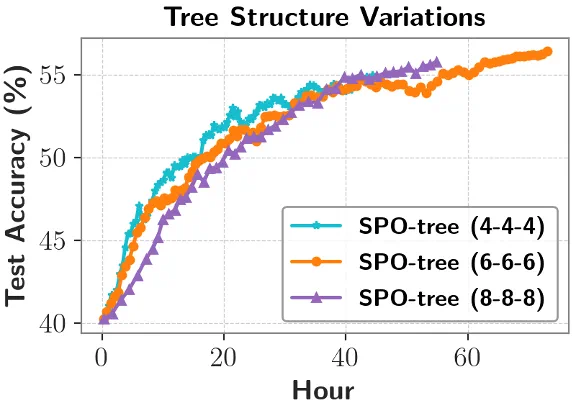
实验表明,更小的树结构在早期正确率更高,可能因为更快扫过更多的数据样本。然而随着训练的进行,更大的树结构会有更好的正确率,因为更大的树结构对于段级优势值的估计更加准确。
总结
该工作提出了一种基于中间粒度段级优势值的 RL 训练框架 SPO,在 token 级和轨迹级之间更好的平衡,具有比轨迹级更好的信用分配,同时仅需要少量优势值估计点,可以使用有效无偏的 MC 方式进行估计,不需要额外的 critic 模型。
文章同时提出了 SPO 的两个实例,为短思维链场景设计的 SPO-chain 以及为长思维链场景设计的 SPO-tree,通过实验证明了 SPO 框架和两个实例的有效性。
通过扩展费马大定理背后的关键见解的范围,四位数学家在构建数学“大统一理论”方面取得了巨大进步。
文章来源
https://www.quantamagazine.org/the-core-of-fermats-last-theorem-just-got-superpowered-20250602/、
1994年,一个震撼数学界的证明——数学家安德鲁·怀尔斯终于解决了费马大定理——这个数论领域的核心问题,三个多世纪以来一直悬而未决。这个证明不仅让数学家们着迷,还登上了《纽约时报》的头版。
但为了实现它,怀尔斯(在数学家理查德泰勒的帮助下)首先必须证明一个更微妙的中间陈述——其含义超出了费马难题。
这个中间证明涉及证明一种名为椭圆曲线的重要方程总是可以与一个完全不同的数学对象(称为模形式)联系起来。怀尔斯和泰勒本质上打开了连接不同数学领域的大门,揭示了每个领域看起来都像是另一个领域的扭曲镜像。怀尔斯和泰勒表明,如果数学家想要理解椭圆曲线,他们可以进入模形式的世界,找到并研究该对象的镜像,然后将他们的结论带回原处。
这种世界之间的联系被称为“模块化”,它不仅帮助怀尔斯证明了费马大定理,数学家们也很快利用它在各种先前难以解决的问题上取得了进展。
模块化也构成了朗兰兹纲领的基础。朗兰兹纲领是一套旨在发展数学“大统一理论”的宏大猜想。如果这些猜想成立,那么椭圆曲线以外的各种方程都将同样与其镜像域中的对象相联系。数学家将能够随心所欲地在两个世界之间跳跃,从而解答更多问题。
然而,证明椭圆曲线与模形式之间的对应关系却异常困难。许多研究人员认为,建立一些更为复杂的对应关系几乎是不可能的。
现在,一个由四位数学家组成的团队证明了他们错了。今年二月,他们终于成功扩展了模块化连接从椭圆曲线到更复杂的方程式,即阿贝尔曲面。团队——弗兰克·卡莱加里芝加哥大学乔治·博克瑟和托比·吉伦敦帝国理工学院和Vincent Pilloni法国国家科学研究中心的研究人员证明了,属于某一主要类别的每个阿贝尔曲面总是可以与一个模形式相关联。
Ana Caraiani表示:“我们大多相信所有的猜测都是正确的,但看到它真正实现,我们感到非常兴奋。”伦敦帝国理工学院的数学家。“而且这是你真的以为遥不可及的事情。”
这只是一场耗时多年的探索的开始——数学家们最终希望证明每个阿贝尔曲面都具有模性。但这一结果已经能够帮助解答许多悬而未决的问题,就像证明椭圆曲线的模性开辟了各种新的研究方向一样。
挑战数学界的「禁区」
椭圆曲线是一种非常基本的方程类型,它只包含两个变量——x和y 。如果你画出它的解,你会看到一些看似简单的曲线。但这些解之间有着丰富而复杂的相互关联,并且它们出现在数论的许多重要问题中。例如,伯奇和斯温纳顿-戴尔猜想——数学中最难的开放性问题之一,第一个证明它的人将获得100万美元的奖励——就是关于椭圆曲线解的性质的。
椭圆曲线很难直接研究。因此,数学家有时喜欢从不同的角度来研究它们。
这就是模形式发挥作用的地方。模形式是一种高度对称的函数,它出现在一个表面上独立的数学研究领域——分析。由于模形式表现出如此多的良好对称性,因此更容易处理。
乍一看,这些对象似乎毫无关联。但泰勒和怀尔斯的证明表明,每条椭圆曲线都对应一个特定的模形式。它们具有某些共同的性质——例如,描述椭圆曲线解的一组数字也会出现在其对应的模形式中。因此,数学家可以利用模形式对椭圆曲线获得新的见解。
但数学家们认为泰勒和怀尔斯的模定理只是一个普遍事实的例子。除了椭圆曲线之外,还有一类更为普遍的对象。所有这些对象在更广阔的对称函数世界(例如模形式)中也应该有一个伙伴。这本质上就是朗兰兹纲领的全部内容。
椭圆曲线只有两个变量——x和y——因此可以画在平面纸上。但如果添加另一个变量z,就会得到一个存在于三维空间中的曲面。这种更复杂的物体被称为阿贝尔曲面,与椭圆曲线一样,它的解也具有数学家们渴望理解的复杂结构。
阿贝尔曲面对应着更复杂的模形式,这似乎很自然。但额外的变量使得它们的构造更加困难,解也更加难求。证明它们也满足模性定理似乎完全遥不可及。“这是一个众所周知的问题,人们不去思考,因为人们思考过却陷入了困境,”吉说道。
但 Boxer、Calegari、Gee 和 Pilloni 想要尝试。
寻找桥梁
这四位数学家都参与了朗兰兹纲领的研究,他们想要用“现实生活中真正出现的物体,而不是某种奇怪的东西”来证明其中一个猜想,卡莱加里说。
阿贝尔曲面不仅在现实生活中出现——确切地说,在数学家的生活中——而且证明关于它们的模性定理将打开新的数学大门。“如果你有了这个命题,你就能做很多事情,而如果没有这个命题,你就无法做到,”卡莱加里说。
这两位数学家于2016年开始合作,希望遵循泰勒和怀尔斯证明椭圆曲线时的步骤。但对于阿贝尔曲面来说,这些步骤中的每一个都复杂得多。
因此,他们专注于一种特殊类型的阿贝尔曲面,称为普通阿贝尔曲面,这种曲面更容易处理。任何这样的曲面,都有一组数字描述其解的结构。如果他们能证明同一组数字也能从模形式推导出来,那就大功告成了。这些数字将充当一个独特的标签,让他们能够将每个阿贝尔曲面与一个模形式配对。
问题在于,虽然对于给定的阿贝尔曲面,这些数字很容易计算,但数学家们却不知道如何构造一个具有完全相同标记的模形式。当需求如此受限时,模形式实在太难构建了。“你正在寻找的对象,你并不知道它们真的存在,”皮洛尼说。
相反,数学家们证明了,只需构造一个模形式,其数值在较弱的意义上与阿贝尔曲面的数值相匹配就足够了。该模形式的数值只需在所谓的时钟算术领域等价即可。
想象一个时钟:如果时针从 10 开始,经过四个小时,时钟将指向 2。但是时钟算术可以用任何数字来完成,而不仅仅是(就像现实世界的时钟一样)数字 12。
Boxer、Calegari、Gee 和 Pilloni 只需要证明,当他们使用一个精确到 3 的时钟时,他们的两组数字相匹配。这意味着,对于给定的阿贝尔曲面,数学家在构建相关模形式时具有更大的灵活性。
但事实证明,即便如此,这也太难了。
然后,他们偶然发现了大量模形式,其对应的数字很容易计算——只要他们根据最高可达 2 的时钟来定义它们的数字。但阿贝尔曲面需要一个最高可达 3 的时钟。
数学家们对如何粗略地连接这两个不同的时钟已经有了想法。但他们不知道如何使这种连接严密无懈可击,以便在模形式的世界中找到与阿贝尔曲面真正匹配的公式。后来,一个新的数学概念出现了,结果证明这正是他们所需要的。
惊喜帮助
2020 年,数论学家潘略发布了证明关于模块化形式的研究,起初似乎与四人组的问题无关。但他们很快意识到,他所开发的技术出奇地相关。“我没想到,”潘说。
经过多年的定期会议(主要通过Zoom),数学家们开始在应用潘建伟的技术方面取得进展,但主要的障碍仍然存在。后来,在2023年夏天,Boxer、Gee和Pilloni认为在德国波恩举行的一次会议是他们聚在一起的绝佳机会。唯一的问题是,Calegari原计划在同一时间前往中国发表演讲。但一次前往芝加哥中国领事馆的艰难旅程让他重新考虑了这个想法。“八小时后,我的签证被拒签了,我的车也被拖走了,”他说。他决定放弃在中国的演讲,前往德国与他的同事们会合。
吉为团队在豪斯多夫研究所的地下室安排了一间房间,这样他们就不太可能被四处奔波的数学家打扰。在那里,他们花了整整一周的时间研究潘氏定理,日复一日,连续工作12个小时,只是偶尔上到地面喝咖啡。“喝完咖啡后,我们总是开玩笑说,我们得回矿井了,”皮洛尼说。
努力终有回报。“后来虽然有很多波折,”卡莱加里说,“但到那一周结束的时候,我觉得我们差不多成功了。”
又花了一年半的时间,才将卡莱加里的定罪证明整理成长达 230 页的证据,并于 2 月份将其发布到网上. 把所有的碎片放在一起,他们证明了任何普通的阿贝尔曲面都有一个相关的模形式。
他们的新门户未来或许能像泰勒和怀尔斯的成果一样强大,揭示出比任何人想象的都更多的关于阿贝尔曲面的信息。但首先,团队必须将他们的成果扩展到非常规阿贝尔曲面。他们已经与潘合作继续探索。“十年后,如果我们还没能找到几乎所有的阿贝尔曲面,那我才惊讶,”吉说道。
这项工作也使数学家们得以提出新的猜想——例如伯奇和斯温纳顿-戴尔猜想的类似猜想,它涉及阿贝尔曲面而非椭圆曲线。安德鲁·萨瑟兰说:“现在我们至少知道,对于这些普通曲面来说,这种类似猜想是合理的。”麻省理工学院的数学家。“以前我们不知道这一点。”
“我曾经梦想有一天能够证明的很多事情,现在都因为这个定理而触手可及了,”他补充道,“它改变了一切。”
第一张由固体秘密量子几何构成的地图
文章来源
http://quantamagazine.org/first-map-made-of-a-solids-secret-quantum-geometry-20250606/
物理学家最近利用一种有望普及的新方法绘制出了晶体量子行为背后的隐藏形状。
众所周知,在量子尺度上,粒子可以同时处于多个可能的位置。粒子的状态像波一样向外扩散,在其可能出现的位置达到峰值。当你测量它的位置时,这种扩散状态(称为波函数)会转变为一个确定的位置。
波函数的完整形状长期以来一直难以探测,因为试图测量它会破坏它。但在20世纪80年代,物理学家开始开发测量和控制简单系统波函数的方法——这些进步后来构成了量子计算的基础。而在过去几年里,一种新的方法使物理学家能够更进一步,了解整个材料的波函数。
里卡多·科明说:“我们正处于第二次量子革命。”麻省理工学院实验物理学家,也是这项工作的领导者之一。“现在,我们拥有了真正探索量子粒子波函数的工具。”
新框架将波函数描述为一个在隐藏景观中移动的物体——这个空间被称为物质的“量子几何”。这个看不见的世界的山丘和山谷决定了给定物质的波函数如何变化,以及物质可以处于什么状态。
马克·博克拉斯说:“你可以深入了解量子材料中发生的事情,这可能会加速新现象的发现。”他是俄亥俄州立大学的物理学家,也是量子几何学领域的领军人物。
Comin 和他的同事最近测量了晶体的完整量子几何形状— 首次窥视真实材料的波函数。
让我们探索一下即将出现的隐藏景观。
秘密几何
物理学家通常将粒子的波函数想象成一支箭头。如果粒子有两种可能的状态,他们就把这些选项表示为箭头指向的相反方向——比如向上和向下。如果粒子同时处于两种状态,那么箭头指向球体周围的某个位置,这两种状态分别对应极点。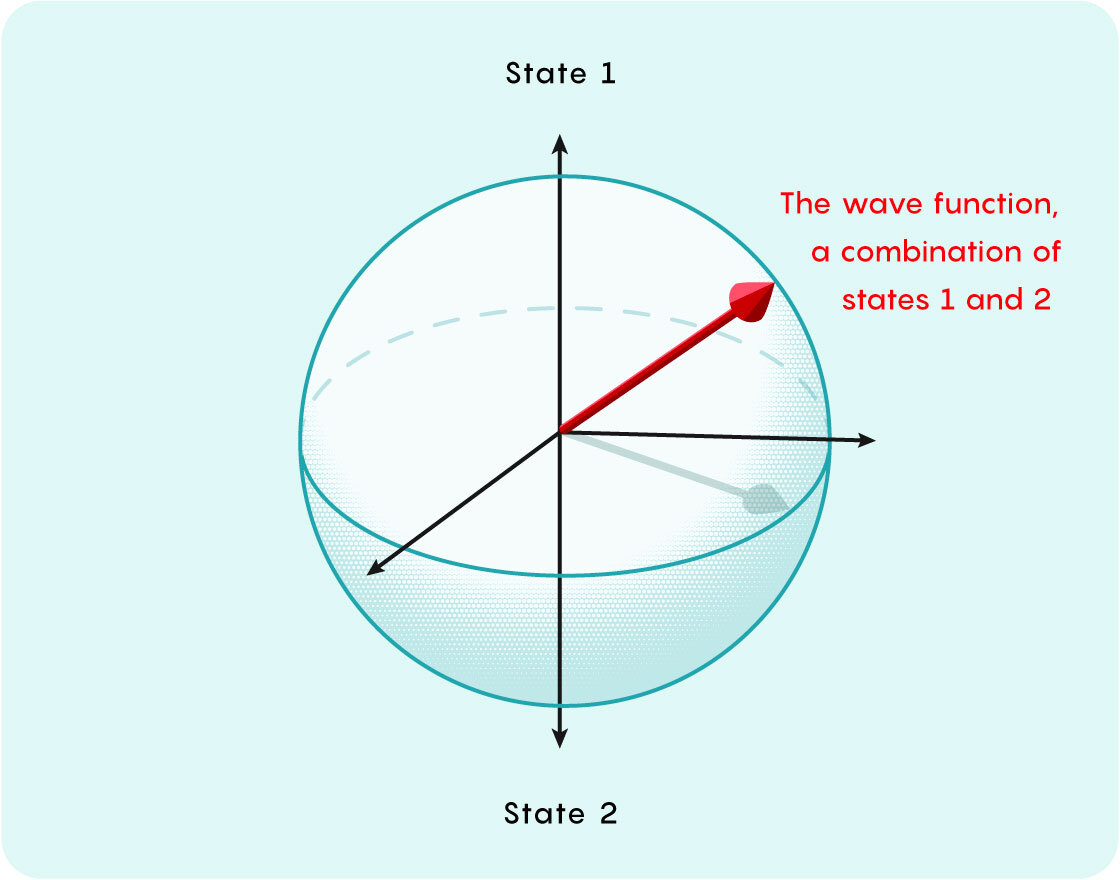
箭头的方向反映了每种可能性的相对可能性。测量粒子会使箭头指向正上方或正下方,而每种结果的概率取决于它最接近哪个极点。
许多粒子拥有两种以上的可能状态,在这种情况下,箭头占据着一个高维空间。这无法直观地呈现,但数学知识能让物理学家了解粒子在特定时刻的波函数。
对于由许多粒子构成的材料,一个高维箭头可以表示其内部所有电子的组合状态。随着材料周围环境条件(例如温度或周围磁场强度)的改变,这个集合箭头会随之摆动。为了控制一种材料,物理学家需要知道在转动这些不同的旋钮时,箭头会如何旋转。
为了追踪,他们绘制了一张地图。例如,想象一下,你改变施加于材料上的磁场强度。在你的地图上,你将使东西方向与磁场强度相对应。当磁场较弱时(对应地图上的西),电子的波函数会处于某种状态,你可以用箭头表示。当磁场较强时,你的位置会更靠东,波函数也会呈现不同的状态。当你在地图上从西向东移动时,箭头会旋转,显示电子的波函数如何随着磁场的增减而变化。
此图可扩展,捕捉所有可调整材质的方式。每个可调节的旋钮或参数都会在图中增加一个可移动的新维度。
想象一下,当你在地图上移动时,追踪箭头旋转的速度。有了这些信息,地图就变成了3D,就像你在绘制山脉一样。地图上每个部分的地势越陡峭,电子的波函数围绕这些参数值的变化就越大。如果变化很大,你就在山上。如果一点变化都没有,你就在平地上。
一种名为量子度量的数学对象捕捉了这种景观的形状。它通过描述两点之间最短距离的路径来实现这一点。正如从纽约飞往北京的飞机不会穿过地球,而是会在地球表面弯曲飞行一样,两个量子态之间的路径揭示了它们所处的底层几何形状。
波函数的这种神秘几何结构几十年来一直未被发现。但当量子材料开始以其难以解释的行为让物理学家们感到惊讶时,20世纪80年代的物理学家们意识到,其中一些行为可以用材料波函数绕弯曲形状传播来解释。
想象一下,一支箭在平面上移动。它的方向不会改变。但在曲面上,当它绕着一个闭合的圆环移动后,箭头指向的方向会与它开始时不同。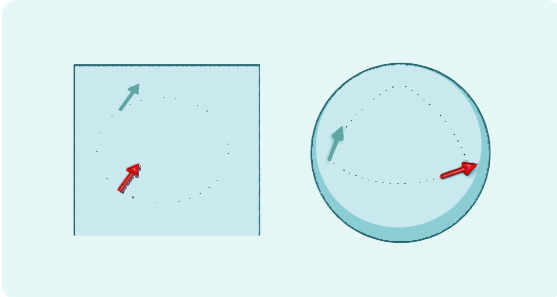
同样的事情也可能发生在量子态上。想象一下,改变一种材料的条件,使波函数在图中移动,然后再将材料恢复到其初始状态。如果现在它的箭头指向一个新的方向,那么这种材料就是“拓扑的”:它隐藏的底层形状迫使材料进入了一种新的状态。
由底层拓扑结构引起的方向变化被称为贝里相,以推广这一概念的英国理论物理学家迈克尔·贝里的名字命名这个相位在循环路径上累积的方式称为贝里曲率,指的是箭秘密穿越的弯曲形状。
对科明来说,贝里相是“固体量子理论中最迷人的概念之一”。尽管贝里相长期以来未被实验者发现,但它却能产生奇异的物理后果。
撒糖甜甜圈
这种抽象的几何学在像科明这样的物理学家研究晶体(原子以重复模式排列的晶格)的实验室中变得栩栩如生。近年来,他们发现二维晶体(原子的扁平晶格,电子可以在其中双向移动)具有各种各样的量子行为。让我们看看为什么二维晶体的量子几何图会呈现出一种甜甜圈状的形状,称为环面。
一般来说,晶体中重复的模式限制了其中电子的可能状态。电子可以快速流动、缓慢流动,或者根本不流动,每种选择都对应着不同的集体波函数。对于二维晶体,物理学家可以在一张纸上绘制出可能状态的图:每个坐标对应于电子在垂直和水平方向上可能的动量。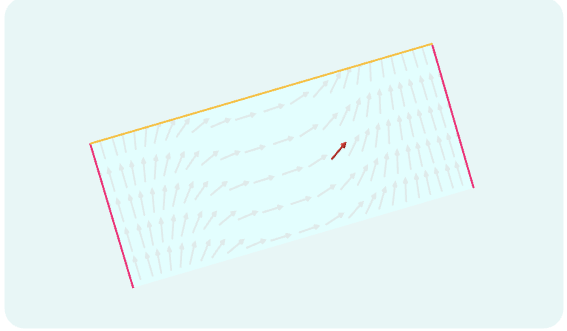
由于晶体状态图会重复出现,因此沿着平面图边缘的一个方向移动会将你带回到另一侧。为了证明这一点,物理学家将平面图卷绕两次。首先,平面图变成圆柱体,然后圆柱体的两端相接,形成一个圆环。
改变条件,例如通过晶体运行电流,将改变电子的运动,这将推动这个圆环状地图上的箭头。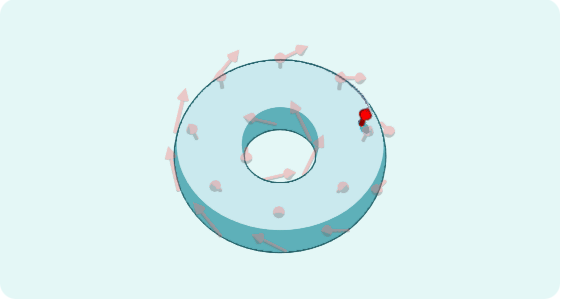
尤其是对于拓扑材料来说,调节旋钮,然后回到初始条件——换句话说,沿着环面追踪一条循环路径——会使电子的箭头指向与之前不同的方向。这意味着多个箭头,或者说波函数,可以在环面上的同一点共存,从而形成一个“不连续点”。
当电子经过这样的点时,它们的集体箭头突然翻转,材料的状态发生剧烈变化。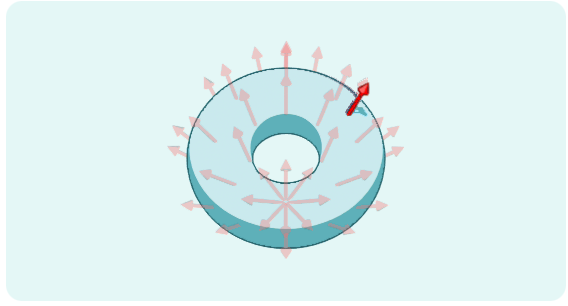
这种效应类似于电荷通过时,电子所受的力也会发生翻转。因此,拓扑材料可以被解读为承载着幽灵电荷,这些电荷会导致电子移动,就像感受到一个并不存在的力场一样。
20世纪80年代发现的“幽灵场”巩固了量子态隐藏几何结构与材料行为之间的联系。这项研究成果荣获2016年诺贝尔物理学奖。
未知领域
拓扑材料已不再神秘:物理学家们通常利用它们来发现物质的新相,并探索其在量子计算中的潜力。但直到最近,他们才开始欣赏量子几何的更完整图景,它不仅包括贝里曲率,还包括量子度规——一种存在于环面形地图顶部的崎岖地形的形状。几年前,量子度规帮助研究人员理解了二维晶体中发生的情况,这种晶体中存在着一种奇特的新型超导性。— 无阻力的电流流动。
新的量子算法用一个量子比特分解数字
量子计算机目前仍然能力有限。几乎每次研究人员发现这些高科技机器未来应该擅长的领域时,总会有一种经典算法在普通计算机上也能同样出色地完成。一个值得注意的例外?分解数字。1994年,数学家彼得·肖尔(Peter Shor)设计了一种算法,使量子计算机能够以比传统机器更快的速度对大数进行因式分解。这种加速至关重要,因为快速因式分解算法可以使大多数数据加密方法失效。30多年来,研究人员一直在努力提升未来量子计算机的性能,并防范其进一步发展。
但Shor的因式分解算法也有局限性:要分解的数字越大,所需的量子计算机就越大、性能就越好。破解一个加密方案需要一台量子计算机在数十万台计算机上运行Shor的算法。高效量子比特(qubits)的计算能力。而如今的机器还远远达不到这个水平。
但一篇论文发布在科学预印本网站arxiv.org上的一篇论文描述了如何用少得多的量子比特(仅需一个)对任意数进行因式分解。在这项新研究中,研究人员展示了如何用一个量子比特和三个被称为振荡器的组件(振荡器是一种通常与其他量子技术(如光学系统)相关的现成设备)对任意大小的整数进行因式分解。
需要明确的是,这并非一项实用的进步:这个过程所需的能量比百万量子比特的量子计算机高出数倍。但它确实阐明了解决这类问题的新方法。“这不同于我们对计算的典型思考方式——不仅是量子计算,还有经典计算,” Ulysse Chabaud说。巴黎高等师范学院的计算机科学家,他没有参与这项新方法的研究。“这看起来很疯狂,甚至是不可能的。”
良好的振荡
归根结底,新方法之所以有效,在于其信息编码方式。经典计算机使用比特,比特可以取两个值之一。而量子比特,由于量子力学的复杂性,可以取多个值。但即使是量子比特,一旦被测量,也只能取两个值之一:0 或 1。
但罗伯特·科尼格表示,这并不是在量子设备中编码数据的唯一方法和卢卡斯·布伦纳慕尼黑工业大学。他们的工作重点是研究如何利用连续变量对信息进行编码,这意味着它们可以采用给定范围内的任意值,而不仅仅是某些特定的值。
过去,研究人员曾尝试改进Shor的因式分解算法,方法是使用连续系统模拟量子比特,并扩展其可能值集。但即使你的系统使用连续量子比特进行计算,它仍然需要大量的量子比特来分解数字,而且计算速度不一定更快。“我们想知道是否有更好的方法来使用连续变量系统,”König说。
他们决定回归本源。肖尔算法的秘诀在于,它利用被分解的数生成一个研究人员称之为周期函数的函数,该函数的值会以固定的间隔重复出现。然后,它使用一种名为量子傅里叶变换的数学工具来确定该周期的值——也就是函数重复一次所需的时间。由此,一些简单的代数运算就能揭示出原始数的因数。
当 König 和 Brenner 尝试寻找另一种连续的因式分解方法时,他们很快想到了量子振荡器。量子振荡器产生的重复模式,在测量后可以呈现任何连续值(这与量子比特不同)。König 表示,这些模式就像内置的量子傅里叶变换一样。
“我和卢卡斯开始讨论这个混合量子比特振荡器系统,”柯尼格说。但他们当时的想法还很模糊,于是两人请来同事利博·卡哈(Libor Caha)和泽维尔·科伊特-罗伊(Xavier Coiteux-Roy)来设计基于该系统的量子算法。
几个月后,König 团队证明,在使用量子振荡器而非量子比特的系统中,这些物理组件的动态特性确实可以执行因式分解的数学运算——无需模拟量子比特的离散值。他们系统中的单个量子比特读取并组织振荡器中的信息,但并不像其他量子计算机中的量子比特那样执行实际的计算。与 Shor 算法一样,新方法能够在合理的时间内分解整数。
这项研究还指出了在量子计算中实现连续方法的新可能性。“这篇论文表明,通过使用感觉非常合理的操作,他们成功地实现了一些感觉完全不合理的事情,”Chabaud 说。“这是一件非常酷的事情,当结果出来时,我非常兴奋。”
足够短
但这种方法也有一个陷阱:需要分解的数越大,振荡器进行运算所需的能量就越大。因此,分解一个大数虽然只使用一个量子比特,但却需要几乎难以想象的能量。“如果我给你一个大数进行分解,你就必须利用多颗恒星的能量才能运行算法,更不用说控制发生的一切了,”Chabaud 说。
对于阿拉姆·哈罗麻省理工学院的物理学家认为,这使得新的结果毫无用处。“我不明白用这种方式进行整个计算有什么意义。”
但慕尼黑团队已开始着手通过微调振荡器的数量及其运作方式来降低能耗。“或许,使用更多的振荡器就能降低能耗,”柯尼希说道。
因式分解只是这种新计算方法的应用示例之一;该团队正在寻找其他方法。“我们可以尝试将任何量子计算转化为这种装置,”König 说,“不一定非得是 Shor 算法。”他的团队已经证明,量子比特并非计算的唯一引擎,振荡器也可以充当基本的信息载体。而且,量子设备中现有的其他组件也可能被用来执行计算。
“对我来说,这就是这篇论文真正的创新之处,”Chabaud说。“你实际上可以使用连续变量系统运行一些有趣的算法。”
苹果推出 iPadOS 26,带来全新外观和更强大的多任务处理功能
iPad 迎来关键软件更新,实现其真正潜力。15年来,iPad 终于获得了可调整大小和移动窗口等重要功能。这些改进使其更像一台真正的电脑,标志着iPad发展的一个重要里程碑。
苹果在WWDC上发布了全新的iPadOS 26,带来了重大更新。主要亮点是改进的多任务处理功能,包括全新的窗口系统,允许用户自由调整应用窗口大小和位置。新系统还包含新的文件应用、更多Apple Intelligence功能,以及类似Mac的预览应用,用于查看和编辑PDF。iPadOS 26也采用了受Vision Pro启发的“Liquid Glass”视觉语言,并延续了苹果的命名方式,从版本号改为年份。新的窗口系统可以在Stage Manager中使用,并支持多显示器。
iPad 今年迎来了重大更新:苹果刚刚在 WWDC 上发布了其平板电脑操作系统 iPadOS 的新版本。iPadOS 的旗舰功能是用于跨应用多任务处理的全新窗口系统,此外还有全新的文件应用、更多 Apple Intelligence 功能,以及类似 Mac 的预览应用,可用于查看和编辑 PDF。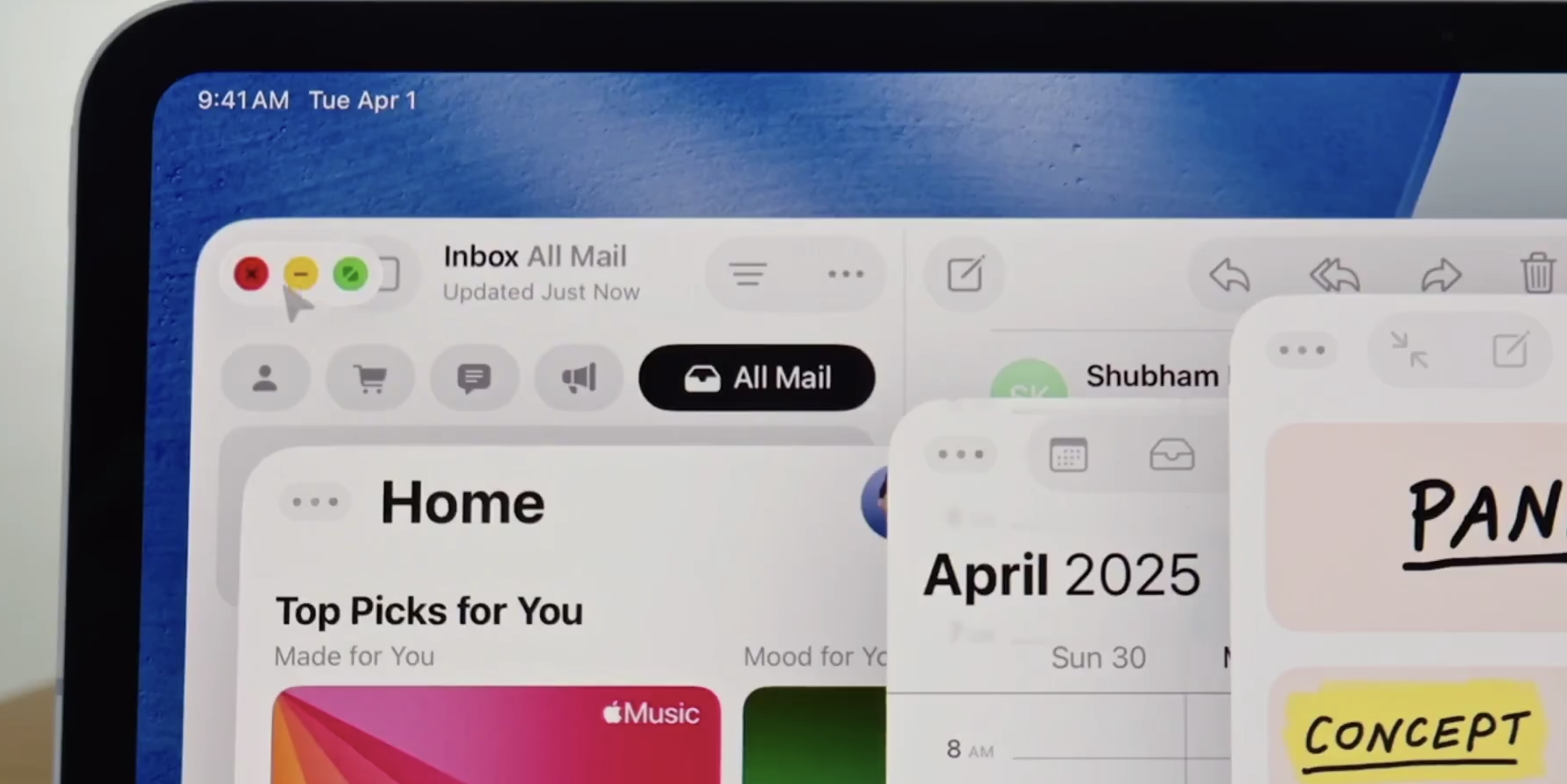
与往常一样,新 iPadOS 与新 iOS 有很多共同之处,包括受 Vision Pro 启发的新视觉语言“液态玻璃”。更新后的名称也遵循了苹果的整体方案,从版本号改为年份。iPad 在多任务处理方式、应用程序之间移动方式以及操作系统方面往往有所不同。在 iPadOS 26 中,这种差异比以往任何时候都更加明显:苹果表示,它将允许您“流畅地调整应用程序窗口大小”并将窗口放置在屏幕上的任何位置。窗口系统也可以在 Stage Manager 中使用,并且可以跨显示器工作。Stage Manager 并不总是最直观的 iPad 软件,但这看起来是朝着正确的多任务处理迈出的坚实一步。
iPad 一直以来都横跨 Mac 和 iPhone,有人认为它应该更像其中之一,而不是完全处于两者之间。今年 WWDC 前的传闻似乎暗示了它更以 Mac 为中心,事实也确实如此。iPad 现在有一个菜单栏,你可以从显示屏顶部向下滑动来访问,其中会显示你正在查看的应用程序的各种控制按钮。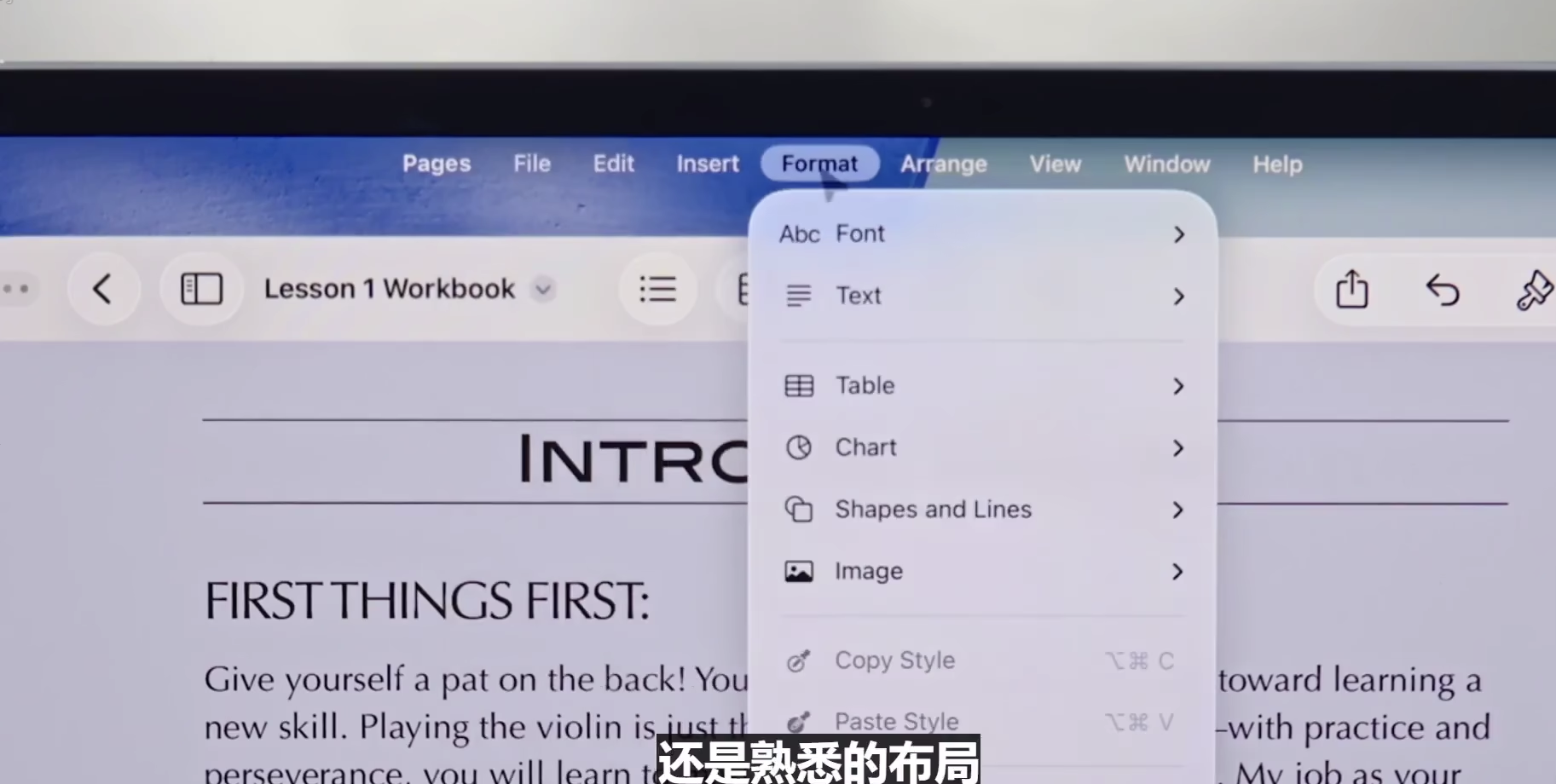
此外,还有一款新的预览应用,苹果称它既可以查看 PDF,也可以标记 PDF(当然,它支持 Apple Pencil)。文件应用中也采用了更 Mac 风格的列表视图。开发者甚至可以让他们的应用在后台运行得更高效,并显示在 Live Activities 中,让你了解当前运行情况。
除了所有高级用户功能外,iPad 还将获得此前仅适用于 iPhone 的 Journal 应用,以及访问 Apple Games hub 的权限,方便用户畅玩所有 Apple 游戏产品。iPad 还新增了一项游戏覆盖功能,让用户无需切换应用即可更新设置并与好友聊天。
新操作系统今日起面向开发者开放。苹果表示,公测版将于下个月发布,更新将于今年秋季正式发布。以下是苹果官方发布的支持设备列表:
- iPad Pro (M4)
- iPad Pro 12.9 英寸(第 3 代及更新机型)、iPad Pro 11 英寸(第 1 代及更新机型)
- iPad Air(M2 及更高版本)、iPad Air(第三代及更高版本)
- iPad (A16)、iPad(第八代及更高版本)
- iPad mini(A17 Pro)、iPad mini(第五代及更高版本)。
地球望远镜为宇宙黎明提供了新的视角
文章来源
https://phys.org/news/2025-06-earth-based-telescopes-fresh-cosmic.html
科学家首次利用地球望远镜回顾过去 130 亿年,以了解宇宙中的第一批恒星如何影响大爆炸发出的光。
天体物理学家利用位于智利北部安第斯山脉高处的望远镜测量了这种偏振微波,从而更清晰地描绘出宇宙历史上最不为人所知的时期之一——宇宙黎明。
“人们认为这不可能在地面上完成。天文学是一个技术受限的领域,而‘宇宙黎明’号发出的微波信号以难以测量而闻名,”项目负责人、约翰·霍普金斯大学物理学和天文学教授托拜厄斯·马里奇说道。“与太空观测相比,地面观测面临着额外的挑战。克服这些障碍使这次测量成为一项重大成就。”
宇宙微波的波长仅为几毫米,非常微弱。偏振微波信号则要弱上百万倍。地球上的无线电广播、雷达和卫星信号可能会掩盖它们的信号,而大气、天气和温度的变化也会使其失真。即使在理想条件下,测量这种微波也需要极其灵敏的设备。
美国国家科学基金会宇宙学大角度尺度探测器(CLASS)项目的科学家使用独特设计的望远镜探测到宇宙大爆炸遗迹中第一批恒星留下的“指纹”——这一壮举此前只有部署在太空的技术才能实现,例如美国国家航空航天局威尔金森微波各向异性探测器(WMAP)和欧洲航天局普朗克太空望远镜。
这项由约翰·霍普金斯大学和芝加哥大学领导的新研究发表在《天体物理学杂志》上。
通过将 CLASS 望远镜的数据与普朗克和 WMAP 太空任务的数据进行比较,研究人员发现了干扰,并缩小了来自偏振微波光的共同信号范围。
当光波遇到某物然后散射时,就会发生偏振。
“当光线照射到汽车引擎盖上时,你会看到眩光,这就是偏振。为了看得清楚,你可以戴上偏光眼镜来消除眩光,”第一作者李云阳(Yunyang Li)说道。李云阳曾是约翰·霍普金斯大学的博士生,后来在研究期间担任芝加哥大学的研究员。
“利用新的通用信号,我们可以确定我们所看到的有多少是从宇宙黎明号引擎盖反射出来的宇宙眩光。”
大爆炸之后,宇宙是一团电子雾,密度之高以至于光能无法逃逸。随着宇宙膨胀和冷却,质子捕获电子形成中性氢原子,微波由此得以自由地穿过其间的空间。在宇宙黎明时期,当第一批恒星形成时,它们强大的能量将电子从氢原子中剥离出来。研究小组测量了来自大爆炸的光子在穿越电离气体云时遇到其中一个被释放的电子并偏离轨道的概率。
中国的复合极端事件与健康风险:综述
文章来源
http://sciencedirect.com/science/article/pii/S1674283425000595?via%3Dihub
中国一项研究表明,复合型极端天气事件正在中国构成潜在的健康危机。这些复合事件,如干旱与热浪并存,或洪涝与空气污染齐至,其综合影响对公众健康构成日益严重的威胁。研究揭示了这些复合事件发生的频率增加,以及它们对不同地区人口健康的影响。该研究强调了应对气候变化和减轻复合极端事件对健康影响的必要性。
在全球恐慌的背景下,中国面临严峻的严酷和严重的极端气候天气事件,其中以多种气候驱动因子和/或灾害应对而导致的复合型极端事件风险亟待突出。 本文首先回顾了中国区域复合型极端事件的定义与划分型; 然后综述了不同类型复合型极端事件的演变特征,形成了机制以及未来股票等方面的研究进展; 探讨了日夜持续型极端高温事件、温湿复合事件以及高温复合事件等三类事件对我国人群健康的潜在风险及可能的影响途径; 最后,风险阐述了复合型极端事件灾害评估框架,并在此基础上提出了基于碳中和目标的应对策略。 在总结上述研究成果的基础上,提出了五个未来预测需关注的研究方向:(1)复合事件灾害风险链的识别问题; (2)安装数据和连接模式性能的抵消问题; (3)复合型极端事件的归因与成因问题; (4)碳排放与空气质量改善的最优化路径问题; (5)多学科、多区域、多部门的合作问题。 加强上述方向的研究有助于深入对复合型极端事件的理解,并为我国气候变化适应和健康风险应对提供科技支撑
近百年来,受全球变暖影响,中国气候发生了显著变化。随着地表温度升高,热浪、极端降雨、干旱、台风、风暴潮等区域极端事件发生的频率和强度都有所增加,对公众健康、生态系统、粮食安全和社会经济系统构成了重大挑战。极端事件通常分为天气极端事件和气候极端事件。极端天气是指在特定时间和地点发生的罕见气象事件,具有统计概率低的特点。而气候极端事件是指气象变量在较长时期内持续异常,有可能导致极端的季节平均值或总量(IPCC,2021)。为推动全球变暖背景下极端事件的研究,世界气象组织和世界气候研究计划成立了气候变化检测和指数专家组(ETCCDI)。该团队基于统一的框架定义了27个具有代表性的极端温度和降水指数(张建军等,2011),广泛应用于全球和区域极端天气气候事件的研究。极端事件的定义通常有两种:基于固定值的绝对阈值和基于百分位数的相对阈值。例如,中国的气象业务系统将连续三天气温超过35℃的时段定义为热浪。但由于气候变量的时空异质性,研究中倾向于使用基于百分位数的相对阈值或基于极值理论的参数估计方法来定义极端事件。
近年来,中国极端事件呈现出三个新特点。一是极端事件分布范围不断扩大,高影响低概率事件频发,灾害影响不再局限于特定区域,而是波及范围越来越广。二是极端事件发生突发性增强,不可预见事件增多,并出现了前所未有的灾害组合。三是极端事件的极端化趋势明显,极端事件发生的频率和强度均有所增加。这些新特点对中国的民生、经济发展和社会公平产生了负面影响,也对气象灾害风险管理、应急响应和气候适应战略提出了重大挑战。与单一驱动因素引发的极端事件相比,两个或多个极端事件同时或连续发生往往造成更为严重的社会和环境后果。这种由多种气候驱动因素和/或灾害共同作用,造成社会或环境风险的现象被称为复合极端事件。这些已经发展成为气候变化研究领域的前沿问题和重大科学挑战( Zscheischler 等,2018;Yu 等,2023 )。
随着中国城镇化和工业化的快速推进,大气污染已成为重大环境问题和居民健康威胁(Zheng et al.,2023)。为解决这些问题,中国政府实施了各种监管措施,例如自2013年以来实施的第一个五年清洁空气行动和蓝天保卫战计划。这些努力使PM 2.5污染明显减少,尽管水平仍未达到世界卫生组织设定的高标准(Xue et al.,2019)。然而,在暖季,中国东部地区近地面臭氧浓度仍然很高,持续性臭氧污染事件发生频率增加。这已成为影响中国夏季空气质量的主要因素。臭氧属于二次污染物,主要通过光化学反应形成,其前体物包括挥发性有机化合物、一氧化碳和氮氧化物。在人口密集的中国东部地区,供暖和交通运输严重依赖化石燃料和生物燃料,导致臭氧前体物排放急剧增加,不仅导致臭氧浓度升高,还催化光化学烟雾的形成,对公众健康、生态系统和农业生产构成严重威胁。
数十年来AlCl偶极矩之谜得以解决
文章来源
https://phys.org/news/2025-06-decades-mystery-alcl-dipole-moment.html
在一项填补基础科学领域长期存在的知识空白的研究中,加州大学河滨分校的研究人员 Boerge Hemmerling 和 Stephen Kane 成功测量了氯化铝 (AlCl) 的电偶极矩,AlCl 是一种简单但在科学上至关重要的双原子分子。
他们的研究成果发表在《物理评论A》上,对量子技术、天体物理学和行星科学具有重要意义。论文题为《利用斯塔克能级光谱法测量氯化铝的电偶极矩》。
到目前为止,AlCl的偶极矩仅被估算,而没有实验证实。这项研究的精确测量如今用可靠的实验数据取代了理论预测。
当分子内部正负电荷分离,导致电子分布不均匀时,就会产生电偶极矩。对于像氯化铝这样的分子来说,它决定了分子之间以及与周围环境的相互作用。
“在化学中,偶极矩影响从键合行为到溶剂相互作用的一切,”物理学和天文学副教授赫默林说。
在生物学中,它们影响着水中氢键等现象。在物理学和天文学中,可以利用偶极矩使相邻分子相互作用,例如,在它们之间建立量子纠缠。
Hemmerling解释说,AlCl在多个科学领域发挥着至关重要的作用。他表示,这种分子已成为超冷量子计算平台开发中一个很有希望的候选材料,而精确理解由偶极矩驱动的分子间相互作用至关重要。
“之前假设的约1.5德拜只是一个历史性的占位符,”Hemmerling说。“我们的实验结果提供的约1.68德拜的最终值可以用于规划高精度实验,并提高理论模型的准确性。”
在渐近巨星支(AGB)恒星的大气中检测到了氯化铝(AlCl),这些恒星正处于恒星演化的晚期阶段。AGB恒星经历了显著的质量损失和元素重新分布;了解它们的化学成分对于追踪恒星和行星的演化至关重要。
地球与行星科学系行星天体物理学教授凯恩说:“准确的偶极矩数据可以改善我们对星光中分子特征的解读。”
我们的发现将有助于改进迄今为止依赖于替代值或估计值的天体物理模型。这包括用于分析詹姆斯·韦伯太空望远镜等尖端天文台数据的模型。
凯恩认为,铝和氯在行星形成的地球化学中分别扮演着不同的角色。他表示,放射性铝同位素有助于核心分化,而氯的分布则有助于绘制行星演化图。
他说:“通过 AlCl 测量揭示的恒星中铝与氯的比例为恒星核合成和这些天体的物质历史提供了关键线索。”
该研究采用了加州大学河滨分校历时七年开发的复杂实验装置,包括定制激光器、真空系统和专为高精度光谱设计的电子设备。
通过在真空中产生 AlCl 光束并分析其光谱行为,该团队与康涅狄格大学的 Daniel McCarron 合作,此前首次能够确定该分子的超精细结构和同位素位移。
加州大学河滨分校的研究小组旨在继续探索 AlCl。
赫默林说:“从提高我们对遥远恒星的理解到实现下一代量子计算机,精确测量 AlCl 的电偶极矩是迈向未来发现的基础性一步。”
“我们现在还可以高精度地研究其他分子和原子,为天体化学、基础物理学和材料科学领域激动人心的新发现铺平道路。”
该团队的下一个目标之一是 HoF,一种可能有助于测试物理学标准模型边界的分子。
“这项研究提醒我们,我们对哪怕是最基本的分子也并非完全了解,”赫默林说,“但现代技术为我们提供了探索的工具。”
该项目与洛斯阿拉莫斯国家实验室的理论家 Brian Kendrick 合作。
更多信息: Li-Ren Liu 等人,利用斯塔克能级光谱测量 AlCl 的电偶极矩,《物理评论 A》(2025 年)。DOI :10.1103/hwwm-1mn7
期刊信息: Physical Review A
苹果的一项新研究质疑人工智能模型是否真正通过问题进行“推理”
文章来源
6月初,苹果研究人员发布了一项研究,表明模拟推理 (SR) 模型(例如 OpenAI 的o1和o3、DeepSeek-R1和Claude 3.7 Sonnet Thinking)在面对需要系统性思维的新型问题时,其输出结果与训练数据的模式匹配结果一致。研究人员的发现与美国数学奥林匹克(USAMO) 4 月份的一项研究结果类似,表明这些模型在新型数学证明方面得分较低。
这项新研究名为“思考的错觉:通过问题复杂性的视角理解推理模型的优势和局限性”,由苹果公司的 Parshin Shojaee 和 Iman Mirzadeh 领导的团队完成,Keivan Alizadeh、Maxwell Horton、Samy Bengio 和 Mehrdad Farajtabar 也参与其中。
研究人员研究了他们所谓的“大型推理模型”(LRM),该模型试图通过生成有时被称为“思路链推理”的审议性文本输出来模拟逻辑推理过程,表面上以逐步的方式帮助解决问题。
为了做到这一点,他们让人工智能模型对抗四个经典谜题——汉诺塔(在桩之间移动圆盘)、跳棋(消除棋子)、过河(在限制条件下运输物品)和积木世界(堆叠积木)——从非常简单(比如一个圆盘的汉诺塔)到极其复杂(20 个圆盘的汉诺塔需要超过一百万次移动)。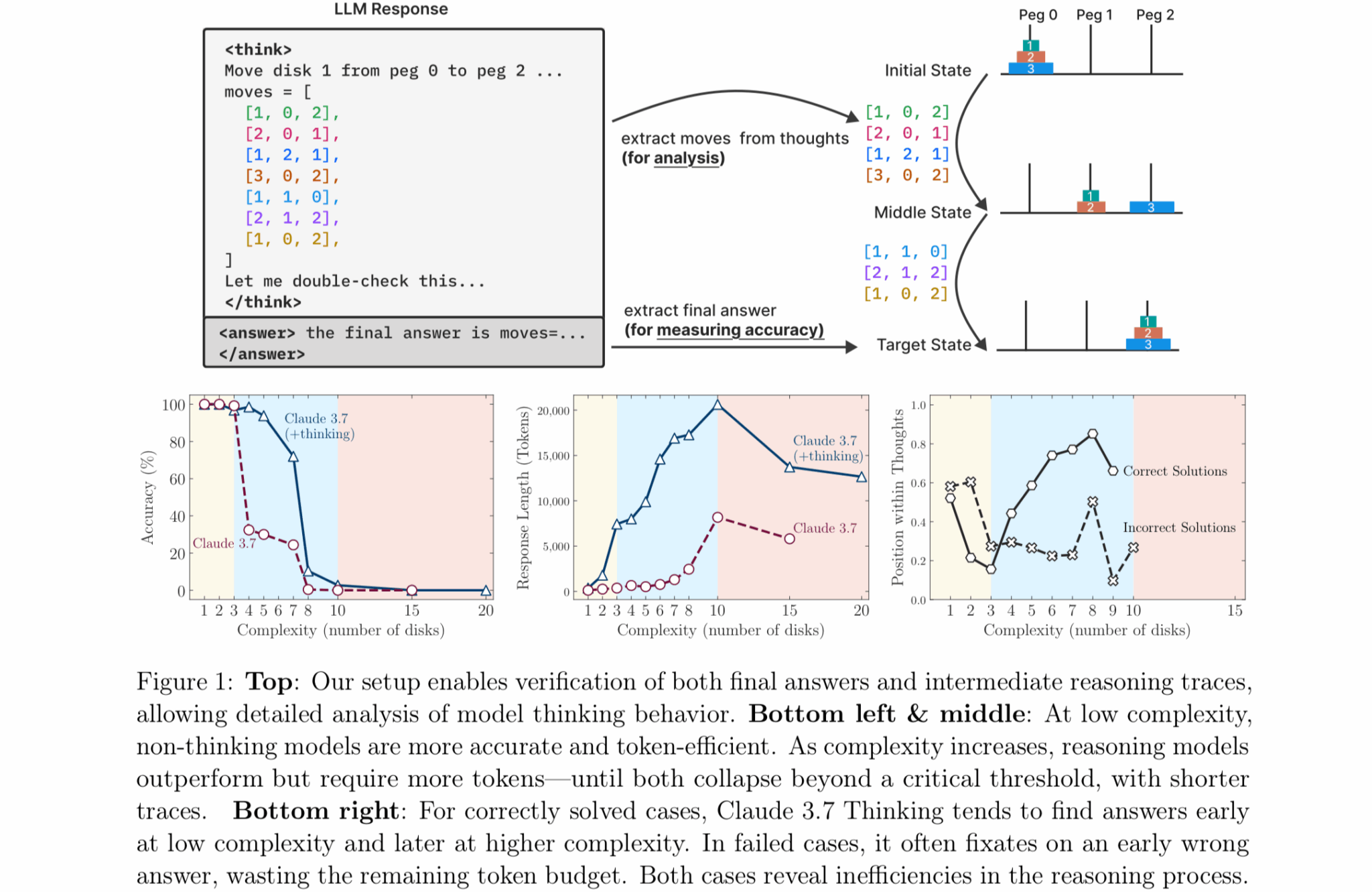
研究人员写道:“目前的评估主要侧重于已建立的数学和编码基准,强调最终答案的准确性。” 换句话说,如今的测试只关心模型是否能够正确回答可能已经存在于其训练数据中的数学或编码问题——它们并不考察模型是否真正推理出了答案,还是仅仅根据之前见过的例子进行了模式匹配。
最终,研究人员得出的结果与前述USAMO 的研究一致:这些模型在新型数学证明上的准确率大多低于 5%,只有一个模型达到了 25%,并且在近 200 次尝试中没有一个模型能达到完美证明。两个研究团队都记录了在需要扩展系统推理的问题上性能的严重下降。
已知的怀疑论者和新证据
人工智能研究员加里·马库斯(Gary Marcus)长期以来一直认为神经网络难以实现分布外的泛化,他称苹果的研究结果“对法学硕士(LLM)来说相当具有毁灭性”。尽管马库斯多年来一直提出类似的论点,并以对人工智能的怀疑态度而闻名,但这项新研究为他独特的批评观点提供了新的实证支持。
马库斯写道:“法学硕士无法可靠地解决汉诺塔问题,这真是令人尴尬。”他指出,人工智能研究员赫伯·西蒙早在1957年就解决了这个难题,而且网络上也有很多算法解决方案。马库斯指出,即使研究人员提供了解决汉诺塔问题的明确算法,模型性能也没有提高——该研究的联合负责人伊曼·米尔扎德认为,这一发现表明“他们的流程既不合逻辑,也不智能”。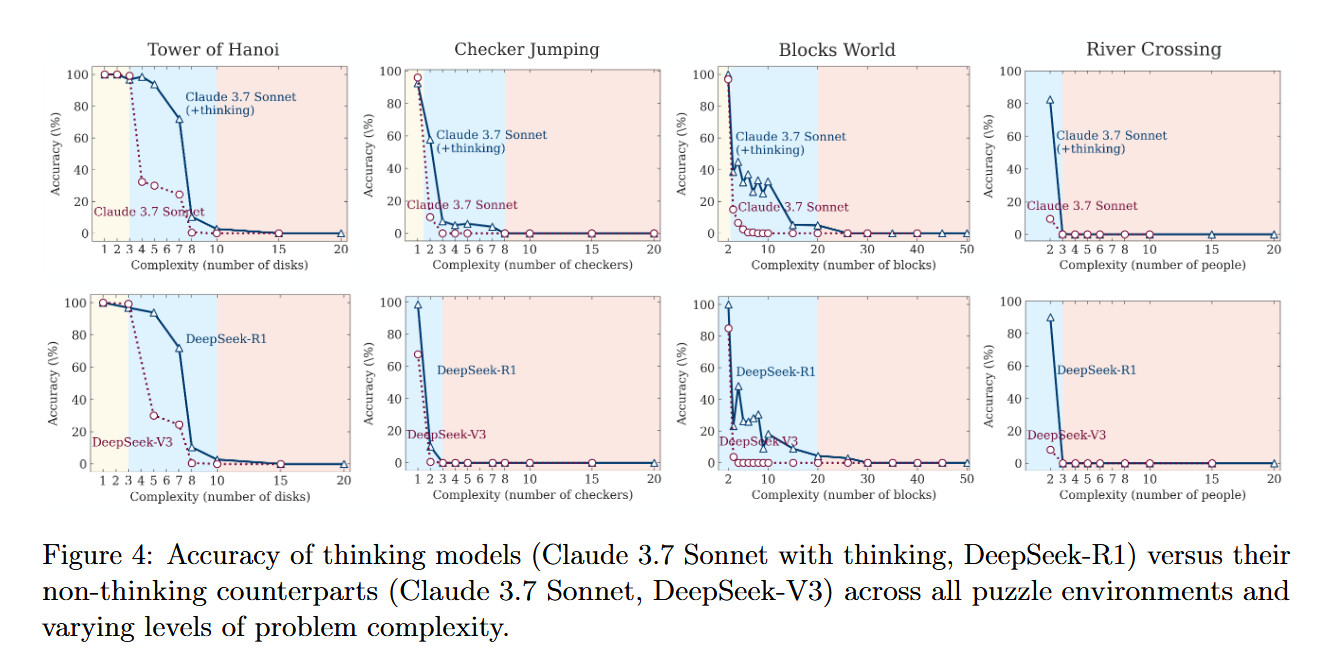
苹果团队发现,模拟推理模型的表现与“标准”模型(如 GPT-4o)根据谜题难度的不同而有所不同。在简单任务(例如只有几个圆盘的汉诺塔)中,标准模型实际上胜出,因为推理模型会“过度思考”,并产生导致错误答案的长串思维。在中等难度的任务中,SR 模型的系统性方法使其更具优势。但在真正困难的任务(例如拥有 10 个或更多圆盘的汉诺塔)中,两种模型都彻底失败,无论给予多少时间都无法完成谜题。
研究人员还发现了所谓的“反直觉扩展极限”。随着问题复杂性的增加,模拟推理模型最初会产生更多的思考标记,但随后会在超过阈值后减少推理努力,尽管拥有足够的计算资源。
该研究还揭示了模型失败过程中令人费解的不一致之处。Claude 3.7 Sonnet 在汉诺塔游戏中最多可以完成 100 步正确移动,但在过河游戏中仅移动 5 步就失败了——尽管后者所需的总移动步数更少。这表明,这些失败可能与特定任务有关,而非纯粹的计算问题。
出现相互竞争的解释
然而,并非所有研究人员都认同这些结果体现了基本推理能力的局限性。多伦多大学经济学家凯文·A·布莱恩(Kevin A. Bryan)在X上指出,观察到的局限性可能反映的是刻意的训练限制,而非内在的缺陷。
“如果你让我解决一个需要用纸笔写一个小时的问题,但给我五分钟,我可能会给你一个近似解或启发式方法。这正是强化学习(RL)所要求具备思维的基础模型所做的事情。”布莱恩写道,他建议通过强化学习(RL)对模型进行专门训练,以避免过度计算。
Bryan 认为,一些未指定的行业基准测试表明,“在几乎每个尝试过的问题领域,随着用于推理的 token 数量的增加,性能都会严格提升”,但他指出,部署的模型会刻意限制这种性能,以防止对简单查询进行“过度思考”。这种观点表明,苹果的论文衡量的可能是人为设定的约束,而非基本的推理极限。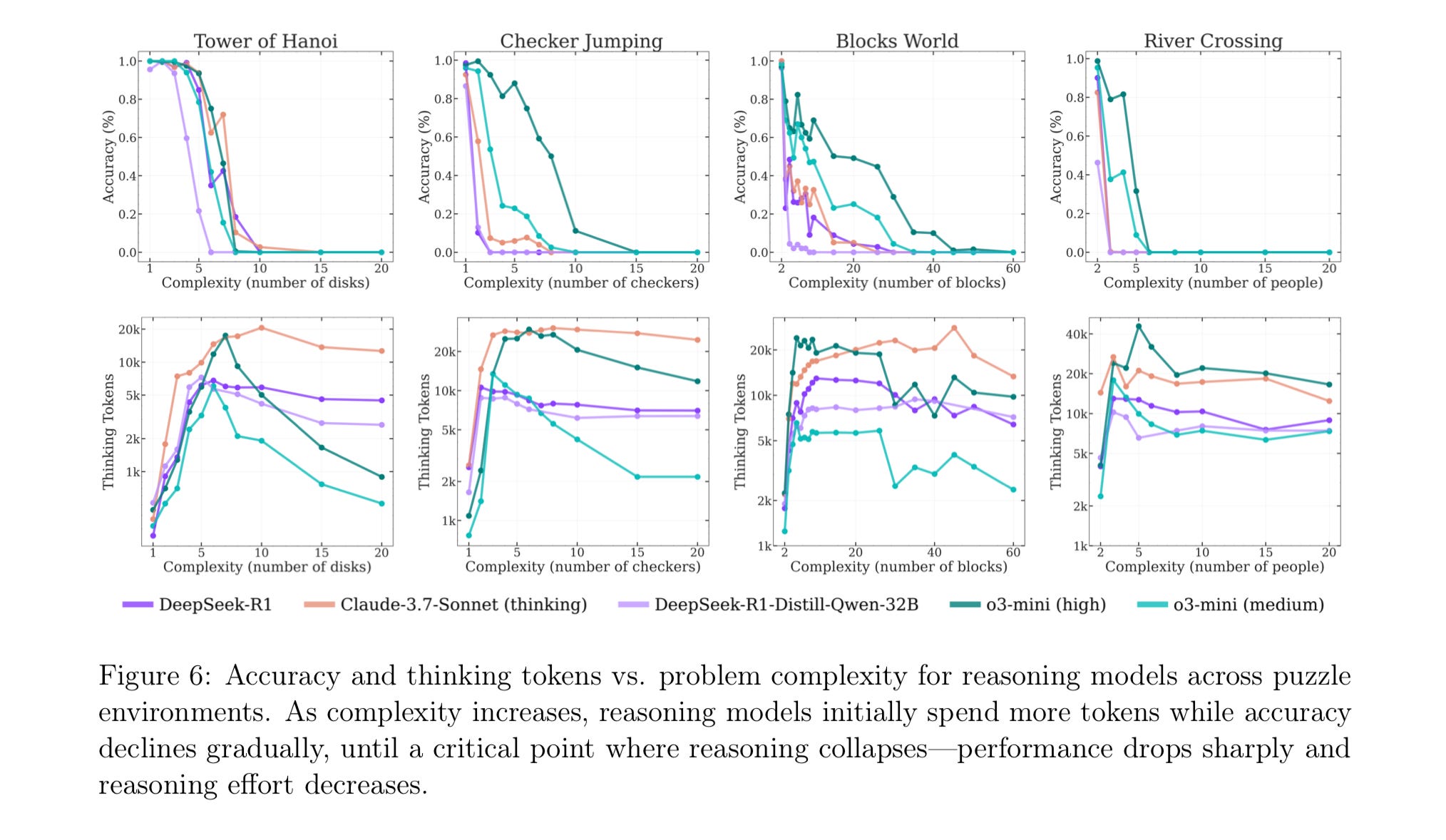
软件工程师Sean Goedecke在他的博客上对苹果的论文提出了类似的批评,他指出,当面对需要超过 1000 步移动的汉诺塔游戏时,DeepSeek-R1“立即认定‘手动生成所有这些移动是不可能的’,因为这需要追踪超过一千步移动。因此,它不停地寻找捷径,最终失败了。” Goedecke 认为,这代表模型选择不尝试这项任务,而不是无法完成它。
其他研究人员也质疑这些基于谜题的评估方法是否适用于法学硕士(LLM)。独立人工智能研究员西蒙·威利森(Simon Willison)在接受Ars Technica采访时表示,汉诺塔方法“无论是否具备推理能力,都并非应用LLM的合理方法”,并指出失败可能仅仅反映了上下文窗口(AI模型能够处理的最大文本量)中标记耗尽,而非推理能力不足。他认为这篇论文可能存在夸大其词的现象,之所以受到关注,主要是因为其“令人无法抗拒的标题”——苹果声称LLM不具备推理能力。
苹果研究人员本人也警告不要过度推断他们的研究结果,并在其局限性部分承认,“谜题环境只代表了推理任务的一小部分,可能无法捕捉现实世界或知识密集型推理问题的多样性。” 该论文还承认,推理模型在“中等复杂度”范围内有所改进,并继续在一些现实世界的应用中展现出实用性。
其影响仍有争议
这两项研究是否彻底摧毁了关于人工智能推理模型的论断的可信度?未必。
这些研究或许表明,SR 模型所使用的扩展上下文推理技巧或许并非像某些人所希望的那样,成为通往通用智能的途径。在这种情况下,通往更稳健推理能力的道路可能需要从根本上改变方法,而不是对现有方法进行改进。
正如威利森上文所述,苹果公司的研究结果迄今为止在人工智能界引起了轰动。生成式人工智能是一个备受争议的话题,围绕该模型的普遍实用性展开的意识形态之争中,许多人倾向于极端立场。许多生成式人工智能的支持者对苹果公司的研究结果提出了质疑,而批评者则认为这项研究是对法学硕士(LLM)可信度的致命一击。
苹果的成果,加上USAMO的发现,似乎强化了像马库斯这样的批评者的观点,即这些系统依赖于复杂的模式匹配,而不是其营销宣传中暗示的那种系统性推理。公平地说,生成式人工智能领域的大部分内容都比较新,甚至连其发明者都还不完全理解这些技术的工作原理和原理。与此同时,人工智能公司或许可以通过缓和一些关于推理和智能突破的宣传来建立信任。
然而,这并不意味着这些人工智能模型毫无用处。即使是复杂的模式匹配机器,只要了解它们的缺点和虚构性,也能为使用者节省不少体力。正如 Marcus 所承认的:“至少在未来十年,法学硕士(无论是否具备推理时间)仍将有其用处,尤其是在编程、头脑风暴和写作方面。”
如果公司愿意,每周工作四天可以提高效率
文章来源
https://phys.org/news/2025-06-day-week-productive-company-committed.html
如果企业真正致力于推行四天工作制,那么每周四天工作制可以提高生产力,改善工作与生活的平衡,并留住人才。这些是“创新工作”(InnovaWorking)项目的部分结论。该项目由马德里卡洛斯三世大学(卡三)协调,是一个欧洲科研项目。该项目今天在欧洲议会提交了这项研究。其研究重点关注欧盟各国工会与雇主之间协商制定的创新工作时间政策。
“我们得出的结论是,每周四天工作制以及远程办公、假期购物和弹性工作时间等灵活的工作时间安排非常有效。最重要的是,当公司或实体真正致力于此时,”InnovaWorking 项目首席研究员、卡三法学院经济与法律研究所 (IUDEC) 的安娜·贝伦·穆尼奥斯·鲁伊斯 (Ana Belén Muñoz Ruiz) 解释道。
在本研究项目中,我们对六个欧洲国家的公共和私营部门的工作与生活平衡政策进行了分析:西班牙、芬兰、法国、匈牙利、爱尔兰和荷兰。
这项科学项目已确定,工作时间安排的创新变革可以提高生产力,改善员工的工作与生活平衡,并留住人才。“每周四天工作制吸引了众多技术工人。率先实施该制度的公司将拥有更加敬业的员工,并且更不愿意跳槽到竞争对手那里。”
参与 InnovaWorking 项目的另一位研究人员、马德里康普顿斯大学劳动和社会保障法系的 Pablo Gimeno Díaz de Atauri 表示:“因此,对于先锋公司来说,在这些措施成为普遍规则之前选择这些措施是具有战略意义的。”
研究人员还分析了工人通过工会参与的重要性,但他们指出,最好避免使用“神奇公式”。“并非所有行业都能提供相同的解决方案。为了使一切顺利进行,重要的是企业要考虑到其具体的生产、组织和轮班条件,并让工人代表表达他们的需求,”卡三社会与国际私法系教授安娜·贝伦·穆尼奥斯·鲁伊斯(Ana Belén Muñoz Ruiz)说道。
科技领域以外的劳动力创新
该项目研究的案例表明,这些措施可以应用于科技行业以外的领域,例如建筑、金属或餐饮业。然而,研究发现,并非所有国家对弹性工作时间的反应都相同。
例如,在法国和西班牙等国家立法保障集体谈判且集体协议具有约束力的国家,集体谈判模式更具创新性。另一方面,在匈牙利和爱尔兰,社会对话较弱,法律僵化程度较高,谈判传统也较弱,因此集体谈判的倡议往往来自企业。
欧洲大多数国家人口老龄化持续加剧,导致劳动力年龄结构发生变化。一些公司正在采取各种举措,例如减少每周工作时间,以鼓励年长员工留在公司。
研究人员认为,在这种新形势下,有必要重新思考工作时间的安排,使其适应多元化劳动力的需求以及当前的社会和经济挑战。事实上,InnovaWorking 的研究成果可能会对欧洲关于工作场所数字化扩展的劳工政策产生影响,同时也证明了有必要规范劳动者的数字脱节权。
你的呼吸方式就像指纹一样,可以识别你
文章来源
https://www.nature.com/articles/d41586-025-01835-0
研究表明,你的吸气和呼气模式不仅是独一无二的,它还可以作为你身体和精神状态的标志。
就像指纹中的漩涡一样,一个人的呼吸模式可能是独一无二的——这不仅可以用来识别个人,还可以识别他们的一些身体和心理特征。
一组研究人员对97名健康受试者进行了24小时的呼吸测量,发现仅凭呼吸模式就能相对准确地识别参与者。此外,他们还发现这些模式与体质指数(BMI)以及抑郁和焦虑的迹象存在关联。
“某种程度上,我们是通过鼻子来读心的,”该研究的共同作者、以色列雷霍沃特魏茨曼科学研究所的神经生物学家诺姆·索贝尔(Noam Sobel)说道。“这可能是一种非常强大的诊断工具。” 该团队的研究成果今天发表在《当代生物学》1期上。
深吸一口气
呼吸与大脑息息相关。每一次吸气和呼气都相互协调,为大脑提供管理身体系统所需的氧气。索贝尔和他的团队不禁思考:如果每个人的大脑功能都不同,那么每个人的呼吸方式是否也应该独一无二?
为了验证这一点,研究人员开发了一种定制的可穿戴设备,用于记录人每个鼻孔的气流。该设备安装在颈后,鼻下装有管子,可以追踪人们日常生活中的呼吸情况,无论清醒还是睡眠。
为了描述一个人的呼吸模式,研究团队从气流数据中提取了24个参数,包括吸气和呼气的持续时间以及鼻孔间气流的不对称性。他们将参与者的清醒和睡眠时间分开,并利用这些数据训练机器学习算法。
当42名参与者在几周、几个月甚至两年后回到实验室,参加另一次24小时测量时,经过训练的算法可以根据他们的呼吸模式识别他们。参与者清醒时的数据比睡眠时的数据结果更准确,但当研究人员使用包含100个参数的完整数据集(而非仅包含24个参数的数据集)时,他们能够以96.8%的准确率识别出个体。
鉴于这一成功,索贝尔和他的同事开始思考是否可以从呼吸模式中了解更多信息。
健康呼吸
研究人员收集了参与者的BMI数据,以及评估抑郁和焦虑程度的问卷。分析发现,尽管大多数参与者的问卷得分较低,但这些信息与呼吸模式之间存在相关性。
例如,BMI 较高的人睡眠时的呼吸曲线与 BMI 较低的人不同。焦虑或抑郁问卷得分较高的人,其吸气和呼气的模式也有所不同。
“这是一项非常酷的研究,”斯德哥尔摩卡罗琳斯卡医学院的神经科学家 Artin Arshamian 说。
加州大学洛杉矶分校的精神病学家海伦·拉夫雷茨基(Helen Lavretsky)表示,研究呼吸的科学家一直在尝试将呼吸特征与健康联系起来——这类似于心电图(利用放置在人体手指、手臂或其他身体部位的电极来测量心脏活动)可以揭示异常节律。索贝尔表示,这项研究是呼吸模式领域的“一项进步”,该领域通常收集较短时间段内的呼吸数据。她还表示,这项研究为设计呼吸疗法打开了大门。
拉夫列茨基说:“我们能用的最有效的工具就是呼吸。” 例如,美国军队的一些部门会训练军人控制呼吸,以应对压力,并在高压时刻保持专注。
索贝尔和他的同事们目前正在尝试找出哪种呼吸模式与低水平的压力和焦虑相关,看看能否抵消这些感觉。索贝尔说,如果成功,他们将尝试“教人们以一种能够缓解这些症状的方式呼吸”。
介绍 V-JEPA 2 世界模型和物理推理的新基准
文章来源
https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
总结
- 元视频联合嵌入预测架构 2 (V-JEPA 2) 是一个世界模型,在物理世界中的视觉理解和预测方面实现了最佳性能。我们的模型也可用于零样本机器人规划,以便在新环境中与陌生物体进行交互。
- V-JEPA 2 代表着我们朝着实现高级机器智能 (AMI) 和构建可在物理世界中运行的有用的 AI 代理的目标迈出了下一步。
- 我们还发布了三个新的基准来评估现有模型从视频推断物理世界的能力。
今天,我们很高兴地宣布 V-JEPA 2 正式发布。这是首个基于视频训练的世界模型,它能够实现最先进的理解和预测能力,以及在新环境中进行零样本规划和机器人控制。在我们努力实现高级机器智能 (AMI) 的目标的过程中,拥有能够像人类一样学习世界、规划如何执行不熟悉的任务并高效适应周围不断变化的世界的 AI 系统至关重要。
V-JEPA 2 是一个拥有 12 亿个参数的模型,它是使用我们在 2022 年首次分享的元联合嵌入预测架构(JEPA) 构建的。我们之前的工作表明,JEPA 在图像和3D 点云等模态下表现良好。V -JEPA是我们去年发布的第一个视频训练模型,在此基础上,V-JEPA 2 改进了动作预测和世界建模功能,使机器人能够与不熟悉的物体和环境交互以完成任务。我们还分享了三个新的基准,以帮助研究界评估他们现有的模型使用视频学习和推理世界的程度。通过分享这项工作,我们旨在让研究人员和开发人员能够访问最佳模型和基准,以帮助加速研究和进步,最终带来更优秀、更强大的 AI 系统,从而改善人们的生活。
什么是世界模型?
我们都知道,如果你把一个网球抛向空中,重力会把它拉回来。如果它悬空,突然在空中旋转飞向另一个方向,或者突然变成一个苹果,那真是令人惊讶。这种身体直觉并非成年人经过多年教育就能获得的——幼儿在能够说出完整句子之前,就通过观察周围的世界培养出了这种直觉。
预测世界将如何回应我们的行为(或他人的行为)的能力是人类一直以来都在运用的,尤其是在规划行动以及如何最好地应对新情况时。不妨想想这种生理直觉在我们日常生活中是如何体现的。当我们穿过陌生拥挤的区域时,我们会一边朝着目的地前进,一边努力避免撞到沿途的人或障碍物。打冰球时,我们会滑向冰球即将飞向的方向,而不是它当前的位置。用炉子做饭时,我们会考虑锅还要烧多久,或者是否要调低火候。我们内在的世界模型不仅为我们提供了这种直觉,还充当着一个内在模拟器,让我们能够预测假设行动的结果,最终根据我们认为最能实现目标的方式,选择最佳行动。
在采取行动之前,我们会使用世界模型来设想潜在的后果。在我们致力于构建能够先思考后行动的 AI 代理的过程中,让它们学习能够实现以下功能的世界模型至关重要:
- 理解:世界模型应该能够理解对世界的观察,包括识别视频中的物体、动作和运动等。
- 预测:世界模型应该能够预测世界将如何发展,以及如果代理采取行动,世界将如何变化。
- 规划:基于预测能力,世界模型应该有助于规划实现给定目标的行动序列。
V-JEPA 2 简介
我们的长期愿景是,世界模型将使 AI 代理能够在物理世界中进行规划和推理。为了实现这一愿景,我们即将发布 V-JEPA 2,这是一个主要基于视频进行训练的世界模型——视频是丰富且易于获取的世界信息来源。通过将 V-JEPA 2 代码和模型检查点开放给商业和研究应用,我们希望围绕这项研究建立一个广泛的社区,推动我们朝着最终目标迈进,即开发能够改变 AI 与物理世界交互方式的世界模型。
V-JEPA 2 采用联合嵌入预测架构 (JEPA) 构建,包含两个主要组件:
- 编码器,接收原始视频并输出嵌入,以捕获有关观察世界状态的有用语义信息。
- 预测器,它接受视频嵌入和关于要预测的内容的附加上下文,并输出预测的嵌入。
我们使用基于视频的自监督学习来训练 V-JEPA 2,这使得我们无需额外的人工注释即可在视频上进行训练。V-JEPA 2 训练包含两个阶段:无动作预训练,以及后续的动作条件训练。
在第一阶段——预训练阶段,我们使用了来自不同来源的超过 100 万小时的视频和 100 万张图像。这些丰富的视觉数据有助于模型深入了解世界的运作方式,包括人与物体的互动方式、物体在物理世界中的移动方式以及物体与其他物体的互动方式。我们发现,在预训练阶段之后,模型已经展现出与理解和预测相关的关键能力。例如,通过在冻结编码器特征的基础上训练轻量级的注意力读出模型,V-JEPA 2 在 Something-Something v2 动作识别任务中取得了卓越的表现,该任务依赖于运动理解。同样,通过在冻结编码器和预测器特征的基础上训练注意力读出模型,V-JEPA 2 在 Epic-Kitchens-100 动作预测任务中创造了新的最高纪录,该任务可以根据以自我为中心的视频预测未来 1 秒将执行的动作(由名词和动词组成)。最后,将 V-JEPA 2 与语言模型相结合,可以在视频问答基准(例如感知测试和 TempCompass)上实现最先进的性能。
在无动作预训练阶段之后,模型可以预测世界未来如何演变——然而,这些预测并未直接考虑代理将采取的具体动作。在训练的第二阶段,我们专注于利用机器人数据(包括视觉观察(视频)和机器人正在执行的控制动作)来提升模型的规划能力。我们通过向预测器提供动作信息,将这些数据整合到 JEPA 训练流程中。在使用这些额外数据进行训练后,预测器学会在进行预测时考虑具体动作,然后即可用于控制。第二阶段我们不需要大量的机器人数据——在我们的技术报告中,我们展示了仅使用 62 小时的机器人数据进行训练就能构建出一个可用于规划和控制的模型。
我们演示了如何在新环境中使用 V-JEPA 2 进行零样本机器人规划,并涉及训练期间未见过的物体。与其他机器人基础模型(通常需要一些来自部署模型的特定机器人实例和环境的训练数据)不同,我们在开源DROID 数据集上训练该模型,然后将其直接部署到我们实验室的机器人上。我们展示了 V-JEPA 2 预测器可用于执行一些基础任务,例如伸手够到、拾取物体并将其放置在新位置。
对于短期任务,例如拾取或放置物体,我们以图像的形式指定目标。我们使用 V-JEPA 2 编码器获取当前状态和目标状态的嵌入。机器人从观察到的当前状态出发,利用预测器进行规划,设想采取一系列候选动作的后果,并根据候选动作与期望目标的接近程度对其进行评级。在每个时间步,机器人都会重新规划并通过模型预测控制执行排名最高的下一个动作,以实现该目标。对于长期任务,例如拾取物体并将其放置在正确位置,我们指定一系列视觉子目标,机器人会尝试按顺序实现这些目标,类似于人类观察到的视觉模仿学习。凭借这些视觉子目标,V-JEPA 2 在新环境和未知环境中拾取和放置新物体的成功率达到 65% 至 80%。
物理理解的基准测试
随着我们在世界模型领域不断取得进展,我们很高兴与开源社区分享我们的工作成果并支持其发展。我们将发布三个新的基准测试,以评估现有模型从视频理解和推理物理世界的能力。虽然人类在这三个基准测试中都表现良好(准确率达到 85% 到 95%),但人类的表现与包括 V-JEPA 2 在内的顶级模型相比仍存在显著差距,这为模型的改进指明了重要的方向。
IntPhys 2专门用于衡量模型区分物理上合理和不合理场景的能力,它在早期的IntPhys 基准的基础上进行构建和扩展。我们设计 IntPhys 2 的方式类似于发展认知科学家通过违反预期范式来评估年轻人何时获得直觉物理学的方式。我们使用一个游戏引擎来实现这一点,该引擎会生成成对的视频,其中两个视频在某个点之前相同,然后两个视频中的一个视频中发生了违反物理的事件。然后,模型必须识别哪个视频发生了违反物理的事件。虽然人类在各种场景和条件下都能在这项任务上达到近乎完美的准确率,但我们发现当前的视频模型处于或接近偶然性。
最小视频对 (MVPBench) 通过多项选择题来衡量视频语言模型的物理理解能力。与文献中的其他视频问答基准测试不同,MVPBench 旨在缓解视频语言模型中常见的捷径解决方案,例如依赖肤浅的视觉或文本线索和偏见。MVPBench 中的每个示例都包含一个最小变化对:视觉上相似的视频,以及相同的问题,但答案相反。为了获得一个示例的评分,模型也必须正确完成其最小变化对。
CausalVQA衡量视频语言模型回答与物理因果关系相关问题的能力。该基准测试旨在关注对物理世界视频中因果关系的理解,包括反事实问题(如果……会发生什么)、预期问题(接下来可能会发生什么)以及规划问题(为了实现目标,下一步应该采取什么行动)。我们发现,虽然大型多模态模型越来越能够回答视频中“发生了什么”的问题,但它们仍然难以回答“可能发生什么”和“接下来可能会发生什么”的问题,这表明,在预测物理世界在给定动作和事件空间的情况下可能如何演变方面,人类的表现与人类存在巨大差距。
迈向高级机器智能的下一步
随着我们继续推进世界模型的研究,我们计划在多个领域进一步探索。目前,V-JEPA 2 可以在单一时间尺度上学习并进行预测。然而,许多任务需要跨多个时间尺度进行规划。想象一下,将一个高级任务分解成更小的步骤,例如装载洗碗机或烘烤蛋糕。我们希望专注于训练能够跨多个时间和空间尺度进行学习、推理和规划的分层 JEPA 模型。另一个重要方向是多模态 JEPA 模型,这些模型可以使用多种感官进行预测,包括视觉、听觉和触觉。一如既往,我们期待在未来分享更多成果,并继续与研究界进行重要的讨论。
《思考的错觉的错觉》
几天前,苹果一篇《思考的错觉》论文吸睛无数又争议不断,其中研究了当今「推理模型」究竟真正能否「推理」的问题,而这里的结论是否定的。
论文中写到:「我们的研究表明,最先进的 LRM(例如 o3-mini、DeepSeek-R1、Claude-3.7-Sonnet-Thinking)仍然未能发展出可泛化的解决问题能力 —— 在不同环境中,当达到一定复杂度时,准确度最终会崩溃至零。」
不过,这篇论文的研究方法也受到了不少质疑,而现在,我们迎来了对这项研究更强有力的质疑:《思考的错觉的错觉》。是的,你没有看错,这就是这篇来自 Anthropic 和 Open Philanthropy 的评论性论文的标题!其中指出了那篇苹果论文的 3 个关键缺陷:
- 汉诺塔实验在报告的失败点系统性地超出了模型输出 token 的限制,而模型在其输出中明确承认了这些限制;
- 苹果论文作者的自动评估框架未能区分推理失败和实际约束,导致对模型能力分类错误;
- 最令人担忧的是,由于船容量不足,当 N ≥ 6 时,他们的「过河(River Crossing)」基准测试包含在数学上不可能出现的实例,但模型却因未能解答这些本就无法解决的问题而被评为失败
1.研究背景与核心争议
Shojaee等人的研究声称,当面对复杂度超过一定阈值的规划问题(如河渡问题、汉诺塔问题)时,大型推理模型的表现会显著下降,甚至完全失效。这被解释为模型在复杂推理上存在根本性的局限。
本文作者对此提出了质疑,认为这些“失败”并非源于模型推理能力的不足,而是由以下三方面原因导致:
- 输出长度限制 :模型在处理某些问题时因生成内容超出token上限而被迫截断;
- 评估框架误判 :自动化评估系统未能区分模型是否理解问题但选择不完整输出;
- 测试问题不可解 :部分测试实例本身无解,模型未能得分是因为正确识别了这一点。
2.对Shojaee等人的主要反驳点
2.1 模型能够识别并主动应对输出限制
作者引用了一个Twitter上的复现案例,展示了模型在解决汉诺塔问题时明确表示“为了不过于冗长,我在这里停止”。这表明模型不仅理解解决方案的模式,还具备自我调节输出长度的能力。将这种行为归类为“推理崩溃”是对其能力的误解。
此外,作者通过数学建模分析了token数量与问题规模之间的关系,指出在当前上下文窗口限制下,模型无法完整输出超大规模问题的解答是预料之中的技术限制,而非推理失败。
2.2 自动化评估系统的误分类问题
作者指出,若以字符级或token级精度来评判模型表现,即使每个token的准确率为99.9%,在生成数万个token时整体成功概率也会极低。这种统计学上的“必然失败”不应被错误解读为模型不具备解决问题的能力。
更进一步地,作者强调评估系统应当具备区分“不能解”与“不愿穷举”的能力,否则容易得出误导性结论。
2.3 测试集包含不可解问题
在River Crossing问题中,作者指出当N ≥ 6且船容量b = 3时,问题本身在数学上已被证明无解。然而,Shojaee等人仍将模型未能给出答案视为“失败”,等同于惩罚一个SAT求解器在面对不可满足公式时返回“unsatisfiable”。
这是一个严重的评估失误,反映出程序化自动评分机制在缺乏人类判断或逻辑验证的情况下可能产生反效果。
3. 实验改进与新发现
作者通过改变问题的输入/输出形式,要求模型输出一个Lua函数来表示解决方案,而非逐条列出所有移动步骤。结果显示,在Tower of Hanoi N=15的问题上,多个主流模型(包括Claude Opus、Gemini 2.5等)均能高效生成正确的递归算法实现,仅需不到5,000个token。
这说明:
模型确实具备解决高复杂度问题的推理能力;
问题的关键在于如何引导模型以合适的表达方式呈现其知识;
token预算限制应被视为工程瓶颈,而非认知瓶颈。
4. 对问题复杂度指标的再思考
作者指出,Shojaee等人使用“最小步数”作为衡量问题复杂度的标准并不恰当。他们列举了不同规划问题的特性:
| 问题类型 | 解决方案长度 | 分支因子 | 是否需要搜索 |
|---|---|---|---|
| Tower of Hanoi | 2^N − 1 | 1 | 否 |
| River Crossing | ~4N | >4 | 是(NP-hard) |
| Blocks World | ~2N | O(N²) | 是(PSPACE) |
这说明,尽管汉诺塔问题需要指数级的操作次数,但每一步的选择是确定的;而河渡问题虽然操作次数少,却涉及复杂的约束满足和搜索过程。因此,仅凭操作次数难以反映实际难度。
5. 结论与未来建议
本文有力地反驳了Shojaee等人关于模型存在“根本推理限制”的主张,指出其实验结果更多反映了技术限制和评估设计的缺陷。作者提出未来研究应注重以下几个方向:
区分推理能力和输出限制 :评估系统应能识别模型是否具备解决问题的知识,即便未完整执行。
验证测试问题的可解性 :避免将模型在不可解问题上的正确响应误判为失败。
采用合理的复杂度指标 :应考虑问题内在的计算难度,而非仅看操作数量。
多样化解决方案表示方式 :鼓励模型以抽象、函数式等方式表达解决方案,减少对穷举路径的依赖。
6. 总体评价
这是一篇具有重要理论价值和实践意义的评论文章。它提醒我们在评估AI推理能力时,必须更加谨慎地设计实验和评估标准。模型的“失败”未必意味着其没有能力,而可能是我们尚未找到合适的方式来激发和观察其潜能。
正如作者所言:“问题不是模型能否推理,而是我们的评估能否区分推理与打字。”
- Title: 一周科技资讯第一期
- Author: 姜智浩
- Created at : 2025-06-15 11:45:14
- Updated at : 2025-06-14 21:40:15
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/06/15/20250615一周科技资讯第一期/
- License: This work is licensed under CC BY-NC-SA 4.0.