Spaceship Titanic

数据来源
https://www.kaggle.com/competitions/spaceship-titanic/data
数据描述
欢迎来到2912年,你需要运用数据科学技能来解开一个宇宙之谜。我们收到了来自四光年外的传输信息,情况看起来不太妙。
泰坦尼克号宇宙飞船是一艘星际客轮,于一个月前发射升空。这艘载有近1.3万名乘客的飞船开始了它的首航,将来自我们太阳系的移民运送到三颗围绕邻近恒星运行的、新发现的宜居系外行星。
在绕过半人马座阿尔法星,前往其首个目的地——炙热的巨蟹座E星——的途中,粗心大意的泰坦尼克号宇宙飞船与隐藏在尘埃云中的时空异常相撞。不幸的是,它遭遇了与一千年前同名飞船相似的命运。虽然飞船完好无损,但几乎一半的乘客被传送到了另一个维度!
为了帮助救援队找回失踪的乘客,您需要使用从宇宙飞船受损的计算机系统中恢复的记录来预测哪些乘客是被异常现象运送的。
帮助拯救他们并改变历史!
过程
导入库
1 | import pandas as pd |
1 | df = pd.read_csv('train.csv') |
1 | df.head() |
1 | df.info() |
现在我们分析一下各个字段的含义:
- PassengerId:乘客的ID
- HomePlanet:乘客出发的星球 通常是他们永久居住的星球
- CryoSleep:指示乘客是否选择在航行期间处于休眠状态 处于休眠状态的乘客将被限制在自己的船舱内
- Cabin:乘客所住舱位号。格式为deck/num/side 其中side可以是P左舷 也可以是S右舷
- Destination:乘客即将登陆的星球
- Age:乘客的年龄
- VIP:乘客是否已支付航行期间的特殊VIP服务费用
- RoomService: 乘客在泰坦尼克号宇宙飞船的众多豪华设施中支付的金额
- FoodCourt: 乘客在泰坦尼克号宇宙飞船的众多豪华设施中支付的金额
- ShoppingMall: 乘客在泰坦尼克号宇宙飞船的众多豪华设施中支付的金额
- Spa: 乘客在泰坦尼克号宇宙飞船的众多豪华设施中支付的金额
- VRDeck: 乘客在泰坦尼克号宇宙飞船的众多豪华设施中支付的金额
- Name:乘客的名字和姓氏
- Transported:乘客是否被传送到了另一个维度。这是目标,也就是你要预测的列
缺失值处理
我们首先处理缺失值
1 | df.isnull().sum() |
针对数值型特征 使用均值填充
针对类别型特征 使用众数填充
1 | missing_features = ['Age', 'RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck'] |
我们删除一些不必要的列 例如id和名称
1 | df.drop(columns=['PassengerId', 'Name'], inplace=True) |
其中 我发现Cabin这个特征包含了许多信息 将其分为三列
1 | df[['Cabin_deck', 'Cabin_num', 'Cabin_side']] = df['Cabin'].str.split('/', expand=True) |
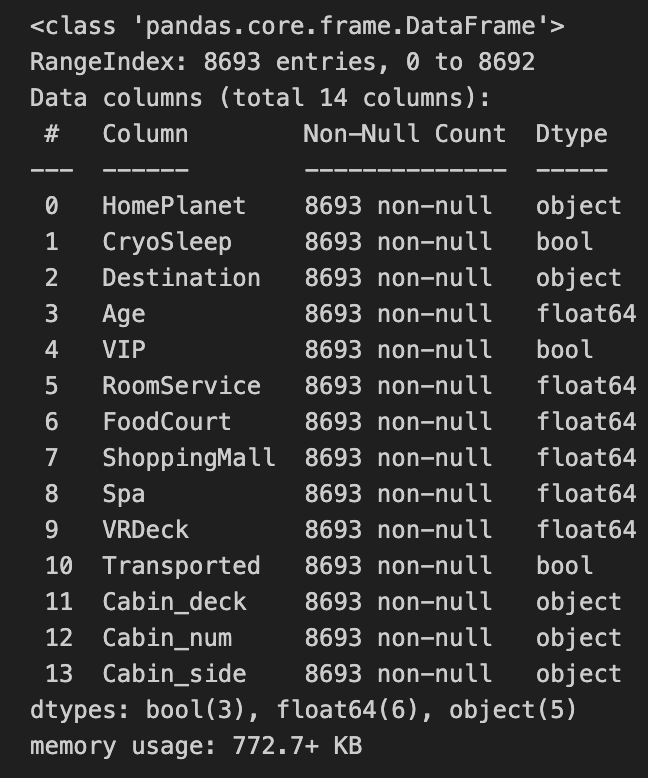
异常值处理
用箱线图可视化查看异常值
1 | features = ['Age', |
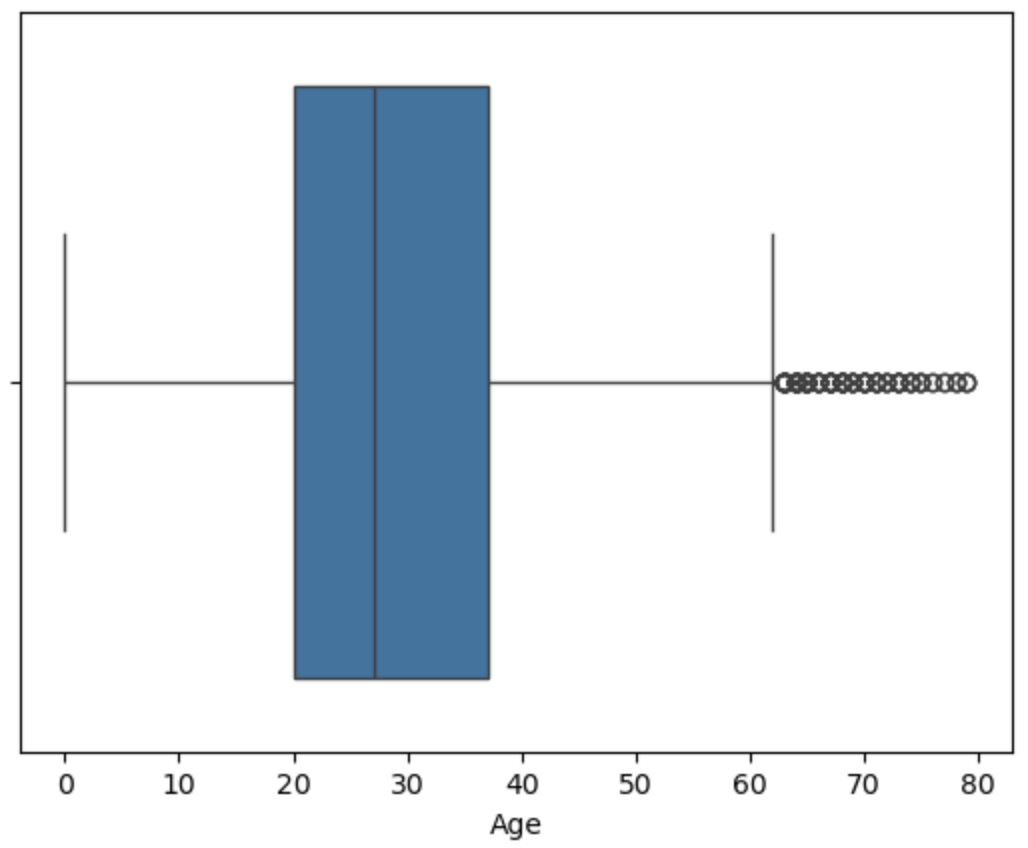
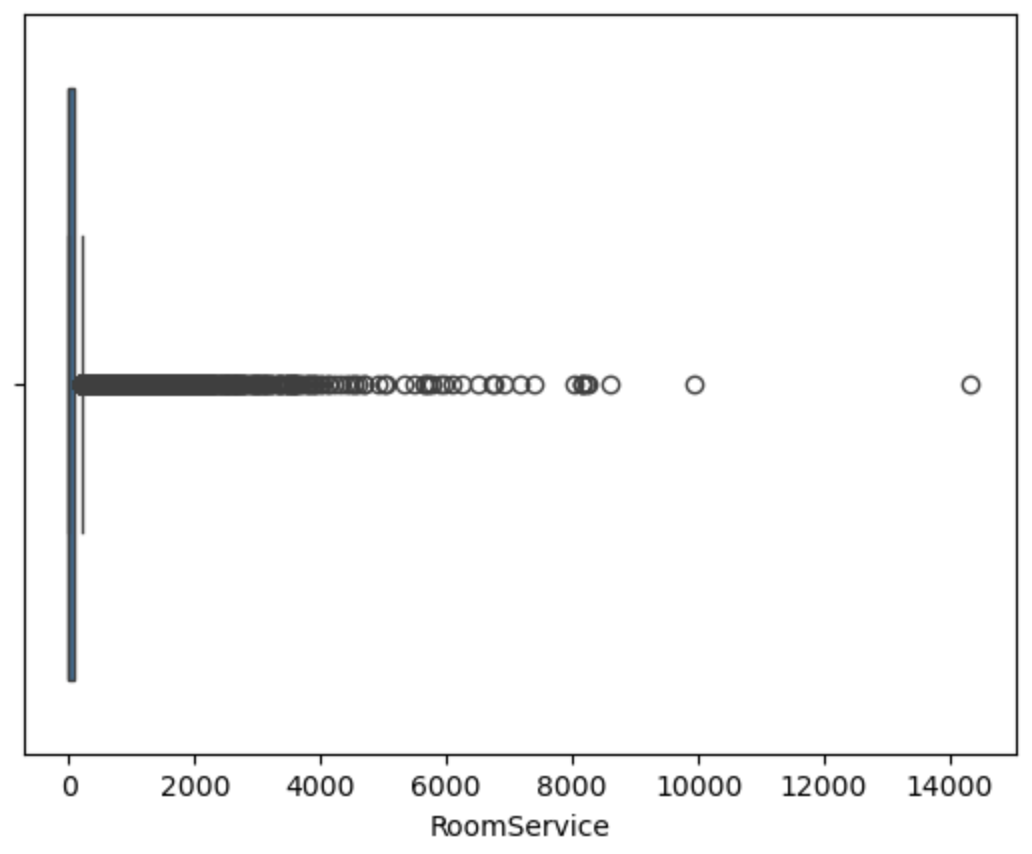
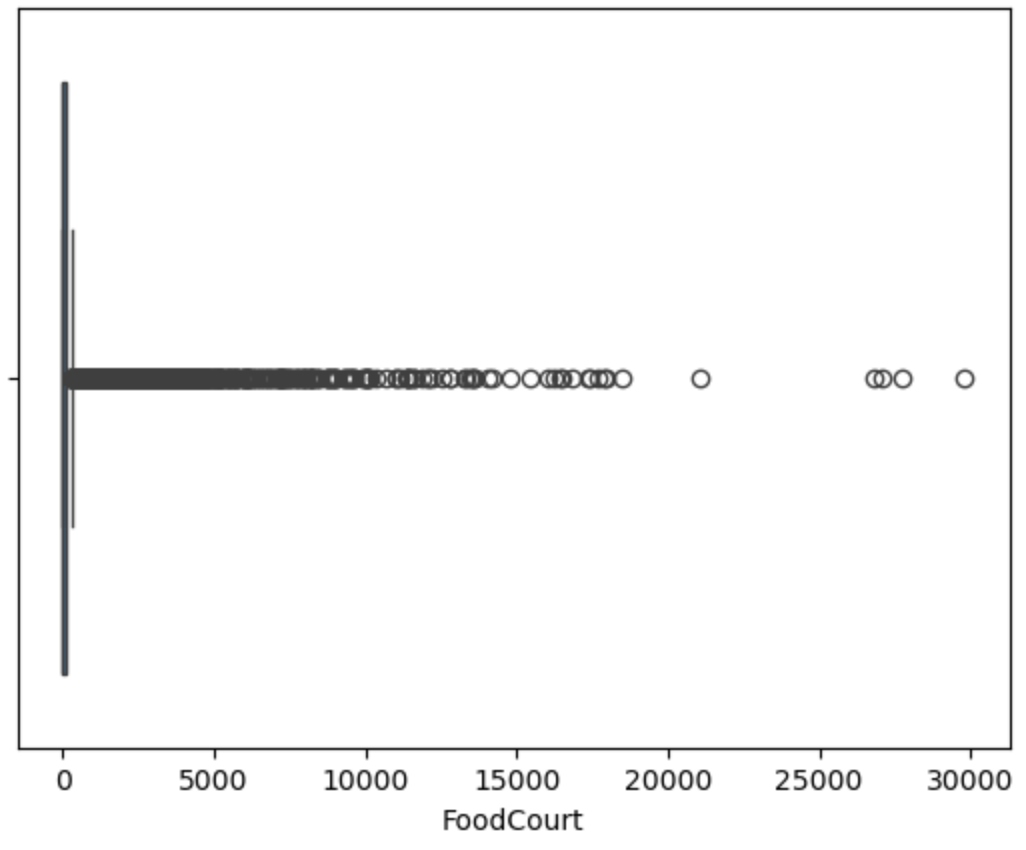
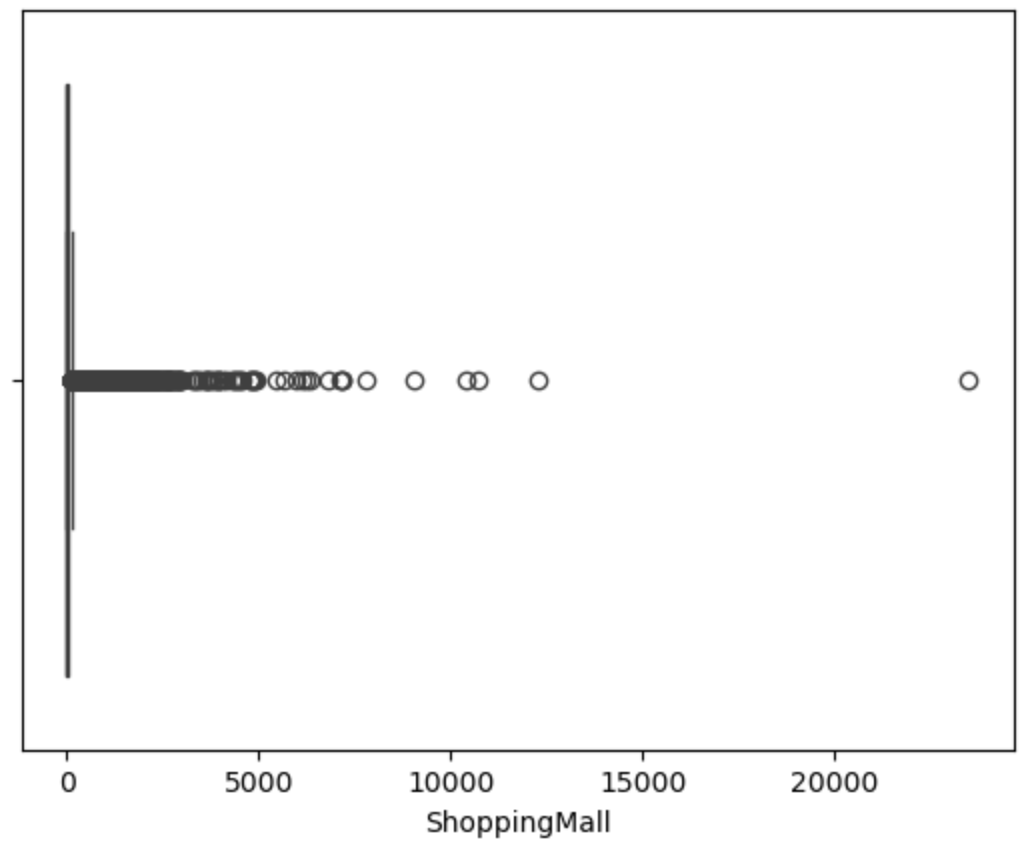
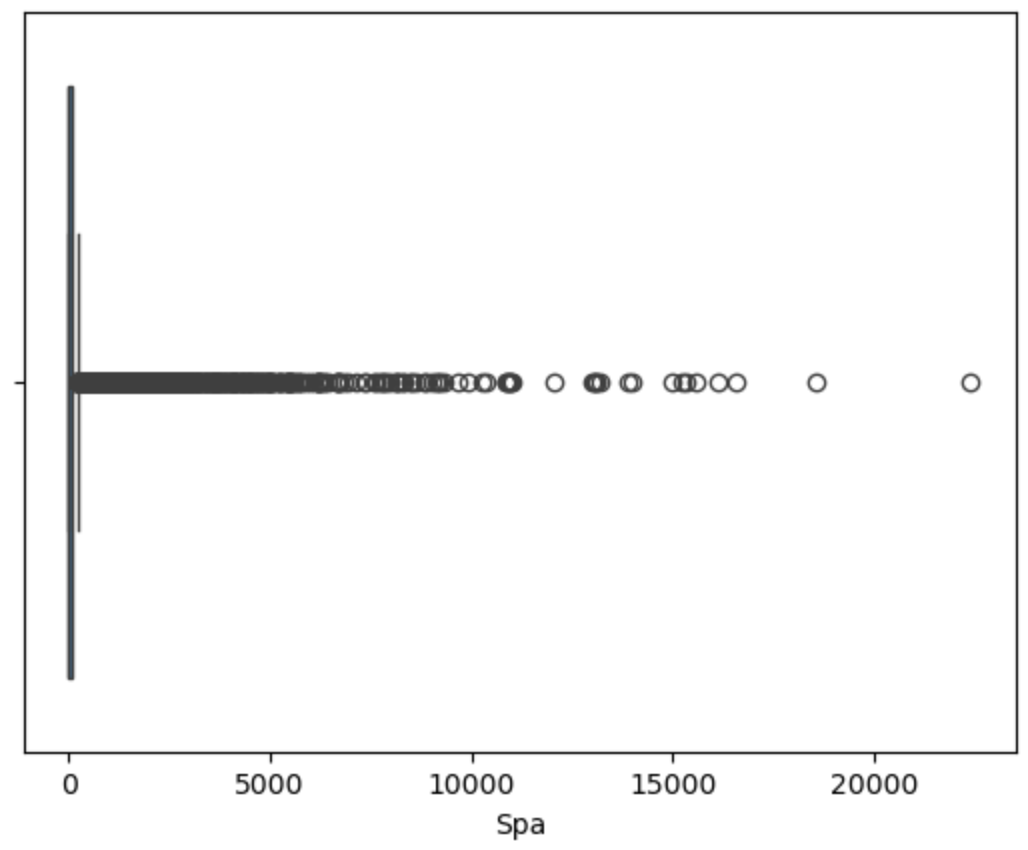
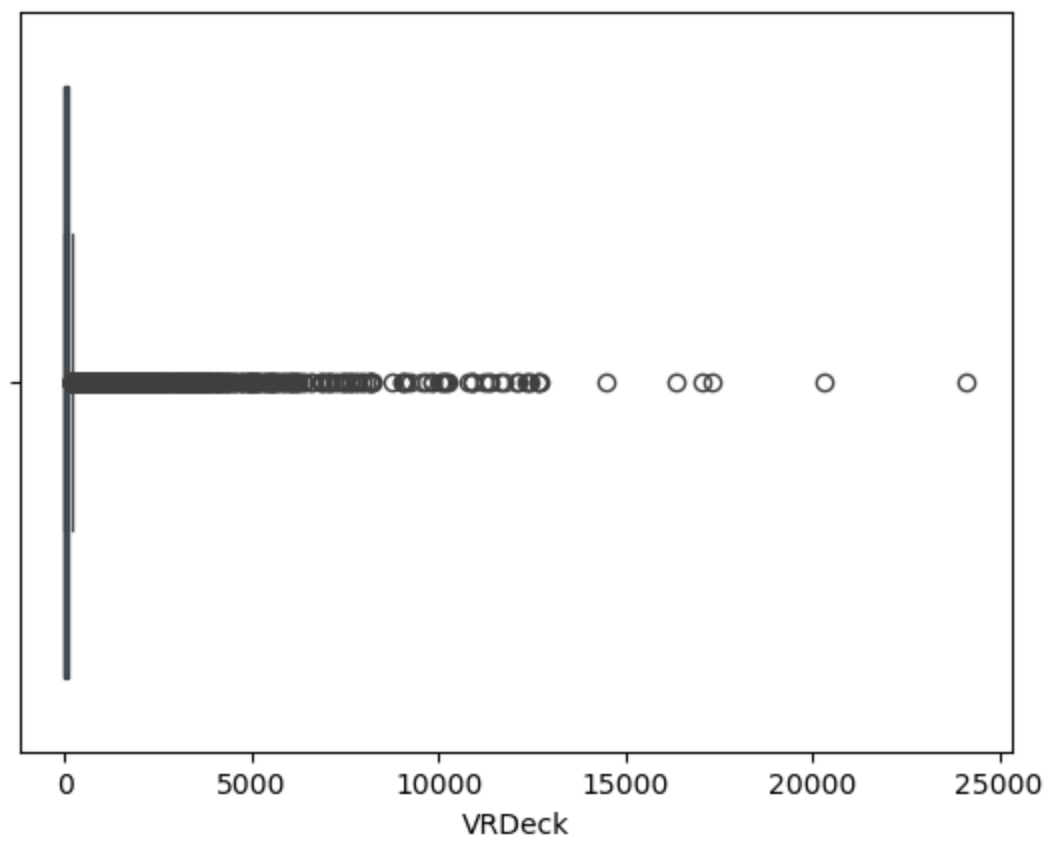
对异常值进行处理
1 | features = [ 'RoomService', |
1 | Q1 = df['Age'].quantile(0.25) |
1 | features = ['Age', |
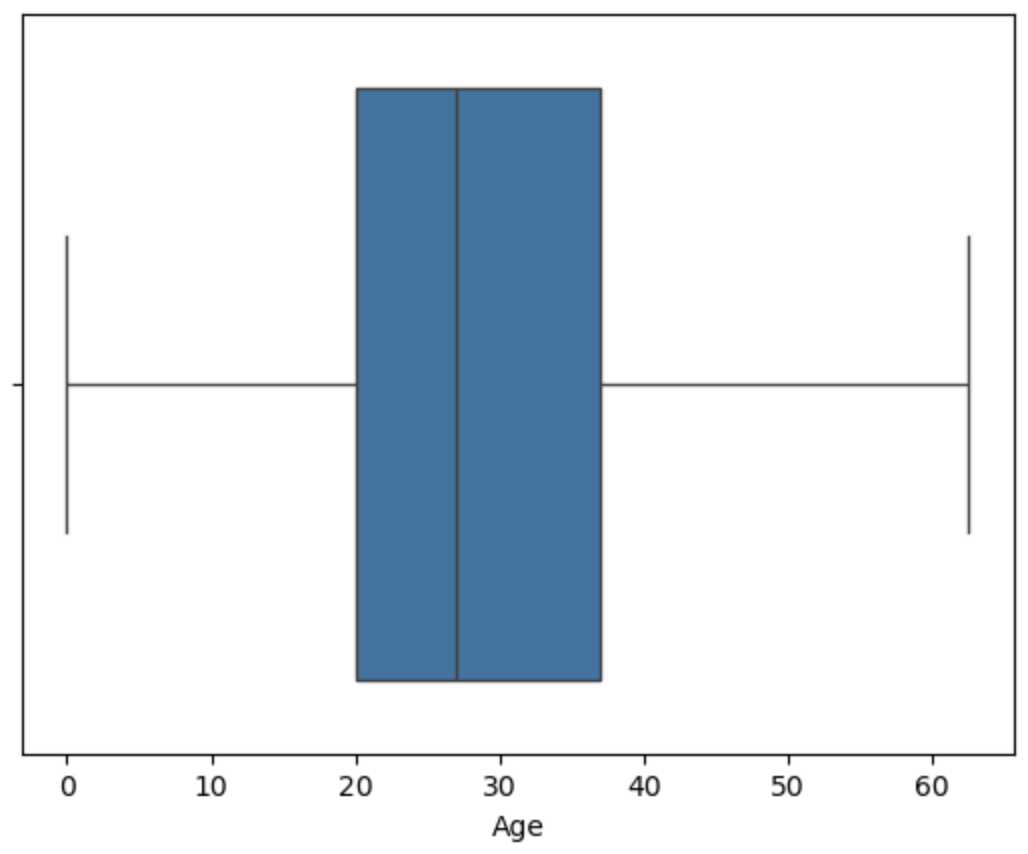
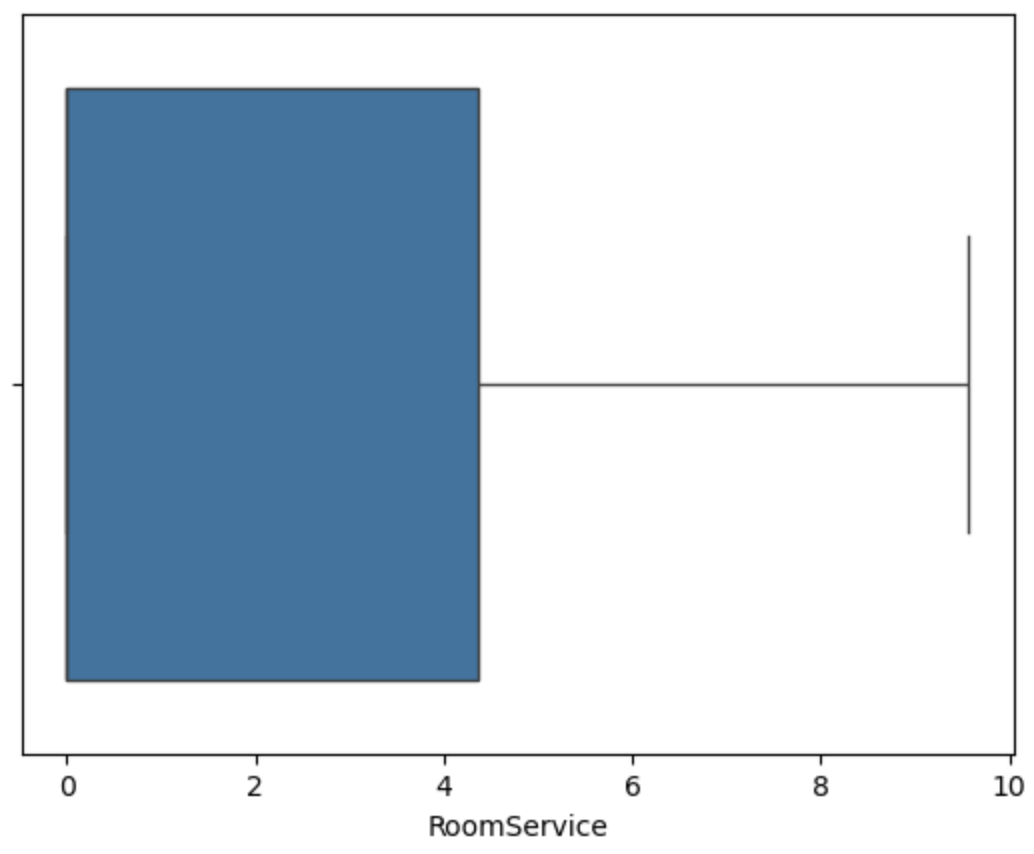
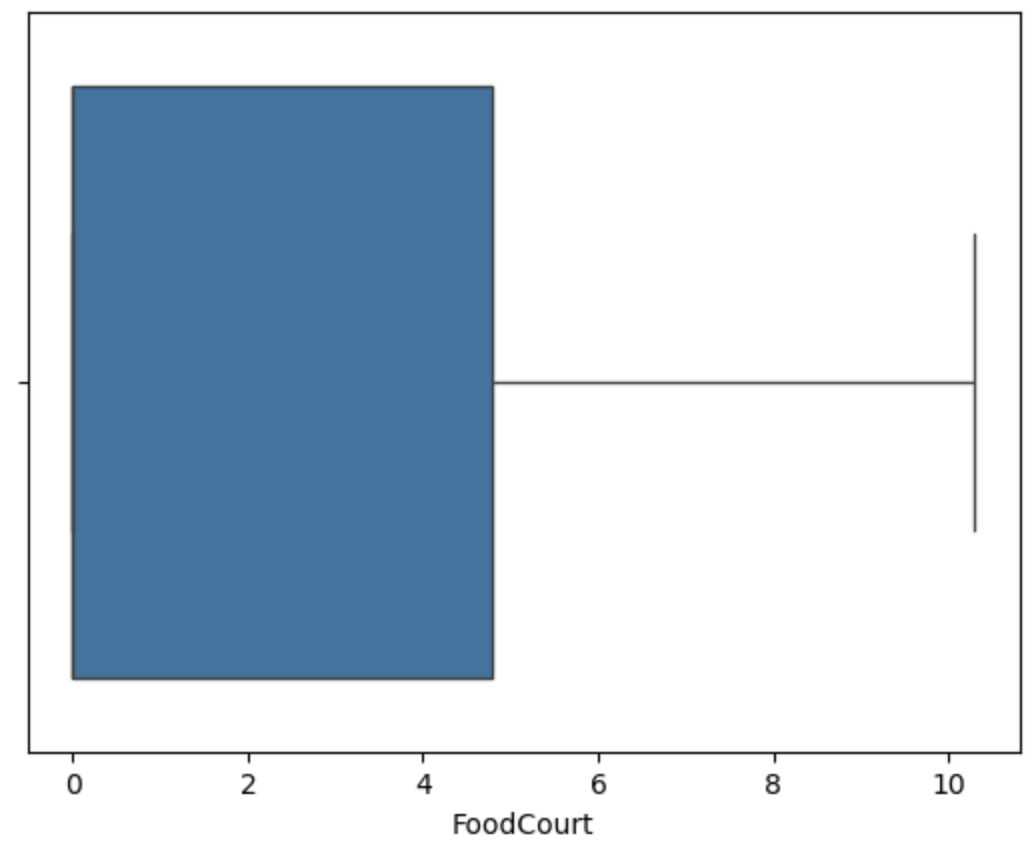
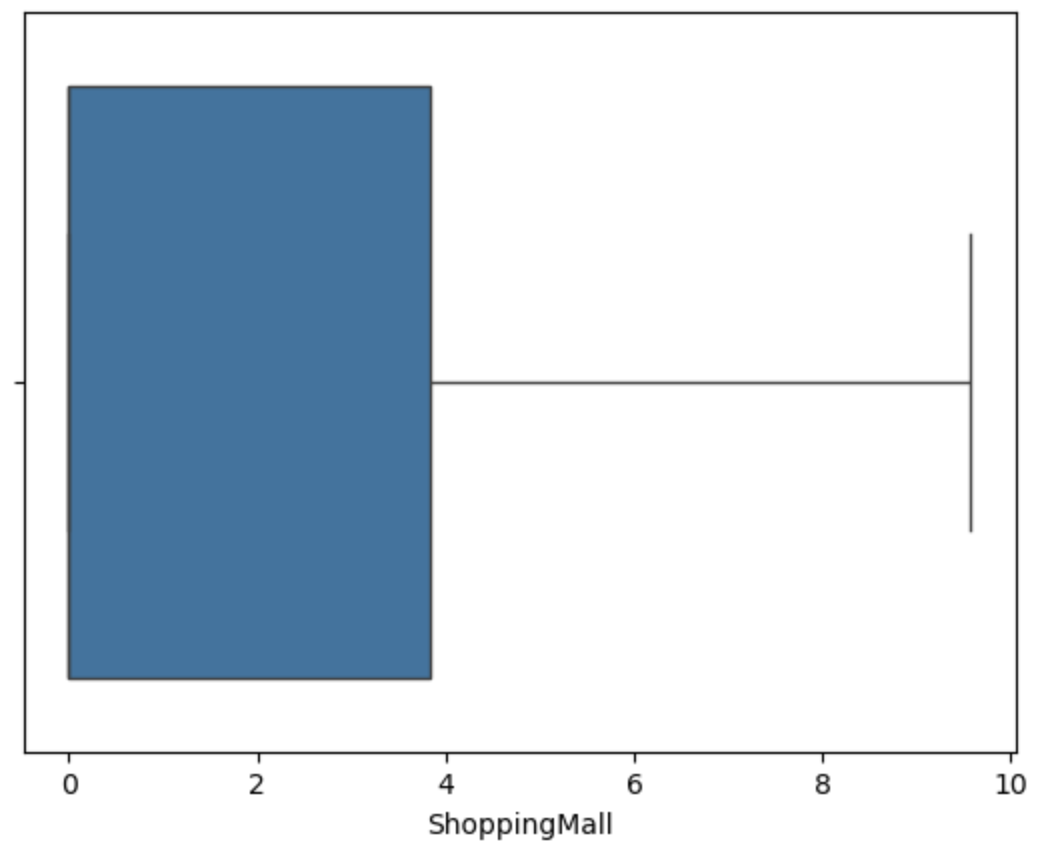
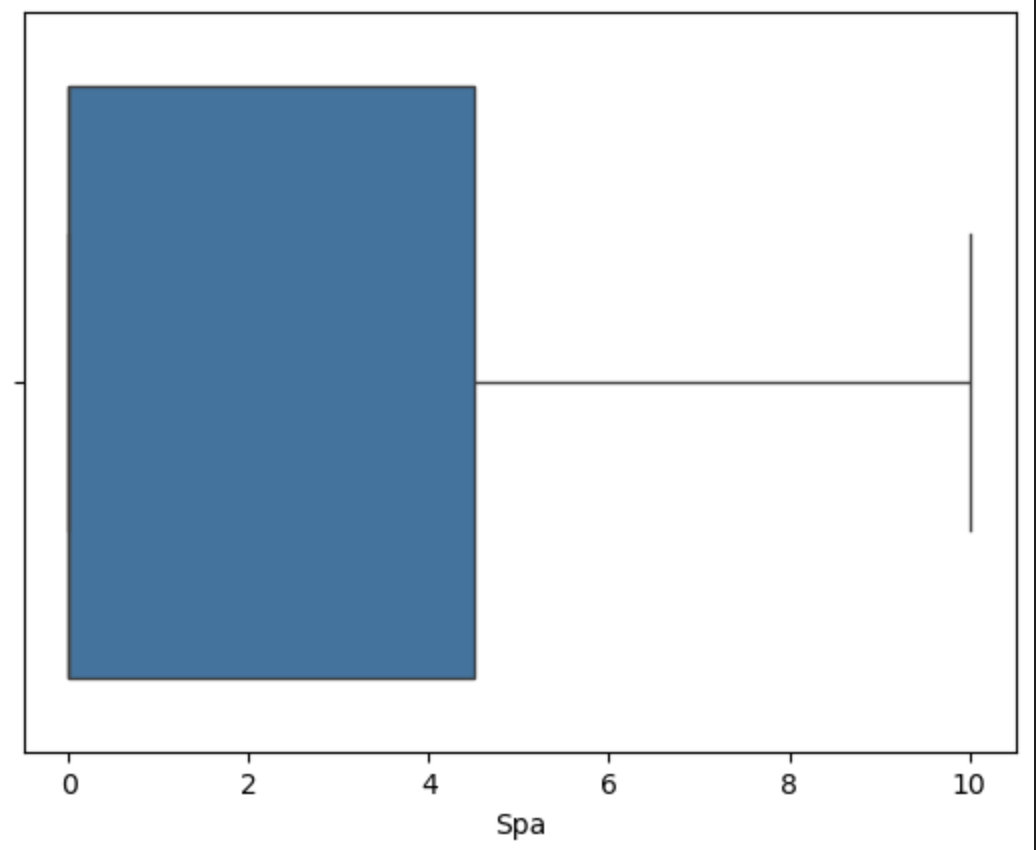
可视化分析
1 | features = ['HomePlanet', 'CryoSleep', 'Destination', |
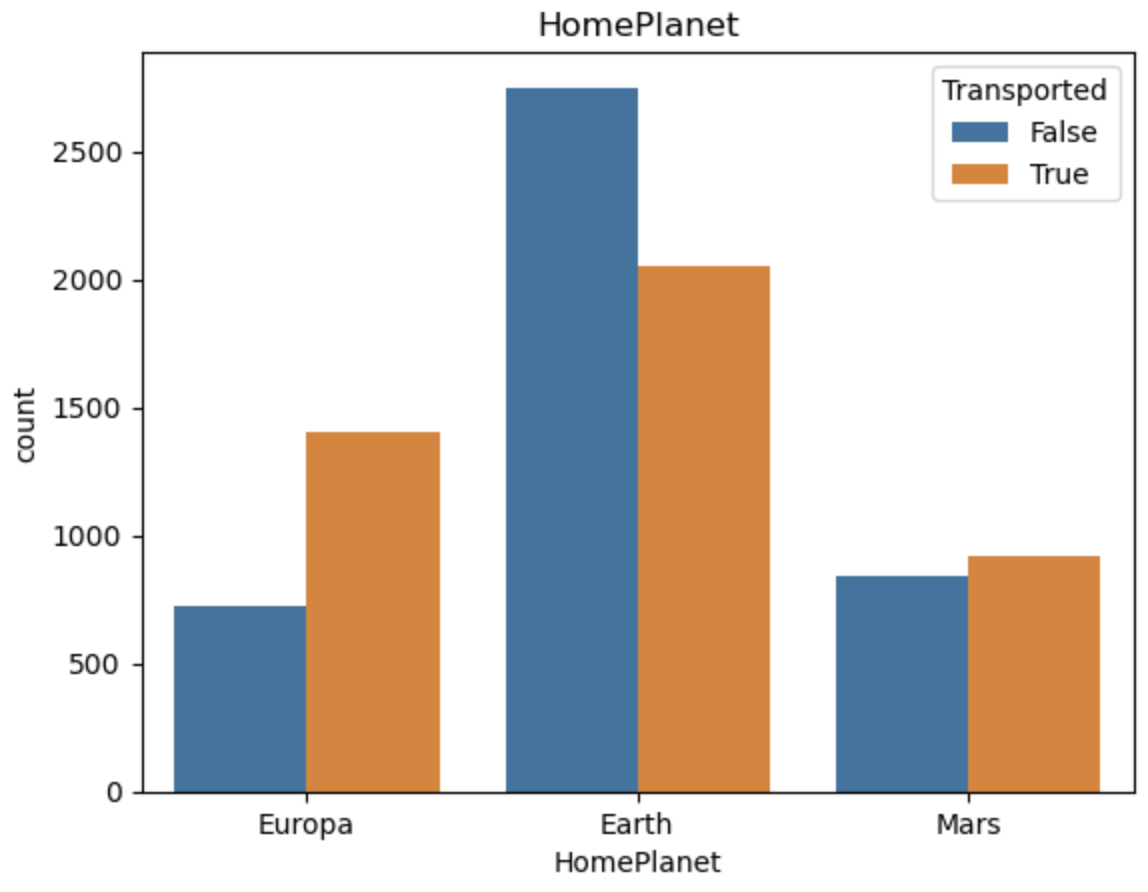
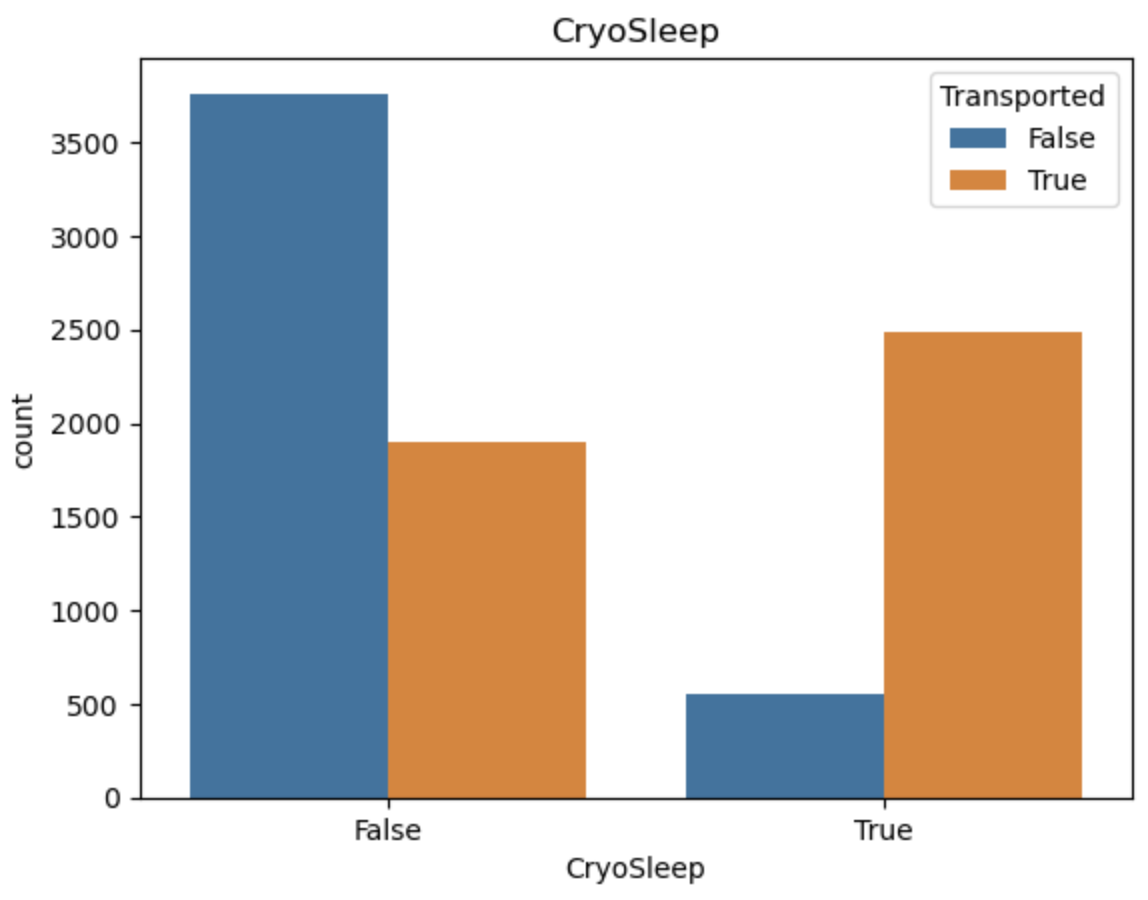
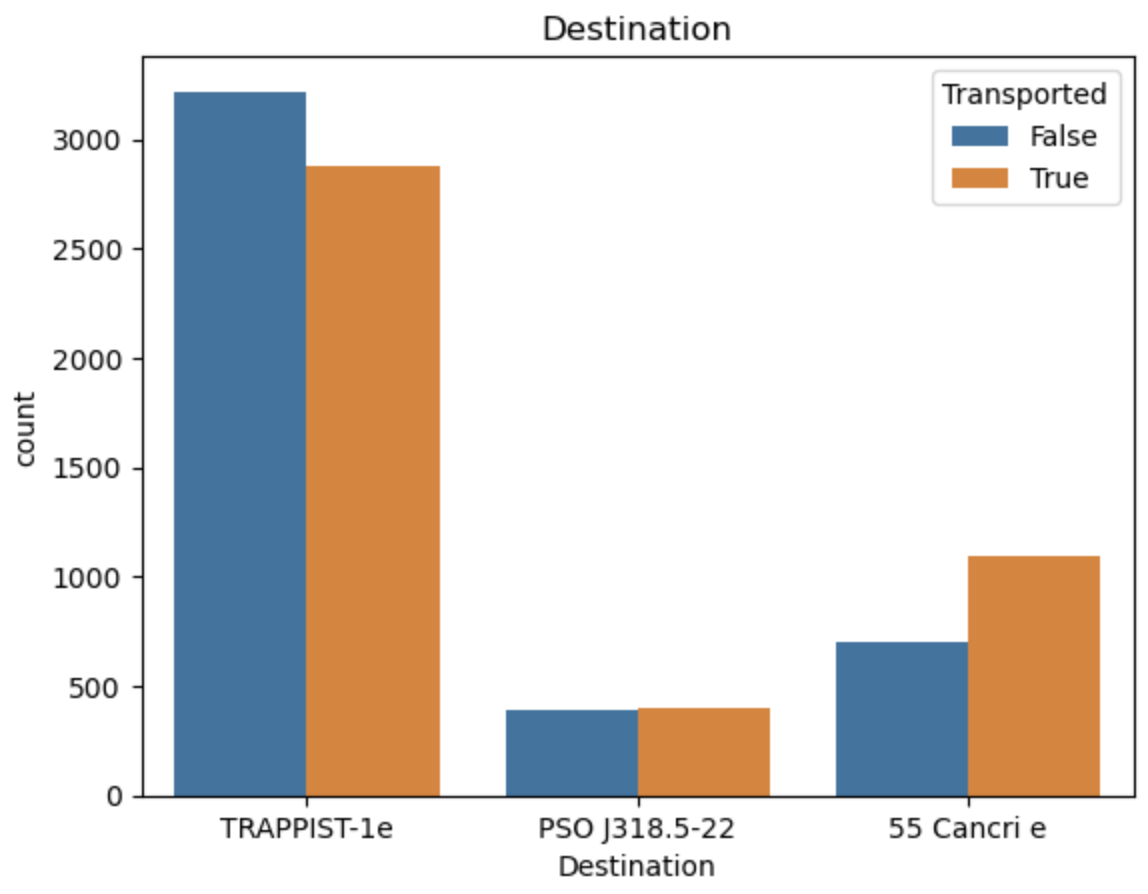
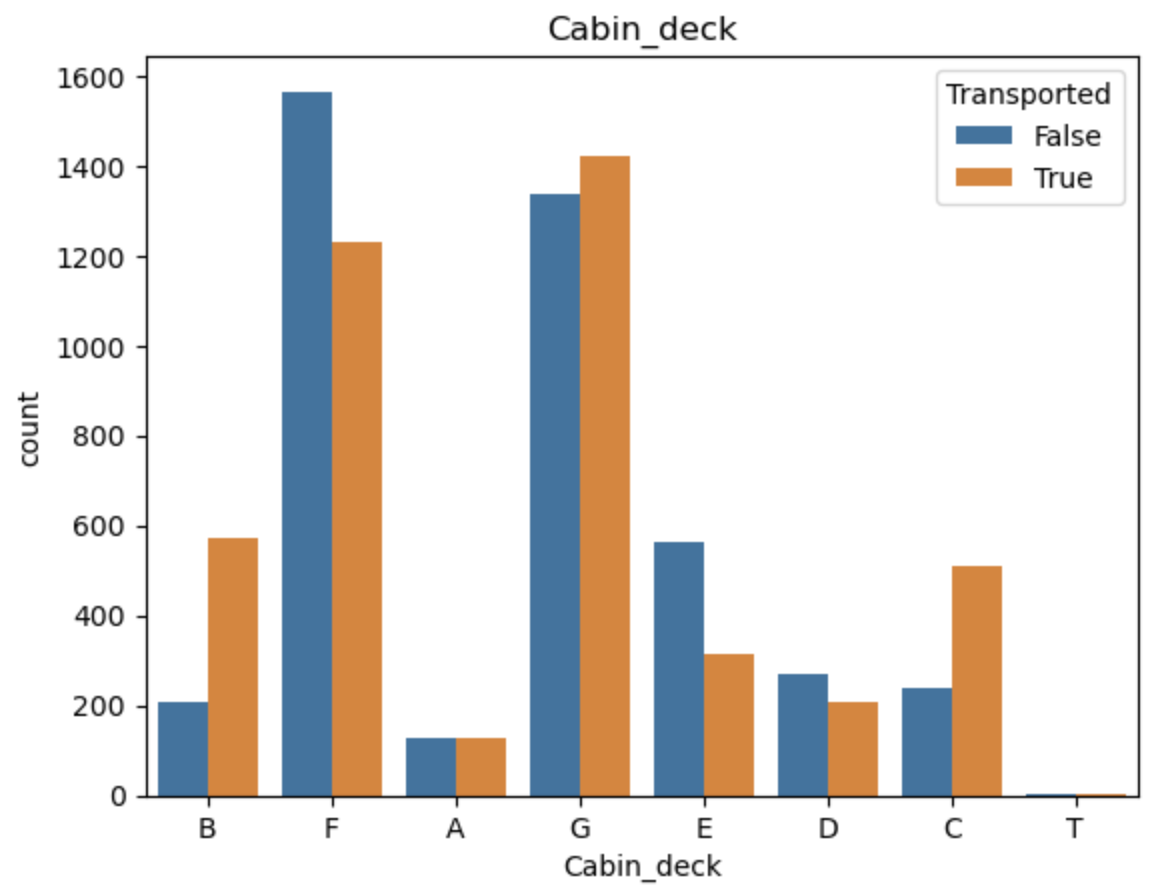
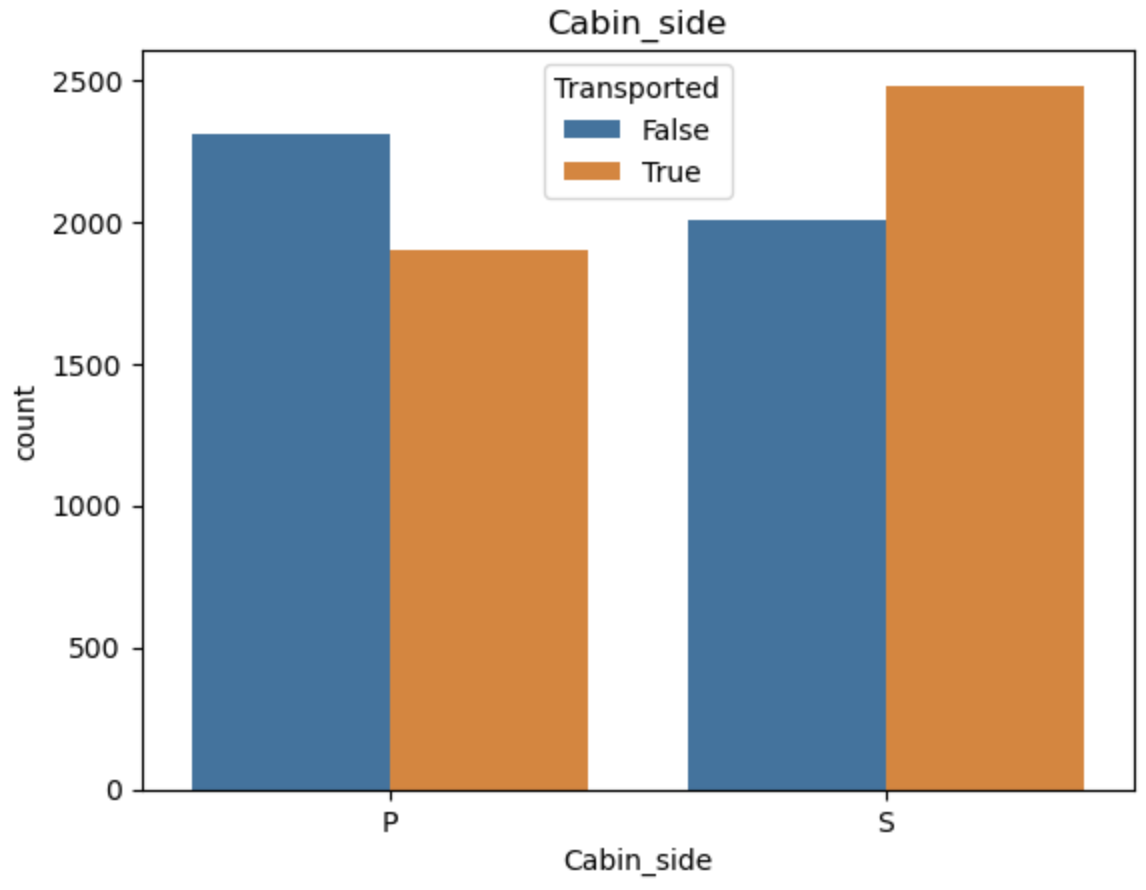
特征编码
1 | from sklearn.preprocessing import OneHotEncoder |
1 | df_cleaned_encoded.drop(columns=['Cabin_num'], inplace=True) |
相关性矩阵
1 | y = df_cleaned_encoded['Transported'] |
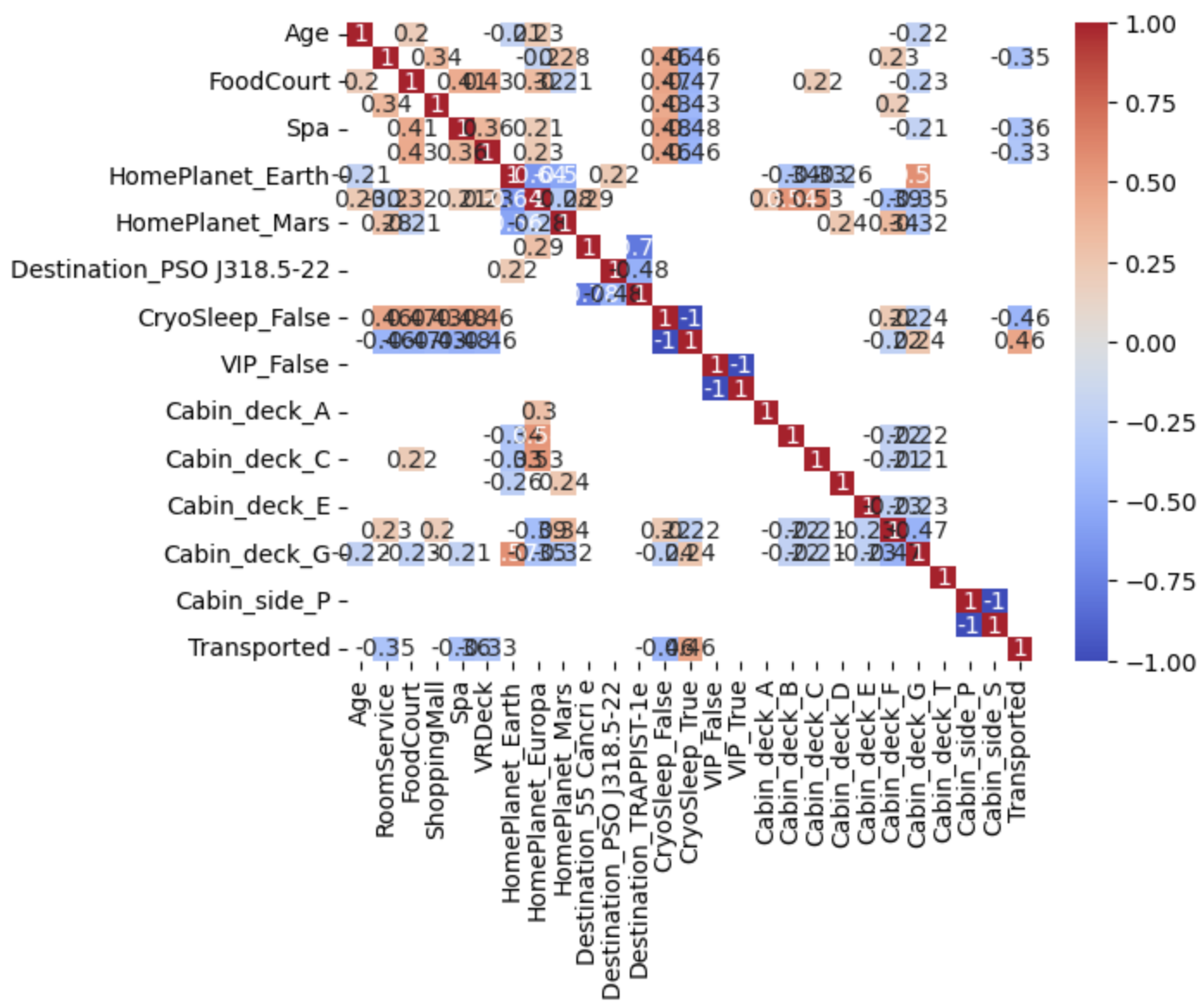
特征选择
1 | from sklearn.feature_selection import SelectKBest, chi2 |
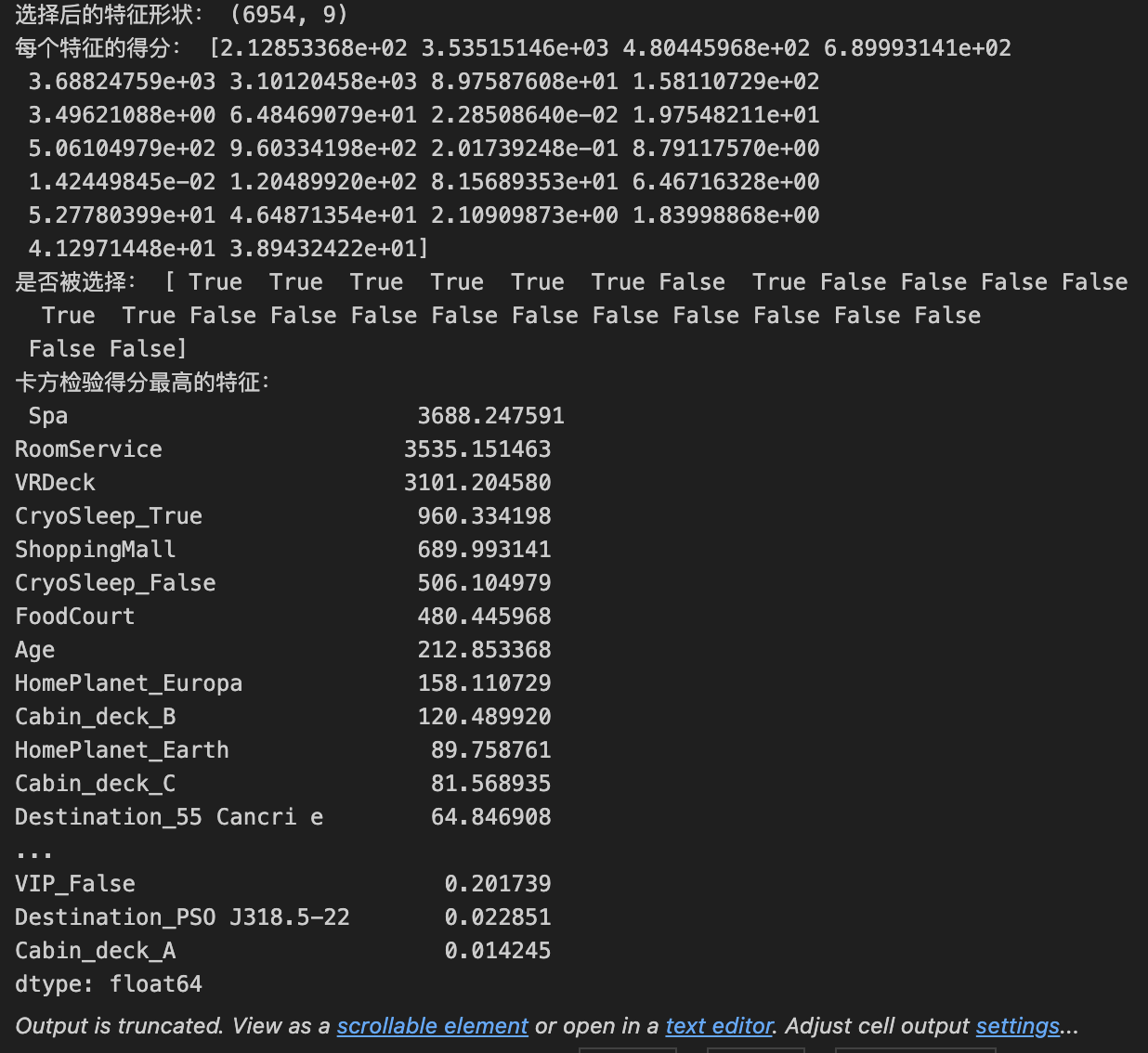
1 | print("卡方检验得分最低的特征:\n", scores.tail(15)) |
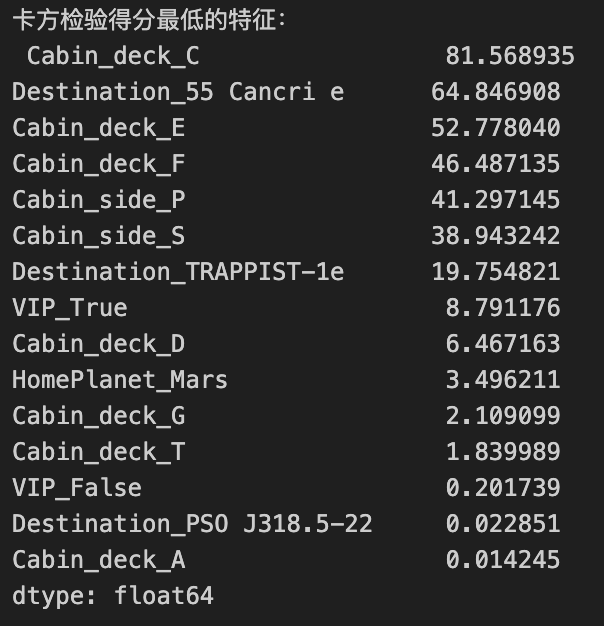
我们将特征分数较低的删除
1 | df_cleaned_encoded.drop(columns=[ |
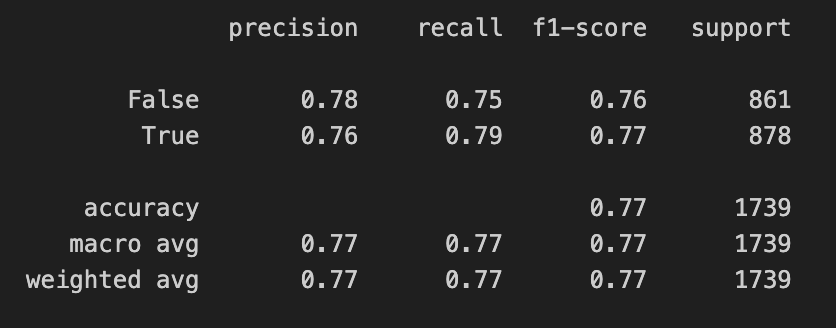
模型选择
1 | y = df_cleaned_encoded['Transported'] |
1 | from sklearn.ensemble import RandomForestClassifier |
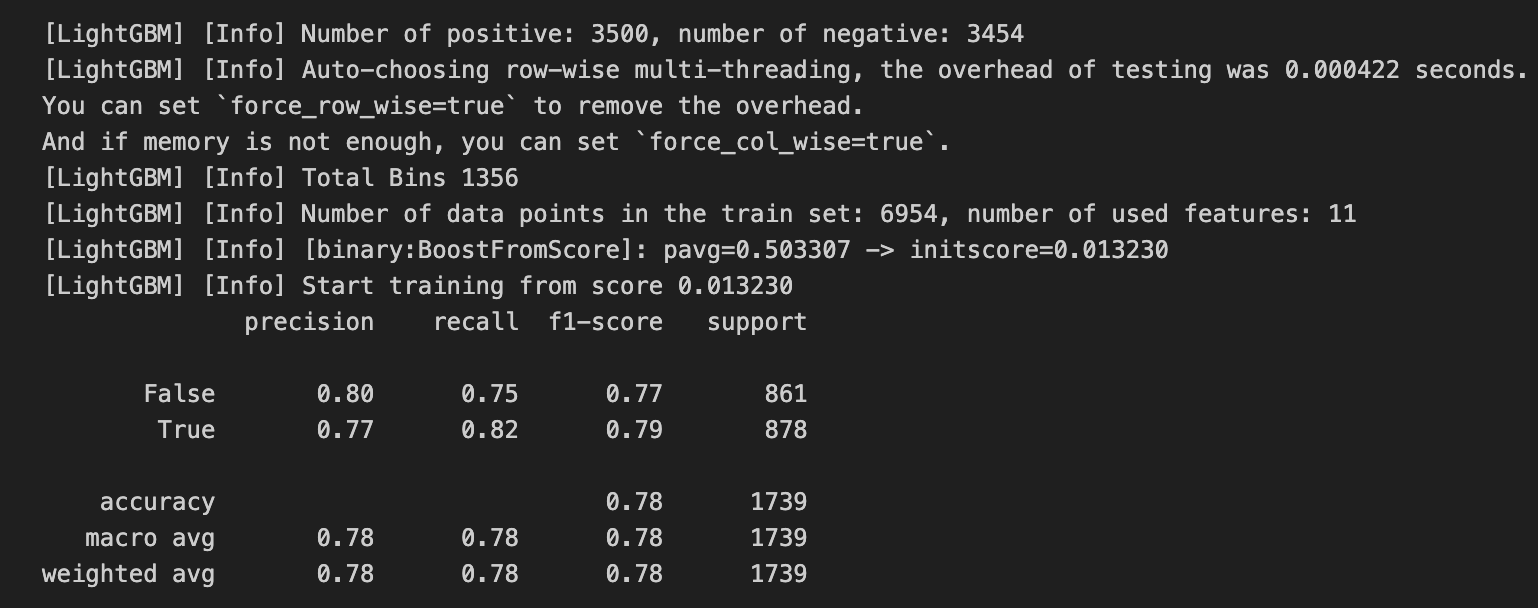
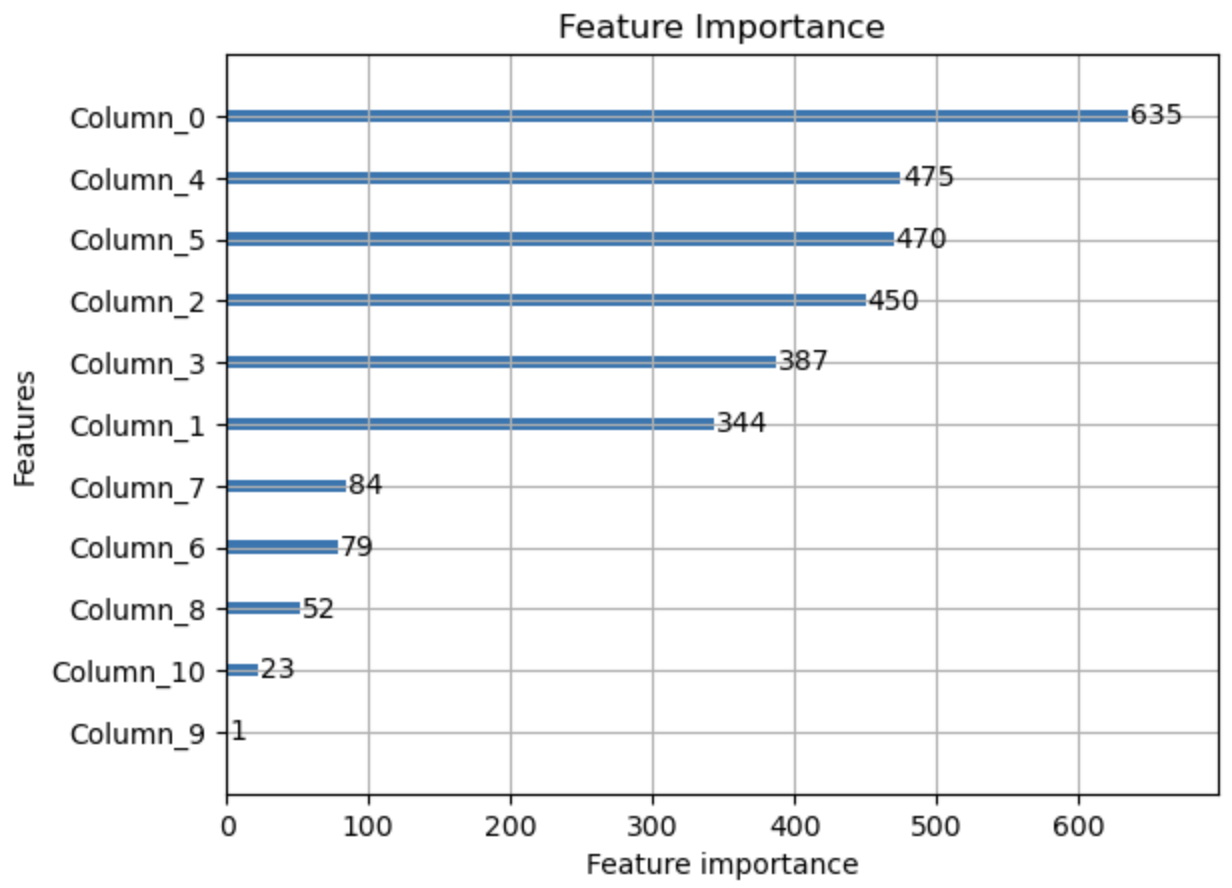
1 | import lightgbm as lgb |
混淆矩阵
1 | from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay |
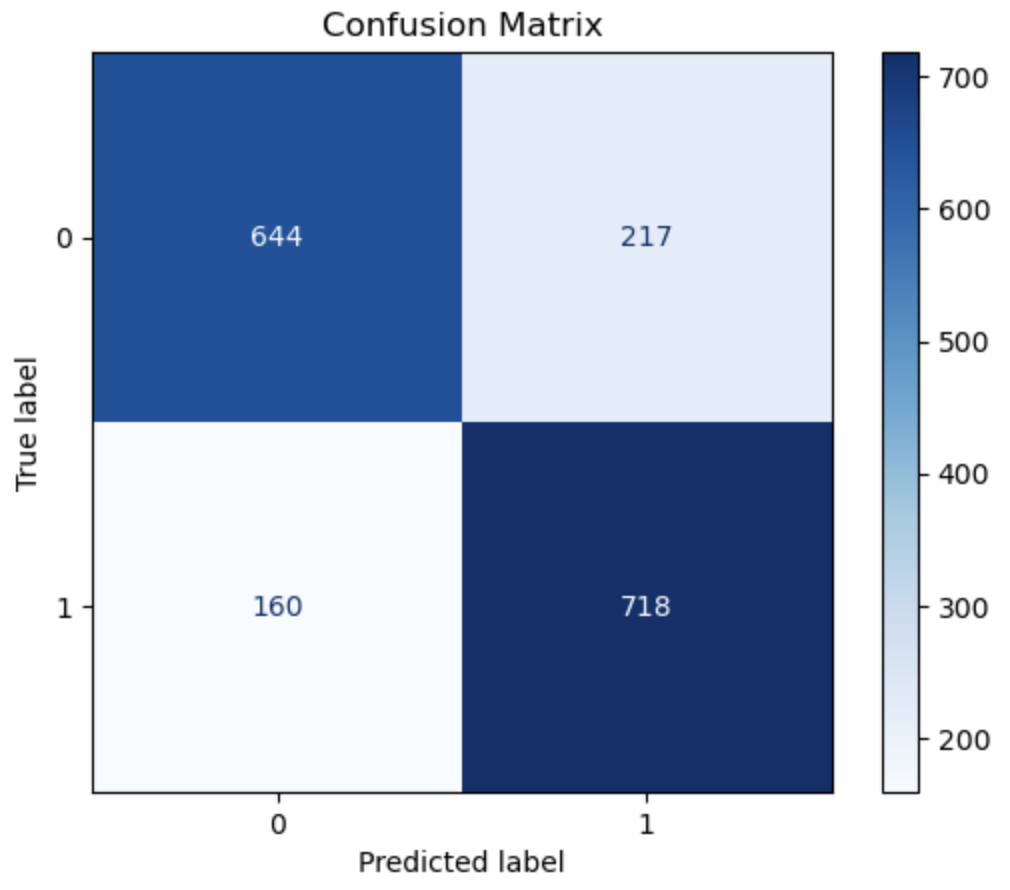
测试集预测
1 | #整理测试集 |
参考来源
chatGPT 4o
提问的问题:
- 我有一份数据 其中的一个特征内容为:B/0/P 这种形式 如何将这一组数据以“/”拆分成三列特征
- bool类型的数据怎么处理
- bool类型要转换为数值型吗
- 我想查看类别型与target之间的关系
- 在数据分析时 我有一列是类别型 但是这一列的内容是数字 如何将其转换为数值型
- 如何将object类型添加到相关性矩阵查看其相关性
- 分类问题选择哪个模型好 GBDT怎么样
- 如何用这个模型来预测测试集
- 就是说我要重新把测试集也像训练集一样进行处理吗
- 假设我有两列叫id和pred 我如何将其保存到一个新的csv文件中
- 代码问题:
1 | ValueError: Classification metrics can't handle a mix of continuous-multioutput and binary targets |
1 | import lightgbm as lgb |
1 | ValueError Traceback (most recent call last) |
1 | TypeError Traceback (most recent call last) |
1 | 这个是用RandomForestClassifier |
kaggle地址
我的此项目的kaggle网址:
https://www.kaggle.com/code/super213/randomforest-gbdt-f1-0-77
- Title: Spaceship Titanic
- Author: 姜智浩
- Created at : 2025-04-18 11:45:14
- Updated at : 2025-04-18 21:26:55
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/04/18/20250418Spaceship Titanic/
- License: This work is licensed under CC BY-NC-SA 4.0.