Extrovert vs. Introvert Behavior Data

数据来源
https://www.kaggle.com/datasets/rakeshkapilavai/extrovert-vs-introvert-behavior-data/data
数据描述
关于数据集
概述
深入研究“外向与内向性格特征数据集”,这是一个丰富的行为和社交数据集合,旨在探索人类性格谱系。该数据集涵盖了外向和内向的关键指标,是心理学家、数据科学家以及研究社会行为、性格预测或数据预处理技术的研究人员的宝贵资源。
语境
外向和内向等性格特征塑造了个体与社交环境的互动方式。该数据集提供了对个人行为的洞察,例如独处时间、社交活动参与度以及社交媒体参与度,从而为心理学、社会学、市场营销和机器学习等领域的应用提供支持。无论您是预测性格类型还是分析社交模式,该数据集都能助您发现引人入胜的洞见。
数据集详细信息
大小:数据集包含 2,900 行和 8 列。
过程
导入库
1 | import pandas as pd |
查看数据
1 | df = pd.read_csv('personality_dataset.csv') |
1 | df.columns |
Index([‘Time_spent_Alone’, ‘Stage_fear’, ‘Social_event_attendance’,
‘Going_outside’, ‘Drained_after_socializing’, ‘Friends_circle_size’,
‘Post_frequency’, ‘Personality’],
dtype=’object’)
- Time_spent_Alone: 独处时间 – 一个人每天通常独自度过的小时数
- Stage_fear: 舞台恐惧 – 是否经历过舞台恐惧症
- Social_event_attendance: 社交活动出席率 – 参加社交活动的频率(0-10 级)
- Going_outside: 外出 – 个人外出的频率(0-10 级)
- Drained_after_socializing:社交后精疲力竭 – 社交后是否感觉精疲力尽
- Friends_circle_size:好友圈大小 – 亲密朋友数量
- Post_frequency:帖子频率 – 在社交媒体上发帖的频率
- Personality: 性格 – 目标变量:内向或外向
1 | df.info() |
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 2900 entries, 0 to 2899
Data columns (total 8 columns):Column Non-Null Count Dtype
0 Time_spent_Alone 2837 non-null float64
1 Stage_fear 2827 non-null object
2 Social_event_attendance 2838 non-null float64
3 Going_outside 2834 non-null float64
4 Drained_after_socializing 2848 non-null object
5 Friends_circle_size 2823 non-null float64
6 Post_frequency 2835 non-null float64
7 Personality 2900 non-null object
dtypes: float64(5), object(3)
memory usage: 181.4+ KB
1 | df.head() |

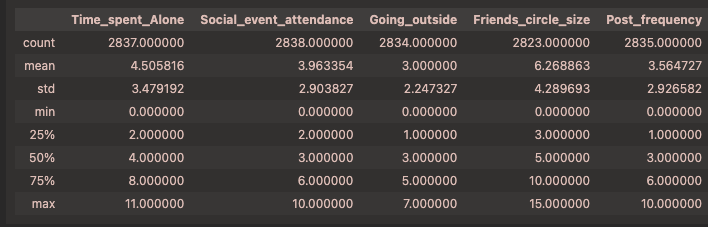
1 | df.describe() |
缺失值处理
1 | df.isnull().sum() |
Time_spent_Alone 63
Stage_fear 73
Social_event_attendance 62
Going_outside 66
Drained_after_socializing 52
Friends_circle_size 77
Post_frequency 65
Personality 0
dtype: int64
数值型用均值填充
类别型用众数填充
1 | for col in df.columns: |
特征编码
1 | df['Stage_fear'] = df['Stage_fear'].map({'Yes': 1, 'No': 0}) |
异常值检测
1 | for col in df.columns: |
列Time_spent_Alone的异常值:
列Stage_fear的异常值:
列Social_event_attendance的异常值:
列Going_outside的异常值:
列Drained_after_socializing的异常值:
列Friends_circle_size的异常值:
列Post_frequency的异常值:
列Personality的异常值:
说明没有异常值 我们通过箱线图也没发现异常值
EDA
工具代码
1 | def pairwise_plot( |
可视化
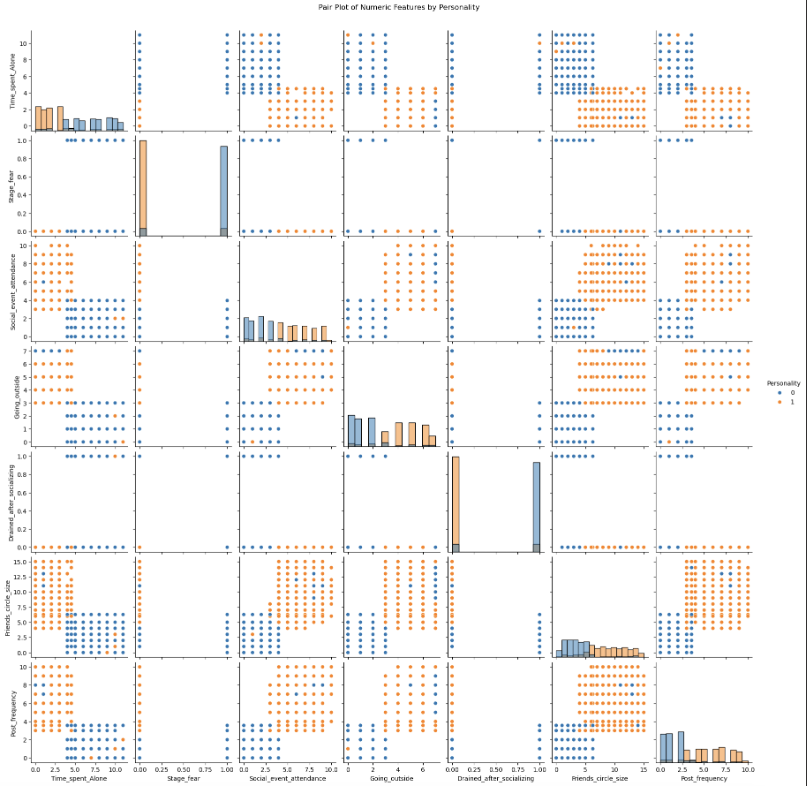
1 | sns.pairplot(df, diag_kind='hist', hue='Personality') |
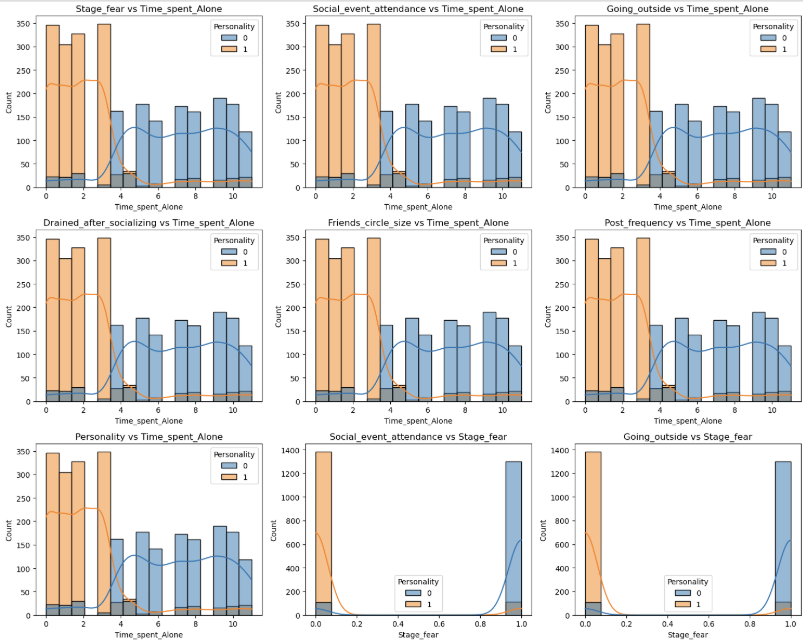
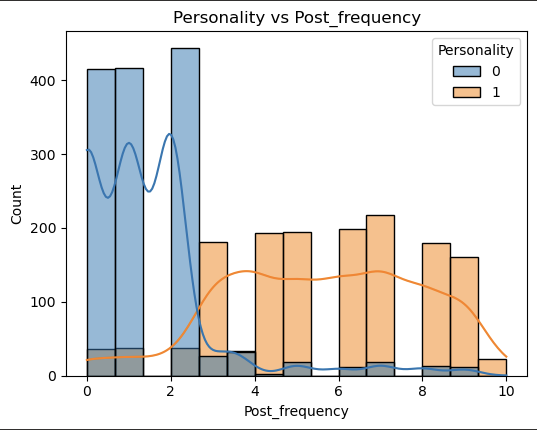
1 | pairwise_plot(df, df.columns, plot_type='hist', hue='Personality', max_per_figure=9) |
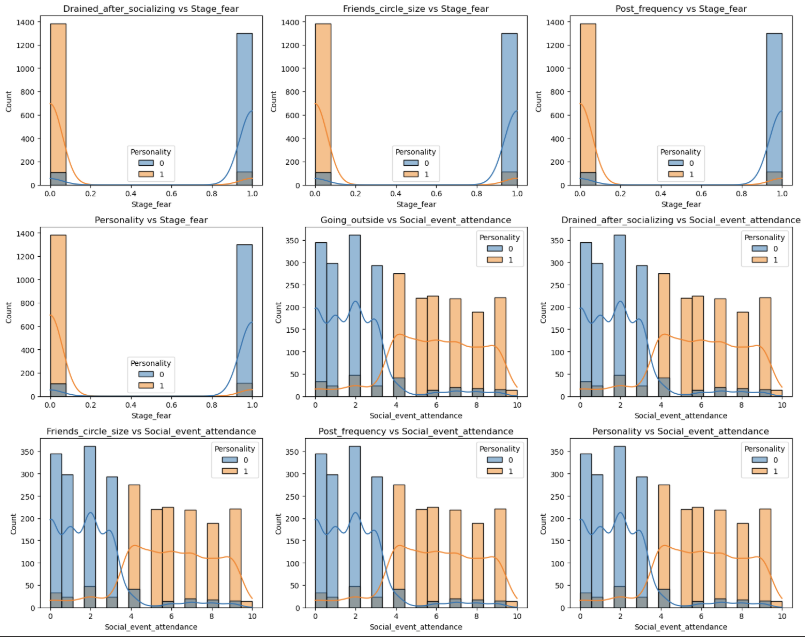
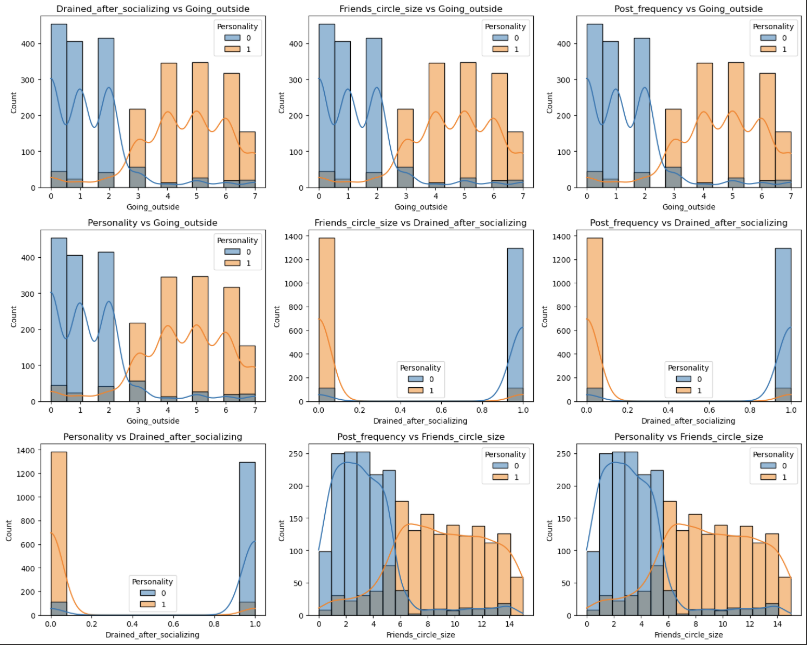
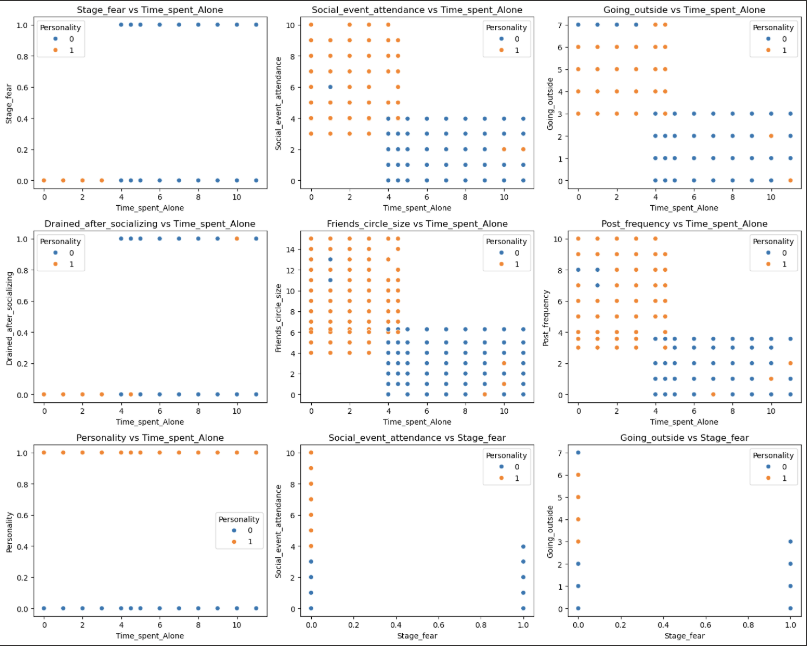
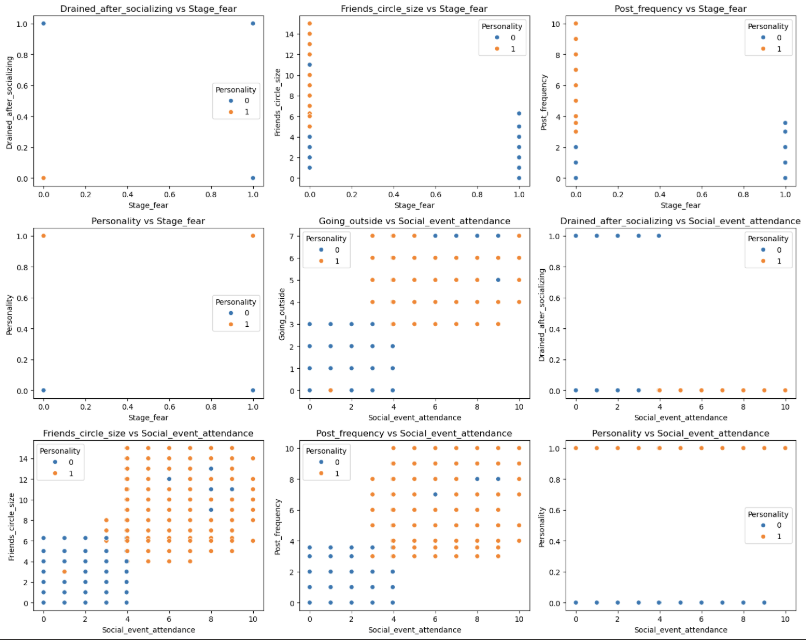
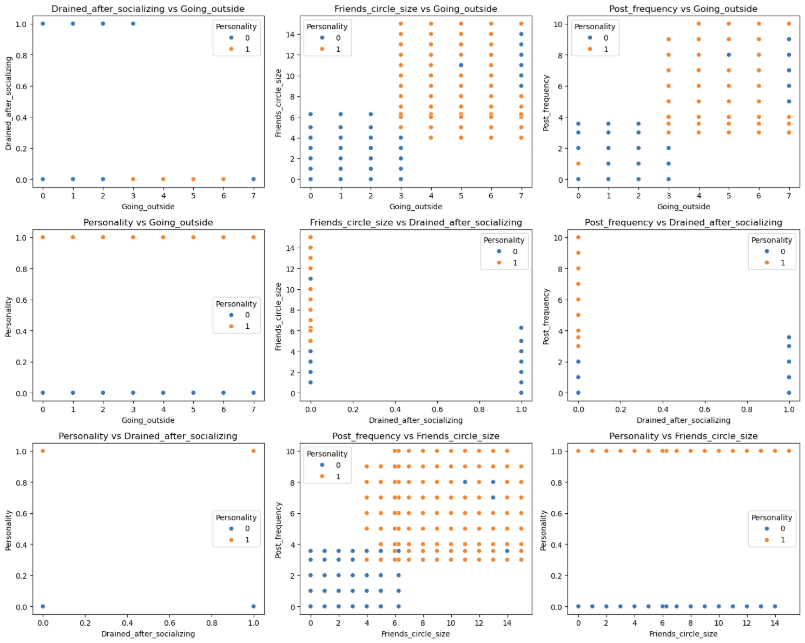
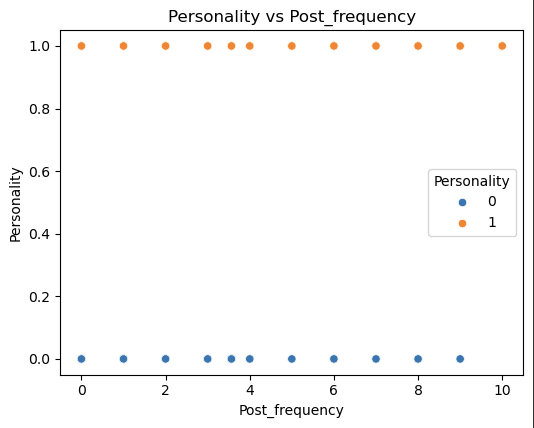
1 | pairwise_plot(df, df.columns, plot_type='scatter', hue='Personality', max_per_figure=9) |
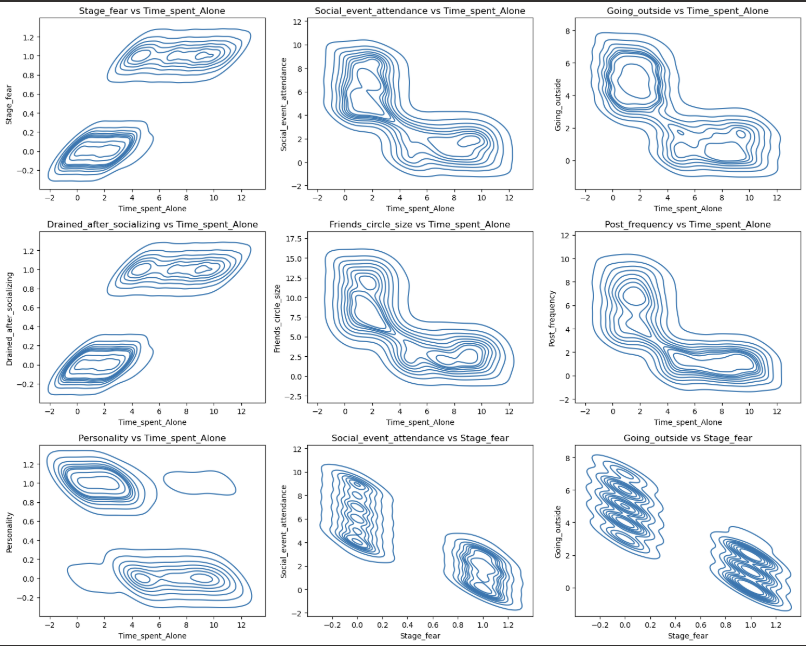
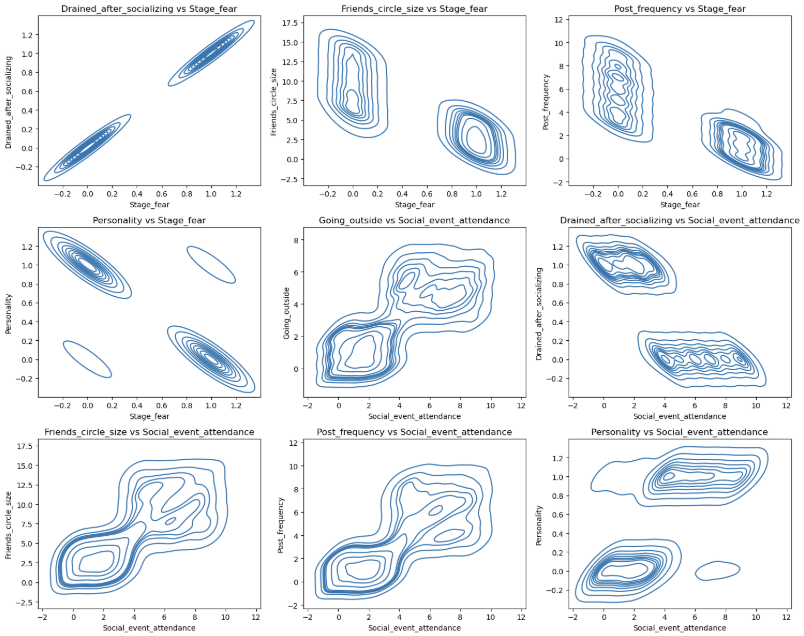
1 | pairwise_plot(df, df.columns, plot_type='kde', max_per_figure=9) |
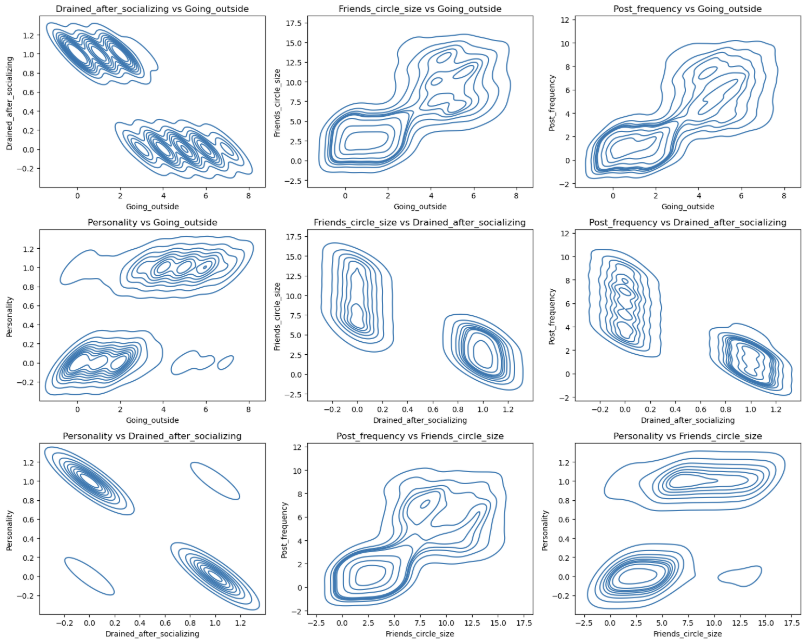
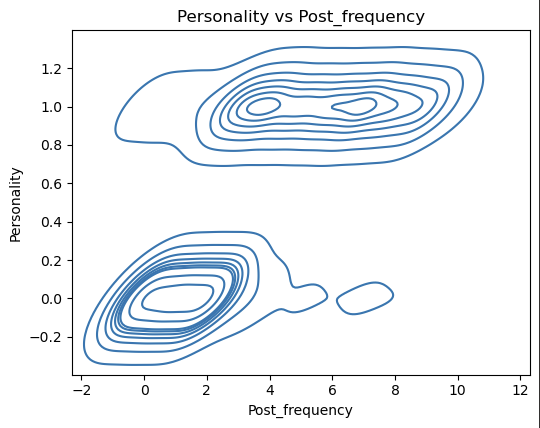
1 | df.corr() |
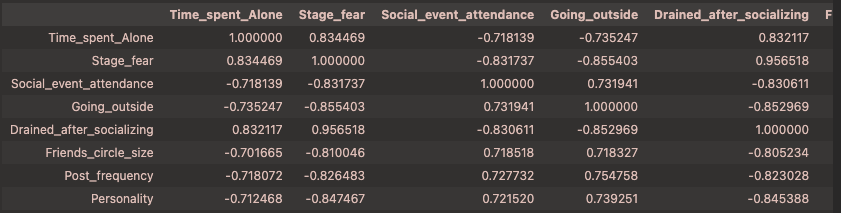
我们发现这些变量与目标变量的相关性的绝对值均大于0.6 说明这些特征都很重要 从上面的可视化结果来看也是如此
数据划分
1 | X = df.drop('Personality', axis=1) |
标准化+模型训练
SVM
1 | from sklearn.pipeline import Pipeline |
1 | pipeline = Pipeline([ |
1 | y_pred = pipeline.predict(X_test) |
0.9293103448275862
precision recall f1-score support0 0.92 0.94 0.93 278 1 0.94 0.92 0.93 302 accuracy 0.93 580macro avg 0.93 0.93 0.93 580
weighted avg 0.93 0.93 0.93 580
[[261 17]
[ 24 278]]
1 | from sklearn.pipeline import Pipeline |
{‘svm__C’: 0.1, ‘svm__gamma’: ‘scale’, ‘svm__kernel’: ‘rbf’}
0.9357758620689655
precision recall f1-score support0 0.92 0.94 0.93 278 1 0.94 0.92 0.93 302 accuracy 0.93 580macro avg 0.93 0.93 0.93 580
weighted avg 0.93 0.93 0.93 580
[[261 17]
[ 24 278]]
XGboost
1 | from xgboost import XGBClassifier |
XGBoost Accuracy: 0.9172413793103448
precision recall f1-score support0 0.90 0.93 0.91 278 1 0.93 0.91 0.92 302 accuracy 0.92 580macro avg 0.92 0.92 0.92 580
weighted avg 0.92 0.92 0.92 580[[258 20]
[ 28 274]]
1 | pipeline = Pipeline([ |
Accuracy: 0.9293103448275862
precision recall f1-score support0 0.92 0.94 0.93 278 1 0.94 0.92 0.93 302 accuracy 0.93 580macro avg 0.93 0.93 0.93 580
weighted avg 0.93 0.93 0.93 580[[261 17]
[ 24 278]]
随机森林
1 | from sklearn.ensemble import RandomForestClassifier |
Random Forest Accuracy: 0.9224137931034483
precision recall f1-score support0 0.91 0.93 0.92 278 1 0.94 0.91 0.92 302 accuracy 0.92 580macro avg 0.92 0.92 0.92 580
weighted avg 0.92 0.92 0.92 580[[259 19]
[ 26 276]]
1 | pipeline = Pipeline([ |
Best Random Forest Accuracy: 0.9293103448275862
precision recall f1-score support0 0.92 0.94 0.93 278 1 0.94 0.92 0.93 302 accuracy 0.93 580macro avg 0.93 0.93 0.93 580
weighted avg 0.93 0.93 0.93 580[[261 17]
[ 24 278]]
结论
我们通过可视化图表可以看到 数据的分布呈现集中分布 说明特征与特征之间的关系较为紧密 说明内向与外向的人他们具有明显的区分度
SVM的准确率为:0.9357758620689655
预测的召回率为:0.93
其中预测内向的召回率为:0.94
其中预测外向的召回率为:0.92
说明其对内向的确诊率较高
- Title: Extrovert vs. Introvert Behavior Data
- Author: 姜智浩
- Created at : 2025-06-04 11:45:14
- Updated at : 2025-06-04 21:53:57
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/06/04/20250604Extrovert vs. Introvert Behavior Data/
- License: This work is licensed under CC BY-NC-SA 4.0.