Apriori算法原理

Apriori
Apriori 算法是关联规则学习中最经典的算法之一,用于在大规模交易记录中发现频繁项集和关联规则。
核心思想
这是 Apriori 原理(反单调性)
“如果一个项集是频繁的,它的所有子集也一定是频繁的”
→ 反过来说:如果某个项集不频繁,那它的所有超集一定也不频繁。
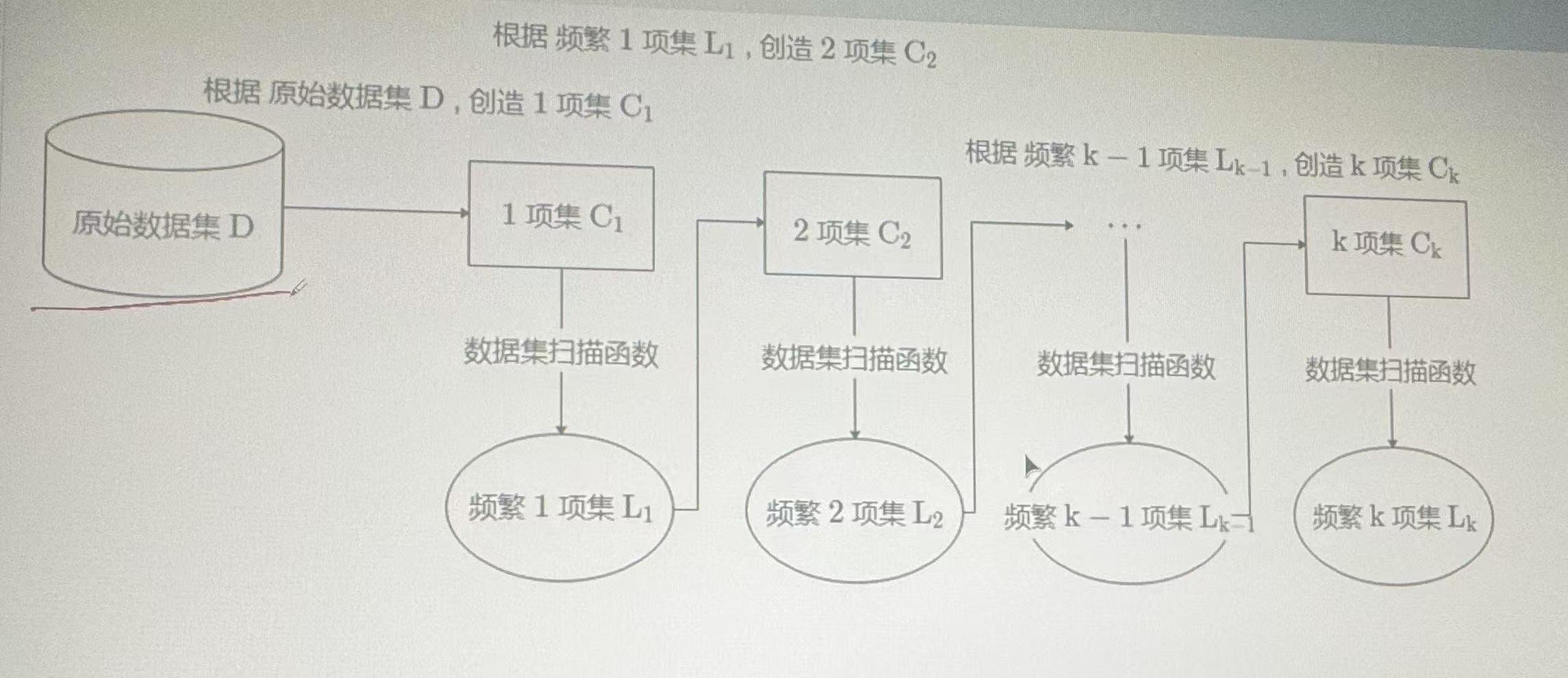
Apriori流程
- 初始化:找出所有频繁的1项集。
- 扫描数据,统计每个单品的支持度。
- 只保留支持度 ≥ 最小阈值(min_sup)的项。
- 迭代生成 k 项集。
- 用频繁的 (k−1) 项集 生成候选 k 项集(两两组合)。
- 继续扫描数据集,统计每个候选项集的支持度。
- 只保留支持度 ≥ min_sup 的项集。
- 重复直到无法产生更大的频繁项集。
找频繁项集后 → 生成关联规则
对每个频繁项集 L:
- 枚举其所有非空子集 A,令 B = L − A
- 构造规则:A → B
- 计算置信度 confidence = support(L) / support(A)
- 若 confidence ≥ min_conf,则保留规则

举例:
假设发现以下频繁项集:
info
{牛奶, 面包},support = 0.6
{牛奶},support = 0.8
则可以生成规则:
info
牛奶 → 面包,confidence = 0.6 / 0.8 = 0.75
如果最小置信度设为 0.7,这条规则会被保留。
典型应用
超市推荐系统
电商商品搭配
网页点击路径分析
疾病共现分析
关键概念
项(Item)
数据中的一个元素,比如:商品“牛奶”、“面包”。
事务(Transaction)
一组一起出现的项。例如:某一次购物记录是[牛奶, 面包, 鸡蛋]。
项集(Itemset)
一组项的组合。例如:{牛奶, 面包} 是一个 2-项集。
指标
支持度(Support)
一个规则在数据集中出现的频率 表示某项集在整个数据中出现的频率。\text{Support}(X) = \frac{\text{包含 X 的事务数}}{\text{总事务数}}
置信度(Confidence)
规则的可靠性程度 表示在买了 X 的前提下买 Y 的概率。\text{Confidence}(X \rightarrow Y) = \frac{\text{Support}(X \cup Y)}{\text{Support}(X)}
提升度(Lift)
衡量 X 和 Y 是否真正有关联\text{Lift}(X \rightarrow Y) = \frac{\text{Confidence}(X \rightarrow Y)}{\text{Support}(Y)}
- 若 Lift > 1:X 和 Y 正相关
- 若 Lift = 1:X 和 Y 独立
- 若 Lift < 1:X 和 Y 负相关
Apriori算法实现–mlxtend
必要的库
info
pip install mlxtend pandas
1 | import pandas as pd |
1 | # 模拟购物篮数据 |
1 | # 1. 编码转换:把列表数据转为布尔型 DataFrame |
1 | # 2. 使用 Apriori 找出频繁项集(设置最小支持度为0.5) |
1 | # 3. 生成关联规则(设置最小置信度为0.6) |
1 | # 4. 输出结果 |
【频繁项集】
support itemsets
0 0.8 (牛奶)
1 0.8 (面包)
2 0.8 (鸡蛋)
3 0.6 (牛奶, 面包)
4 0.6 (鸡蛋, 牛奶)
5 0.6 (鸡蛋, 面包)【关联规则】
antecedents consequents support confidence lift
0 (牛奶) (面包) 0.6 0.75 0.9375
1 (面包) (牛奶) 0.6 0.75 0.9375
2 (鸡蛋) (牛奶) 0.6 0.75 0.9375
3 (牛奶) (鸡蛋) 0.6 0.75 0.9375
4 (鸡蛋) (面包) 0.6 0.75 0.9375
5 (面包) (鸡蛋) 0.6 0.75 0.9375
- Title: Apriori算法原理
- Author: 姜智浩
- Created at : 2025-06-13 11:45:14
- Updated at : 2025-06-13 20:03:17
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/06/13/20250613Apriori算法原理/
- License: This work is licensed under CC BY-NC-SA 4.0.