成人抑郁症数据分析

数据来源
https://www.kaggle.com/datasets/sonawanelalitsunil/adult-depression-lghc-indicator/data
成人抑郁症
成人抑郁症(LGHC 指标)数据集提供了由地方健康地理比较 (LGHC) 计划跟踪的成人抑郁症患病率的见解。它可作为了解不同人群和地区心理健康趋势的公共卫生资源。
主要特点:
健康指标:根据健康调查的自我报告数据,关注被诊断患有抑郁症的成年人的百分比。
人口统计和地理:按年龄、性别、种族/民族、收入水平和地理位置(州、县或地方区域)细分数据。
目标
- 对数据集进行探索性分析,找出数据集中的问题。
- 对数据进行预处理,包括缺失值处理、异常值处理、数据类型转换等。
- 对数据进行可视化分析,找出数据中的规律。
- 对数据进行分析,找出数据中的规律并预测抑郁症的概率。
过程
导入库
1 | import pandas as pd |
读取文件
1 | df = pd.read_csv('adult-depression-lghc-indicator-24.csv') |
查看文件
1 | df.head() |
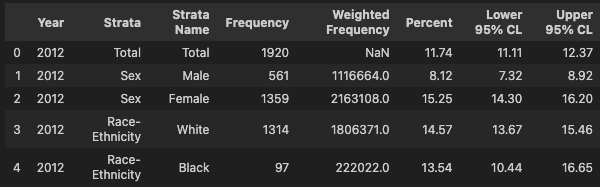
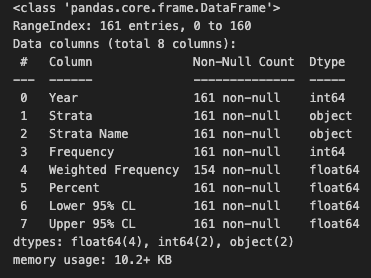
1 | df.info() |
分析每个字段的含义
Year:数据收集年份Strata:包含了各种类别Strata Name:不同类别的详细名称Frequency:频率Weighted Frequency:权重频率Percent:患病百分比 – targetLower 95% CL:较低的 95% CLUpper 95% CL:较高的 95% CL
针对Strata
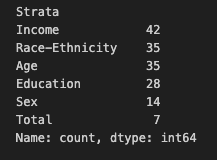
1 | df['Strata'].value_counts() |
数据可视化
1 | x = df['Year'] |
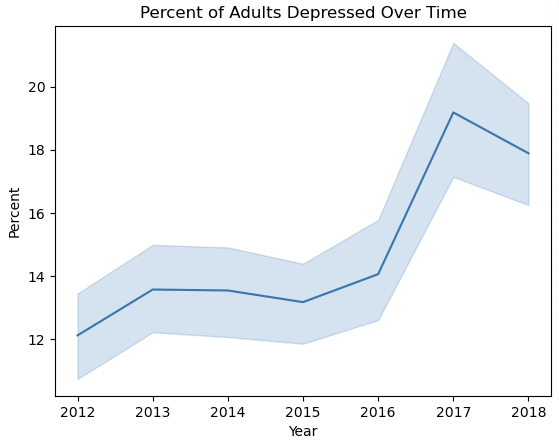
可以看到 抑郁症发病率在逐年上升 在2017年达到了最高值
1 | Strata_features = ['Income', 'Race-Ethnicity', 'Age', 'Education', 'Sex'] |
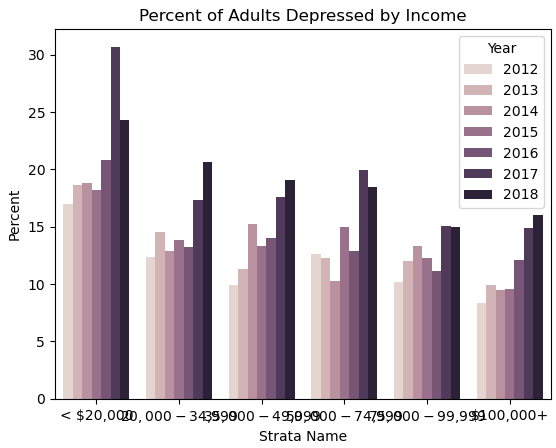
可以看到 收入小于$20,000的人得抑郁症的概率高于其他收入水平
可能的原因:低收入水平的人可能面临经济困难和压力,从而增加了他们对抑郁的感知和应对的难度。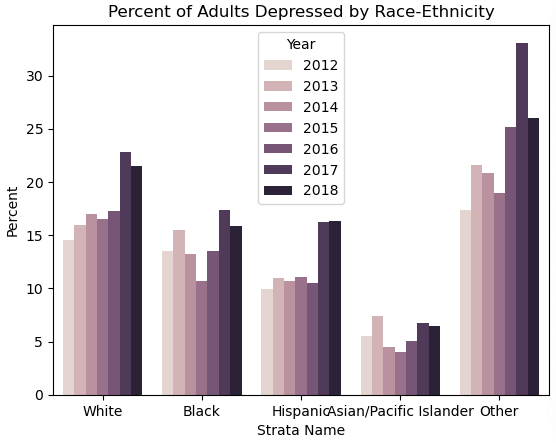
可以看到 亚非裔的人得抑郁症的概率低于其他种族和民族
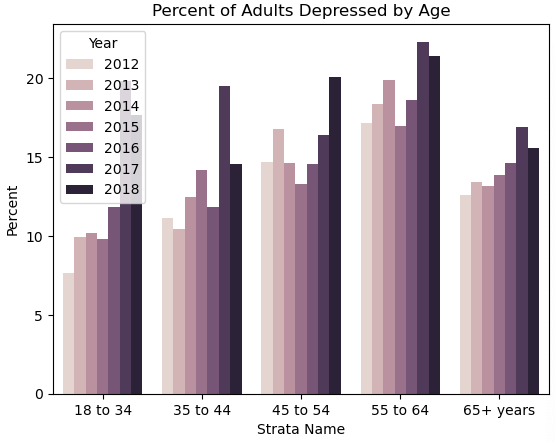
可以看到 随着年龄的增长 得抑郁症的概率也在增长 在65岁以上时又减小
可能的原因:随着年龄的增长 人们的生活和工作环境也在不断变化 压力也越来越大 因此也会增加得抑郁症的概率 在65岁以上时 人们已经退休了 没有了生活和工作的压力 因此也会减少得抑郁症的概率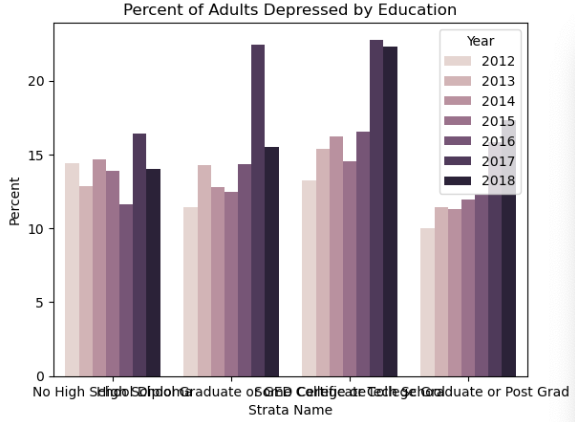
可以看到 学历对得抑郁症的概率没有明显影响
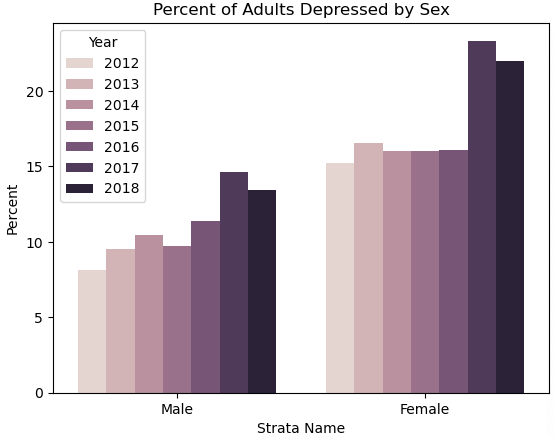
可以看到 女性得抑郁症的概率高于男性
男女性得抑郁症的概率都逐年上升 在2017年达到最高
1 | plt.scatter(df['Lower 95% CL'], df['Percent']) |
1 | plt.scatter(df['Upper 95% CL'], df['Percent']) |
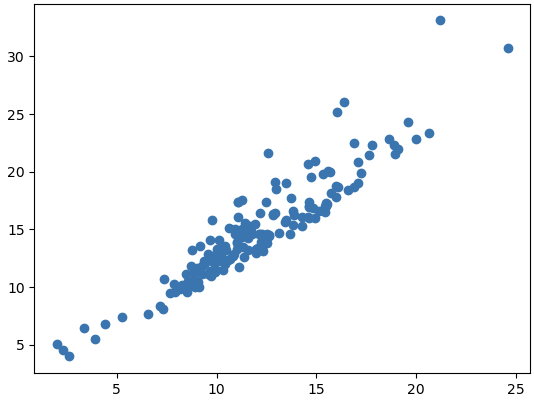
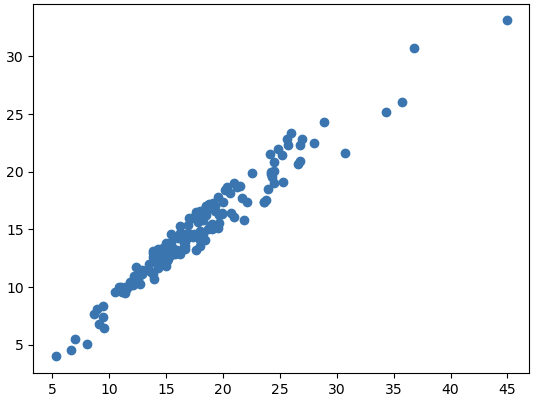
上述两张散点图可以看到 Upper 95% CL和 Lower 95% CL 对得抑郁症的影响很大
用相关性矩阵查看特征之间的关系
1 | num_df = df.select_dtypes(include=[np.number]) |
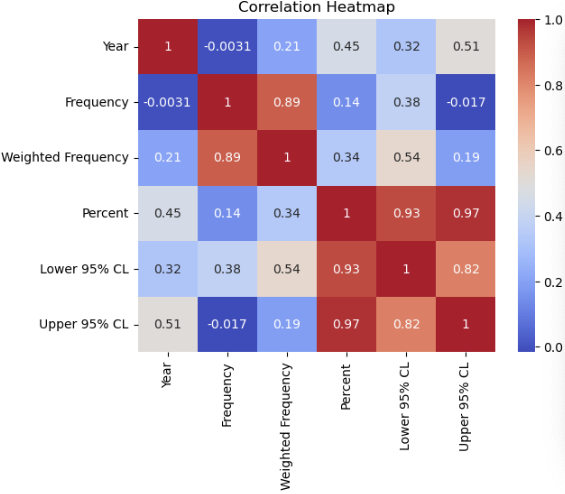
数据预处理
1 | df.drop(columns=['Strata Name', 'Strata'], inplace=True) |
1 | df.isnull().sum() |
Year 0
Frequency 0
Weighted Frequency 7
Percent 0
Lower 95% CL 0
Upper 95% CL 0
dtype: int64
由于只有7个缺失值 所以直接删除
1 | df.dropna(inplace=True) |
1 | # 计算 Z-Score |
异常值:
Year Frequency Weighted Frequency Percent Lower 95% CL Upper 95% CL
2 2012 1359 2163108.0 15.25 14.30 16.20
3 2012 1314 1806371.0 14.57 13.67 15.46Z-Score2 3.498507
3 3.339020
1 | from scipy.stats import mstats |
胜率变换后的数据:
Year Frequency Weighted Frequency Percent Lower 95% CL Upper 95% CL
1 2012 561 1116664.0 8.12 7.32 8.92
2 2012 1359 2163108.0 15.25 14.30 16.20
3 2012 1314 1806371.0 14.57 13.67 15.46
4 2012 97 222022.0 13.54 10.44 16.65
5 2012 412 923174.0 9.98 8.91 11.05
.. … … … … … …
156 2018 496 1623933.0 17.69 13.72 21.66
157 2018 285 749615.0 14.56 10.91 18.21
158 2018 301 1052945.0 20.06 15.60 24.52
159 2018 432 854201.0 21.44 17.65 25.23
160 2018 450 661974.0 15.60 13.42 17.78Z-Score Frequency_winsorized1 0.670280 561
2 3.498507 1055
3 3.339020 1055
4 -0.974202 97
5 0.142203 412
.. … …
156 0.439911 496
157 -0.307903 285
158 -0.251197 301
159 0.213086 432
160 0.276880 450[154 rows x 8 columns]
就是将第2,3行的一场数据进行了胜率变换 其他行数据没有变化
1 | X = df.drop(columns=['Percent', 'Z-Score', 'Frequency']) |
模型选择
1 | lr = LinearRegression() |
模型评估
1 | mse = mean_squared_error(y_test, y_pred) |
Linear Regression MSE: 1.439819098234569e-05
Linear Regression R^2: 0.999999015347916
决定系数为0.99以上 说明模型拟合得很好
- Title: 成人抑郁症数据分析
- Author: 姜智浩
- Created at : 2025-04-14 11:45:14
- Updated at : 2025-04-18 21:28:17
- Link: https://super-213.github.io/zhihaojiang.github.io/2025/04/14/20250414成人抑郁症数据分析/
- License: This work is licensed under CC BY-NC-SA 4.0.